一 什么是 RPC?
RPC 是指远程过程调用,也就是说两台服务器 A,B 一个应用部署在 A 服务器上,想要调用 B 服务器上应用提供的函数或方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
二 RPC 是如何通讯的?

- 要解决通讯的问题,主要是通过在客户端和服务器之间建立 TCP 连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
- 要解决寻址的问题,也就是说,A 服务器上的应用怎么告诉底层的 RPC 框架,如何连接到 B 服务器(如主机或 IP 地址)以及特定的端口,方法的名称是什么,这样才能完成调用。比如基于 Web 服务协议栈的 RPC,就要提供一个 endpoint URI,或者是从 UDDI 服务上查找。如果是 RMI 调用的话,还需要一个 RMI Registry 来注册服务的地址。
- 当 A 服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如 TCP 传递到 B 服务器,由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制的形式,也就是序列化(Serialize)或编组(marshal),通过寻址和传输将序列化的二进制发送给 B 服务器。
- B 服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式,然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。
- 返回值还要发送回服务器 A 上的应用,也要经过序列化的方式发送,服务器 A 接到后,再反序列化,恢复为内存中的表达方式,交给 A 服务器上的应用。
三 为什么要用 RPC?
就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如比如不同的系统间的通讯,甚至不同的组织间的通讯。由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用
四 常见RPC框架
| 功能 | Hessian | Montan | rpcx | gRPC | Thrift | Dubbo | Dubbox | Spring Cloud |
|---|---|---|---|---|---|---|---|---|
| 开发语言 | 跨语言 | Java | Go | 跨语言 | 跨语言 | Java | Java | Java |
| 分布式(服务治理) | × | √ | √ | × | × | √ | √ | √ |
| 多序列化框架支持 | hessian | √(支持Hessian2、Json,可扩展) | √ | × 只支持protobuf) | ×(thrift格式) | √ | √ | √ |
| 多种注册中心 | × | √ | √ | × | × | √ | √ | √ |
| 管理中心 | × | √ | √ | × | × | √ | √ | √ |
| 跨编程语言 | √ | ×(支持php client和C server) | × | √ | √ | × | × | × |
| 支持REST | × | × | × | × | × | × | √ | √ |
| 关注度 | 低 | 中 | 低 | 中 | 中 | 中 | 高 | 中 |
| 上手难度 | 低 | 低 | 中 | 中 | 中 | 低 | 低 | 中 |
| 运维成本 | 低 | 中 | 中 | 中 | 低 | 中 | 中 | 中 |
| 开源机构 | Caucho | Apache | Apache | Alibaba | Dangdang | Apache |
实际场景中的选择
# Spring Cloud : Spring全家桶,用起来很舒服,只有你想不到,没有它做不到。可惜因为发布的比较晚,国内还没出现比较成功的案例,大部分都是试水,不过毕竟有Spring作背书,还是比较看好。
# Dubbox: 相对于Dubbo支持了REST,估计是很多公司选择Dubbox的一个重要原因之一,但如果使用Dubbo的RPC调用方式,服务间仍然会存在API强依赖,各有利弊,懂的取舍吧。
# Thrift: 如果你比较高冷,完全可以基于Thrift自己搞一套抽象的自定义框架吧。
# Montan: 可能因为出来的比较晚,目前除了新浪微博16年初发布的,
# Hessian: 如果是初创公司或系统数量还没有超过5个,推荐选择这个,毕竟在开发速度、运维成本、上手难度等都是比较轻量、简单的,即使在以后迁移至SOA,也是无缝迁移。
# rpcx/gRPC: 在服务没有出现严重性能的问题下,或技术栈没有变更的情况下,可能一直不会引入,即使引入也只是小部分模块优化使用。ZeroRPC和SimpleXMLRPCServer
一 Python中RPC框架
自带的:SimpleXMLRPCServer(数据包大,速度慢)
第三方:ZeroRPC(底层使用ZeroMQ和MessagePack,速度快,响应时间短,并发高),grpc(谷歌推出支持夸语言)
二 SimpleXMLRPCServer使用


from xmlrpc.server import SimpleXMLRPCServer class RPCServer(object): def __init__(self): super(RPCServer, self).__init__() print(self) self.send_data = 'lqz nb' self.recv_data = None def getObj(self): print('get data') return self.send_data def sendObj(self, data): print('send data') self.recv_data = data print(self.recv_data) # SimpleXMLRPCServer server = SimpleXMLRPCServer(('localhost',4242), allow_none=True) server.register_introspection_functions() server.register_instance(RPCServer()) server.serve_forever()
