>>> import pandas as pd
>>> import numpy as np
添加列
df = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
df['A1']=78

添加行
append(other, ignore_index=False, verify_integrity=False, sort=False)
df = pd.DataFrame(data = {'name':['Tom', 'Jack', 'Steve', 'Ricky'],'age':[28,34,29,42]})
df3=df.append(pd.DataFrame({'name':['Rose'],'age':[18]}),ignore_index=True)
df3.loc[4]=['Jack',32]

插入列
insert(loc, column, value, allow_duplicates=False)
参数:
loc: int型,表示第几列;若在第一列插入数据,则 loc=0
column: 给插入的列取名,如 column='新的一列'
value:数字,array,series等都可(可自己尝试)
allow_duplicates: 是否允许列名重复,选择Ture表示允许新的列名与已存在的列名重复。
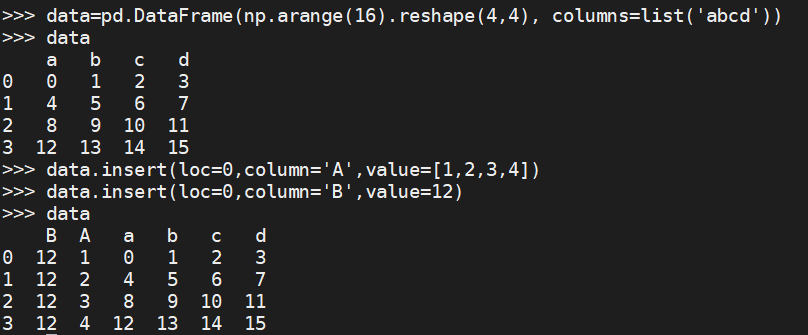
data=pd.DataFrame(np.arange(16).reshape(4,4), columns=list('abcd'))
data.insert(loc=0,column='A',value=[1,2,3,4])
data.insert(loc=0,column='B',value=12)
删除行
drop(axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
df = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
df.drop(axis=0,index=[2,3])

删除列
df = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
df.drop(axis=1,columns=['A','C'])
df.pop('A')