import time from xmlrpc.client import ServerProxy # SimpleXMLRPCServer def xmlrpc_client(): print('xmlrpc client') c = ServerProxy('http://localhost:4242') data = 'lqz nb' start = time.clock() for i in range(500): a=c.getObj() print(a) for i in range(500): c.sendObj(data) print('xmlrpc total time %s' % (time.clock() - start)) if __name__ == '__main__': xmlrpc_client()
三 ZeroRPC使用
import zerorpc class RPCServer(object): def __init__(self): super(RPCServer, self).__init__() print(self) self.send_data = 'lqz nb' self.recv_data = None def getObj(self): print('get data') return self.send_data def sendObj(self, data): print('send data') self.recv_data = data print(self.recv_data) # zerorpc s = zerorpc.Server(RPCServer()) s.bind('tcp://0.0.0.0:4243') s.run()
import zerorpc import time # zerorpc def zerorpc_client(): print('zerorpc client') c = zerorpc.Client() c.connect('tcp://127.0.0.1:4243') data = 'lqz nb' start = time.clock() for i in range(500): a=c.getObj() print(a) for i in range(500): c.sendObj(data) print('total time %s' % (time.clock() - start)) if __name__ == '__main__': zerorpc_client()
一 消息队列介绍
1.1 介绍
消息队列就是基础数据结构中的“先进先出”的一种数据机构。想一下,生活中买东西,需要排队,先排的人先买消费,就是典型的“先进先出”

1.2 MQ解决什么问题
MQ是一直存在,不过随着微服务架构的流行,成了解决微服务之间问题的常用工具。
应用解耦
以电商应用为例,应用中有订单系统、库存系统、物流系统、支付系统。用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常。
当转变成基于消息队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。当物流系统恢复后,继续处理订单信息即可,中单用户感受不到物流系统的故障。提升系统的可用性

流量消峰
举个栗子,如果订单系统最多能处理一万次订单,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。
使用消息队列做缓冲,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这事有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好。
消息分发
多个服务队数据感兴趣,只需要监听同一类消息即可处理。

例如A产生数据,B对数据感兴趣。如果没有消息的队列A每次处理完需要调用一下B服务。过了一段时间C对数据也感性,A就需要改代码,调用B服务,调用C服务。只要有服务需要,A服务都要改动代码。很不方便。

有了消息队列后,A只管发送一次消息,B对消息感兴趣,只需要监听消息。C感兴趣,C也去监听消息。A服务作为基础服务完全不需要有改动
异步消息

有些服务间调用是异步的,例如A调用B,B需要花费很长时间执行,但是A需要知道B什么时候可以执行完,以前一般有两种方式,A过一段时间去调用B的查询api查询。或者A提供一个callback api,B执行完之后调用api通知A服务。这两种方式都不是很优雅

使用消息总线,可以很方便解决这个问题,A调用B服务后,只需要监听B处理完成的消息,当B处理完成后,会发送一条消息给MQ,MQ会将此消息转发给A服务。
这样A服务既不用循环调用B的查询api,也不用提供callback api。同样B服务也不用做这些操作。A服务还能及时的得到异步处理成功的消息
1.3 常见消息队列及比较

结论:
Kafka在于分布式架构,RabbitMQ基于AMQP协议来实现,RocketMQ/思路来源于kafka,改成了主从结构,在事务性可靠性方面做了优化。广泛来说,电商、金融等对事务性要求很高的,可以考虑RabbitMQ和RocketMQ,对性能要求高的可考虑Kafka
二 Rabbitmq安装
官网:https://www.rabbitmq.com/getstarted.html
#####2.1 服务端原生安装##### # 安装配置epel源 # 安装erlang yum -y install erlang # 安装RabbitMQ yum -y install rabbitmq-server #####2.2 服务端Docker安装##### docker pull rabbitmq:management docker run -di --name Myrabbitmq -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin -p 15672:15672 -p 5672:5672 rabbitmq:managemen #####2.3 客户端安装##### pip3 install pika #####2.4 设置用户和密码##### rabbitmqctl add_user lqz 123 # 设置用户为administrator角色 rabbitmqctl set_user_tags lqz administrator # 设置权限 rabbitmqctl set_permissions -p "/" root ".*" ".*" ".*" # 然后重启rabbiMQ服务 systemctl reatart rabbitmq-server # 然后可以使用刚才的用户远程连接rabbitmq server了。
三 基于Queue实现生产者消费者模型
import Queue import threading message = Queue.Queue(10) def producer(i): while True: message.put(i) def consumer(i): while True: msg = message.get() for i in range(12): t = threading.Thread(target=producer, args=(i,)) t.start() for i in range(10): t = threading.Thread(target=consumer, args=(i,)) t.start()
四 基本使用(生产者消费者模型)
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
import pika # 无密码 # connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1')) # 有密码 credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列) channel.queue_declare(queue='lqz') channel.basic_publish(exchange='', routing_key='lqz', # 消息队列名称 body='hello world') connection.close()
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列) channel.queue_declare(queue='lqz') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) channel.basic_consume(queue='lqz',on_message_callback=callback,auto_ack=True) channel.start_consuming()
五 消息安全之ack
import pika # 无密码 # connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1')) # 有密码 credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列) channel.queue_declare(queue='lqz') channel.basic_publish(exchange='', routing_key='lqz', # 消息队列名称 body='hello world') connection.close()
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列) channel.queue_declare(queue='lqz') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) # 通知服务端,消息取走了,如果auto_ack=False,不加下面,消息会一直存在 # ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_consume(queue='lqz',on_message_callback=callback,auto_ack=False) channel.start_consuming()
六 消息安全之durable持久化
import pika # 无密码 # connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1')) # 有密码 credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列),durable=True支持持久化,队列必须是新的才可以 channel.queue_declare(queue='lqz1',durable=True) channel.basic_publish(exchange='', routing_key='lqz1', # 消息队列名称 body='111', properties=pika.BasicProperties( delivery_mode=2, # make message persistent,消息也持久化 ) ) connection.close()
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列) channel.queue_declare(queue='lqz1') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) # 通知服务端,消息取走了,如果auto_ack=False,不加下面,消息会一直存在 # ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_consume(queue='lqz1',on_message_callback=callback,auto_ack=False) channel.start_consuming()
七 闲置消费
正常情况如果有多个消费者,是按照顺序第一个消息给第一个消费者,第二个消息给第二个消费者
但是可能第一个消息的消费者处理消息很耗时,一直没结束,就可以让第二个消费者优先获得闲置的消息
import pika # 无密码 # connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1')) # 有密码 credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列),durable=True支持持久化,队列必须是新的才可以 channel.queue_declare(queue='lqz123',durable=True) channel.basic_publish(exchange='', routing_key='lqz123', # 消息队列名称 body='111', properties=pika.BasicProperties( delivery_mode=2, # make message persistent,消息也持久化 ) ) connection.close()
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 声明一个队列(创建一个队列) # channel.queue_declare(queue='lqz123') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) # 通知服务端,消息取走了,如果auto_ack=False,不加下面,消息会一直存在 ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) #####就只有这一句话 谁闲置谁获取,没必要按照顺序一个一个来 channel.basic_consume(queue='lqz123',on_message_callback=callback,auto_ack=False) channel.start_consuming()
八 发布订阅
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='m1',exchange_type='fanout') channel.basic_publish(exchange='m1', routing_key='', body='lqz nb') connection.close()
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # exchange='m1',exchange(秘书)的名称 # exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列 channel.exchange_declare(exchange='m1',exchange_type='fanout') # 随机生成一个队列 result = channel.queue_declare(queue='',exclusive=True) queue_name = result.method.queue print(queue_name) # 让exchange和queque进行绑定. channel.queue_bind(exchange='m1',queue=queue_name) def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True) channel.start_consuming()
九 发布订阅高级之Routing(按关键字匹配)
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='m2',exchange_type='direct') channel.basic_publish(exchange='m2', routing_key='bnb', # 多个关键字,指定routing_key body='lqz nb') connection.close()
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # exchange='m1',exchange(秘书)的名称 # exchange_type='direct' , 秘书工作方式将消息发送给不同的关键字 channel.exchange_declare(exchange='m2',exchange_type='direct') # 随机生成一个队列 result = channel.queue_declare(queue='',exclusive=True) queue_name = result.method.queue print(queue_name) # 让exchange和queque进行绑定. channel.queue_bind(exchange='m2',queue=queue_name,routing_key='nb') channel.queue_bind(exchange='m2',queue=queue_name,routing_key='bnb') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True) channel.start_consuming()
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # exchange='m1',exchange(秘书)的名称 # exchange_type='direct' , 秘书工作方式将消息发送给不同的关键字 channel.exchange_declare(exchange='m2',exchange_type='direct') # 随机生成一个队列 result = channel.queue_declare(queue='',exclusive=True) queue_name = result.method.queue print(queue_name) # 让exchange和queque进行绑定. channel.queue_bind(exchange='m2',queue=queue_name,routing_key='nb') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True) channel.start_consuming()
九 发布订阅高级之Topic(按关键字模糊匹配)
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='m3',exchange_type='topic') channel.basic_publish(exchange='m3', # routing_key='lqz.handsome', #都能收到 routing_key='lqz.handsome.xx', #只有lqz.#能收到 body='lqz nb') connection.close()
*只能加一个单词
#可以加任意单词字符
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # exchange='m1',exchange(秘书)的名称 # exchange_type='direct' , 秘书工作方式将消息发送给不同的关键字 channel.exchange_declare(exchange='m3',exchange_type='topic') # 随机生成一个队列 result = channel.queue_declare(queue='',exclusive=True) queue_name = result.method.queue print(queue_name) # 让exchange和queque进行绑定. channel.queue_bind(exchange='m3',queue=queue_name,routing_key='lqz.#') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True) channel.start_consuming()
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # exchange='m1',exchange(秘书)的名称 # exchange_type='topic' , 模糊匹配 channel.exchange_declare(exchange='m3',exchange_type='topic') # 随机生成一个队列 result = channel.queue_declare(queue='',exclusive=True) queue_name = result.method.queue print(queue_name) # 让exchange和queque进行绑定. channel.queue_bind(exchange='m3',queue=queue_name,routing_key='lqz.*') def callback(ch, method, properties, body): queue_name = result.method.queue # 发送的routing_key是什么 print("消费者接受到了任务: %r" % body) channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True) channel.start_consuming()
十 基于rabbitmq实现rpc
import pika credentials = pika.PlainCredentials("admin","admin") connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials)) channel = connection.channel() # 起翰监听任务队列 channel.queue_declare(queue='rpc_queue') def on_request(ch, method, props, body): n = int(body) response = n + 100 # props.reply_to 要放结果的队列. # props.correlation_id 任务 ch.basic_publish(exchange='', routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id= props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume( queue='rpc_queue',on_message_callback=on_request,) channel.start_consuming()
import pika import uuid class FibonacciRpcClient(object): def __init__(self): credentials = pika.PlainCredentials("admin", "admin") self.connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166', credentials=credentials)) self.channel = self.connection.channel() # 随机生成一个消息队列(用于接收结果) result = self.channel.queue_declare(queue='',exclusive=True) self.callback_queue = result.method.queue # 监听消息队列中是否有值返回,如果有值则执行 on_response 函数(一旦有结果,则执行on_response) self.channel.basic_consume(queue=self.callback_queue,on_message_callback=self.on_response, auto_ack=True) def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) # 客户端 给 服务端 发送一个任务: 任务id = corr_id / 任务内容 = '30' / 用于接收结果的队列名称 self.channel.basic_publish(exchange='', routing_key='rpc_queue', # 服务端接收任务的队列名称 properties=pika.BasicProperties( reply_to = self.callback_queue, # 用于接收结果的队列 correlation_id = self.corr_id, # 任务ID ), body=str(n)) while self.response is None: self.connection.process_data_events() return self.response fibonacci_rpc = FibonacciRpcClient() response = fibonacci_rpc.call(50) print('返回结果:',response)
一、什么是RPC
RPC 的全称是 Remote Procedure Call ,是一种进程间通信方式。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即无论是调用本地接口/服务的还是远程的接口/服务,本质上编写的调用代码基本相同。
说起RPC,就不能不提到分布式,这个促使RPC诞生的领域。
假设你有一个计算器接口,Calculator模块,以及它的实现类CalculatorImpl,那么在系统还是单体应用时,你要调用Calculator的add方法来执行一个加运算,直接实例一个CalculatorImpl对象,然后调用add方法就行了,这其实就是非常普通的本地函数调用,因为在同一个地址空间,或者说在同一块内存,所以可以直接实现。
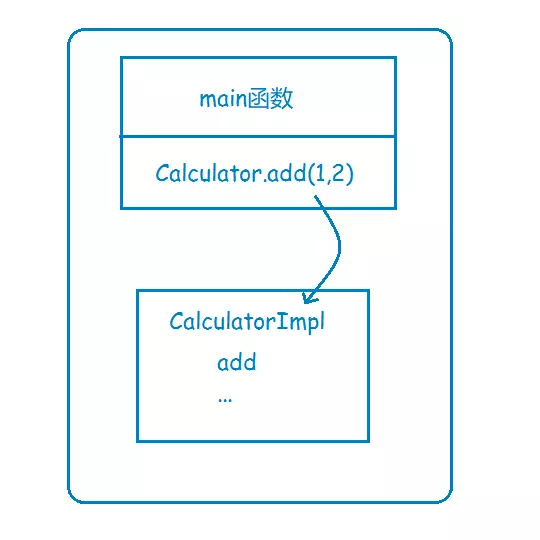
现在,基于高性能和高可靠等因素的考虑,你决定将系统改造为分布式应用,将很多可以共享的功能都单独拎出来,比如上面说到的计算器,你单独把它放到一个服务里头,让别的服务去调用它。
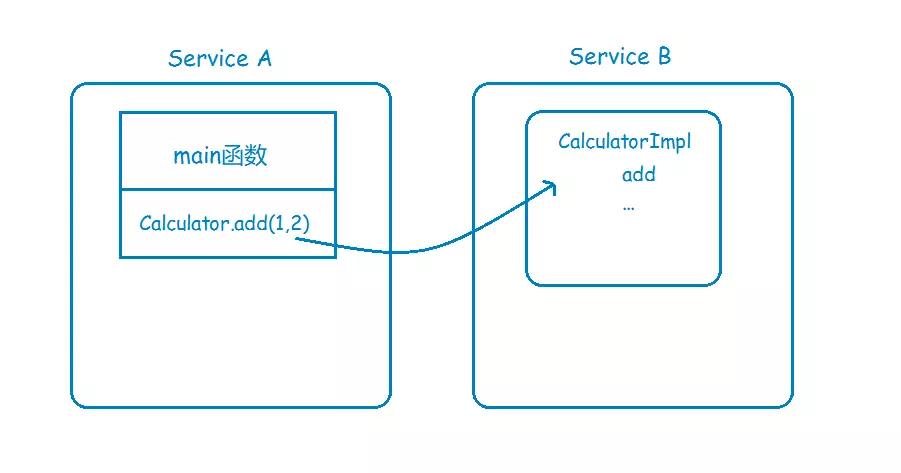
这下问题来了,服务A里头并没有CalculatorImpl这个类,那它要怎样调用服务B的CalculatorImpl的add方法呢?
有同学会说,可以模仿B/S架构的调用方式呀,在B服务暴露一个Restful接口,然后A服务通过调用这个Restful接口来间接调用CalculatorImpl的add方法。
很好,这已经很接近RPC了,不过如果是这样,那每次调用时,是不是都需要写一串发起http请求的代码呢?比如
|
1
|
res=requests.get("URL") |
1、http协议较为复杂,效率低,相对笨重
二、如何实现RPC
1、RPC实现原理
实际情况下,RPC很少用到http协议来进行数据传输,毕竟我只是想传输一下数据而已,何必动用到一个文本传输的应用层协议呢,所以一般会选择直接传输二进制数据
不管你用何种协议进行数据传输,一个完整的RPC过程,都可以用下面这张图来描述:
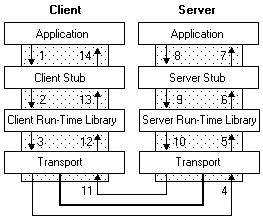
以左边的Client端为例,Application就是rpc的调用方,Client Stub就是我们上面说到的代理对象,也就是那个看起来像是Calculator的实现类,其实内部是通过rpc方式来进行远程调用的代理对象,至于Client Run-time Library,则是实现远程调用的工具包,比如python的socket模块,最后通过底层网络实现实现数据的传输。
2、python实现RPC
# 客户端 import rpyc # 参数主要是host, port conn = rpyc.connect('localhost', 9999) # test是服务端的那个以"exposed_"开头的方法 print('start') for i in range(100): cResult = conn.root.cal(i) print(cResult) print('end') conn.close() # 服务端 from rpyc import Service from rpyc.utils.server import ThreadedServer class TestService(Service): # 对于服务端来说, 只有以"exposed_"打头的方法才能被客户端调用,所以要提供给客户端的方法都得加"exposed_" def exposed_cal(self, num): return num*2 sr = ThreadedServer(TestService, port=9999, auto_register=False) sr.start()
3、GRPC框架
目前流行的开源 RPC 框架还是比较多的,有阿里巴巴的 Dubbo、Facebook 的 Thrift、Google 的 gRPC、Twitter 的 Finagle 等。
gRPC:是 Google 公布的开源软件,基于最新的 HTTP 2.0 协议,并支持常见的众多编程语言。RPC 框架是基于 HTTP 协议实现的,底层使用到了 Netty 框架的支持。
Thrift:是 Facebook 的开源 RPC 框架,主要是一个跨语言的服务开发框架。用户只要在其之上进行二次开发就行,应用对于底层的 RPC 通讯等都是透明的。不过这个对于用户来说需要学习特定领域语言这个特性,还是有一定成本的。
Dubbo:是阿里集团开源的一个极为出名的 RPC 框架,在很多互联网公司和企业应用中广泛使用。协议和序列化框架都可以插拔是极其鲜明的特色。
以使用较为广泛的gRPC为例学习下RPC框架的使用
gRPC 是 Google 开放的一款 RPC (Remote Procedure Call) 框架,建立在 HTTP2 之上,使用 Protocol Buffers。
1、Protocol Buffers 简介
protocol buffers 是 Google 公司开发的一种数据描述语言,采用简单的二进制格式,比 XML、JSON 格式体积更小,编解码效率更高。用于数据存储、通信协议等方面。
通过一个 .proto 文件,你可以定义你的数据的结构,并生成基于各种语言的代码。目前支持的语言很多,有 Python、golang、js、java 等等。
2、gRPC 简介
有了 protocol buffers 之后,Google 进一步推出了 gRPC。通过 gRPC,我们可以在 .proto 文件中也一并定义好 service,让远端使用的 client 可以如同调用本地的 library 一样使用。
可以看到 gRPC Server 是由 C++ 写的,Client 则分別是 Java 以及 Ruby,Server 跟 Client 端则是通过 protocol buffers 来信息传递。
1. 定义功能函数
calculate.py
# -*- coding: utf-8 -*- import math # 求平方 def square(x): return math.sqrt(x)
2. 创建 .proto 文件
在这里描述我们要使用的 message 以及 service
syntax = "proto3"; message Number { float value = 1; } service Calculate { rpc Square(Number) returns (Number) {} }
3. 生成 gRPC 类
这部分可能是整个过程中最“黑盒子”的部分。我们将使用特殊工具自动生成类。
$ pip install grpcio grpcio-tools
$ python -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. calculate.proto
你会看到生成来两个文件:
- calculate_pb2.py — 包含 message(calculate_pb2.Number)
- calculate_pb2_grpc.py — 包含 server(calculate_pb2_grpc.CalculatorServicer) and client(calculate_pb2_grpc.CalculatorStub)
4. 创建 gRPC 服务端
server.py
# -*- coding: utf-8 -*- import grpc import calculate_pb2 import calculate_pb2_grpc import calculate from concurrent import futures import time # 创建一个 CalculateServicer 继承自 calculate_pb2_grpc.CalculateServicer class CalculateServicer(calculate_pb2_grpc.CalculateServicer): def Square(self, request, context): response = calculate_pb2.Number() response.value = calculate.square(request.value) return response # 创建一个 gRPC server server = grpc.server(futures.ThreadPoolExecutor(max_workers=10)) # 利用 add_CalculateServicer_to_server 这个方法把上面定义的 CalculateServicer 加到 server 中 calculate_pb2_grpc.add_CalculateServicer_to_server(CalculateServicer(), server) # 让 server 跑在 port 50051 中 print 'Starting server. Listening on port 50051.' server.add_insecure_port('[::]:50051') server.start() # 因为 server.start() 不会阻塞,添加睡眠循环以持续服务 try: while True: time.sleep(24 * 60 * 60) except KeyboardInterrupt: server.stop(0)
启动 gRPC server:
$ python server.py
Starting server. Listening on port 50051.
5. 创建 gRPC 客户端
client.py
# -*- coding: utf-8 -*- import grpc import calculate_pb2 import calculate_pb2_grpc # 打开 gRPC channel,连接到 localhost:50051 channel = grpc.insecure_channel('localhost:50051') # 创建一个 stub (gRPC client) stub = calculate_pb2_grpc.CalculateStub(channel) # 创建一个有效的请求消息 Number number = calculate_pb2.Number(value=16) # 带着 Number 去调用 Square response = stub.Square(number) print response.value
启动 gRPC client:
$ python client.py
4.0
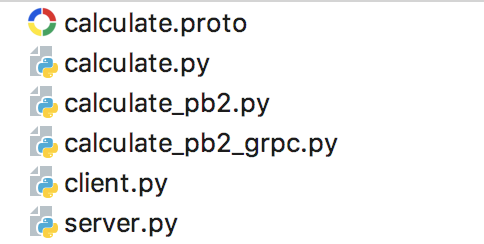
最终的文件结构:
三、总结
RPC 主要用于公司内部的服务调用,性能消耗低,传输效率高,实现复杂。
HTTP 主要用于对外的异构环境,浏览器接口调用,App 接口调用,第三方接口调用等。
RPC 使用场景(大型的网站,内部子系统较多、接口非常多的情况下适合使用 RPC):
- 长链接。不必每次通信都要像 HTTP 一样去 3 次握手,减少了网络开销。
- 注册发布机制。RPC 框架一般都有注册中心,有丰富的监控管理;发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作。
- 安全性,没有暴露资源操作。
- 微服务支持。就是最近流行的服务化架构、服务化治理,RPC 框架是一个强力的支撑。
四、RPC没那么简单
要实现一个RPC不算难,难的是实现一个高性能高可靠的RPC框架。
比如,既然是分布式了,那么一个服务可能有多个实例,你在调用时,要如何获取这些实例的地址呢?
这时候就需要一个服务注册中心,比如在Dubbo里头,就可以使用Zookeeper作为注册中心,在调用时,从Zookeeper获取服务的实例列表,再从中选择一个进行调用。
那么选哪个调用好呢?这时候就需要负载均衡了,于是你又得考虑如何实现复杂均衡,比如Dubbo就提供了好几种负载均衡策略。
这还没完,总不能每次调用时都去注册中心查询实例列表吧,这样效率多低呀,于是又有了缓存,有了缓存,就要考虑缓存的更新问题,blablabla......
你以为就这样结束了,没呢,还有这些:
- 客户端总不能每次调用完都干等着服务端返回数据吧,于是就要支持异步调用;
- 服务端的接口修改了,老的接口还有人在用,怎么办?总不能让他们都改了吧?这就需要版本控制了;
- 服务端总不能每次接到请求都马上启动一个线程去处理吧?于是就需要线程池;
- 服务端关闭时,还没处理完的请求怎么办?是直接结束呢,还是等全部请求处理完再关闭呢?
- ......
如此种种,都是一个优秀的RPC框架需要考虑的问题。