前言
由于 ndoejs 是基于 v8 引擎的,而且对于内存的使用也是 v8 申请和分配的。所以这里的垃圾回收实际就是 v8 下的垃圾回收机制。
V8的内存限制
在默认情况下,nodejs 只能使用物理内存的部分内存,具体大小为 1.4G(64位系统) 和 0.7G(32位系统),无法操作大文件(比如一个2G大小的文件),使用内存超过限制就会进程退出。
-
原因
- v8 最初是为浏览器而设计的,很少会遇到使用大内存的场景,而 nodejs 恰恰就是基于 v8 构建的,所以 nodejs 也受到了此限制;
- 垃圾回收时会引起应用逻辑暂停执行,垃圾越多,暂停的时间越长,而整体应用的等待时间就越长,这样直接影响应用的体验,所以直接限制堆内存的使用。
-
解除限制
node在启动时可以添加 --max-old-space-size 或 --max-new-space-size 来调整限制的大小,如:
node --max-old-space-size=2000 index.js // 单位为MB
node --max-new-space-size=500 index.js // 单位为MB
当然,就算显示设定内存的限制,node 一旦启动,内存限制是无法动态改变的。
V8的垃圾回收算法
v8的垃圾回收策略主要基于分代式的垃圾回收机制。将对象在内存中的存活时间进行分代,然后再在不同的分代中进行不同的回收算法。
-
v8的内存分代
在v8中,主要将内存分为新生代和老生代两代,所以v8的堆内存大小为 新生代内存占用的大小加上老生代内存占用的大小。
新生代:主要为存活时间较短的对象;
老生代:主要为存活时间较长或常驻内存的对象。

--max-old-space-size 就是设置老生代的内存大小,--max-new-space-size 就是设置新生代的内存大小。
但是在 node 执行过程中,如果内存的分配超过限制值,就会造成进程错误。
-
新生代回收算法
在新生代中,垃圾回收算法采用的是 Scavenge 的具体实现的 Cheney 算法。
Cheney 算法将堆内存一分为二,分别为 From 和 To;

在进行内存分配时,是在 From 中进行分配的;
而在垃圾回收时,会检查 From 中的存活对象,并将这些存活对象复制到 To 中;
然后再将非存活对象进行释放;
在下一轮回收时,将 To 中的存活对象复制到 From 中,而此时,To 就变成了 From,From 变成了 To。
每次垃圾回收,From 和 To 会互换。
这个算法在复制时只复制了存活对象,所以在垃圾回收时较快,但是只利用了堆内存的一半,这是典型的空间换时间算法。由于在新生代中,对象的存活时间较短,所占用的内存空间也较少,所以就非常适合这个算法。
-
-
晋升
-
在复制的过程中,如果一个对象经过多次复制并依然存活,那么它会被当成生命周期较长的对象,并把它移动到老生代中,这种从新生代移动到老生代中的过程就叫晋升。
晋升一般需要满足两个条件:
1:一个对象是否已经经历过回收了,如果经历过了就复制到老生代中,没有就复制到 To 中;
2:判断 To 空间的已使用内存的占比,如果在复制过程中,To 空间的已使用内存占比超过了 25%,就将此对象复制到老生代中。
25% 是因为,当 To 转换为 From 时,内存分配需要在 From 中分配,而如果占比过高,那么就会影响后续的内存分配。
-
老生代回收算法
老生代中使用的是其他回收算法,如果在老生代中继续使用 Scavenge ,那么复制的效率会很低,因为在老生代中的对象是存活时间较长的,存活的对象也较多,其次就是会浪费一半的内存空间。
所以在老生代中是使用 Mark-Sweep 和 Mark-Compact 两种算法相结合的方式。
-
-
Mark-Sweep
-
Mark-Sweep 是标记清除的意思,回收分两个阶段:标记和清除,在标记的时候遍历内存中的所有存活对象,然后清除没有标记的对象。因为在老生代中,对象存活时间较长,说明存活对象较多,非存活对象较少,所以使用 Mark-Sweep 就非常高效。

黑色部分代表非存活对象。
Mark-Sweep 的缺点是清除掉非存活对象后,内存状态不是连续的,而此时如果需要分配一个大对象,所有的内存碎片都无法满足,这样就会提前触发回收。

-
-
Mark-Compact
-
Mark-Compact 就是解决 Mark-Sweep 回收后的问题的,意为标记整理。使用 Mark-Sweep 回收后,再使用 Mark-Compact 将所有存活对象往一端移动,再清理掉边界外的内存。
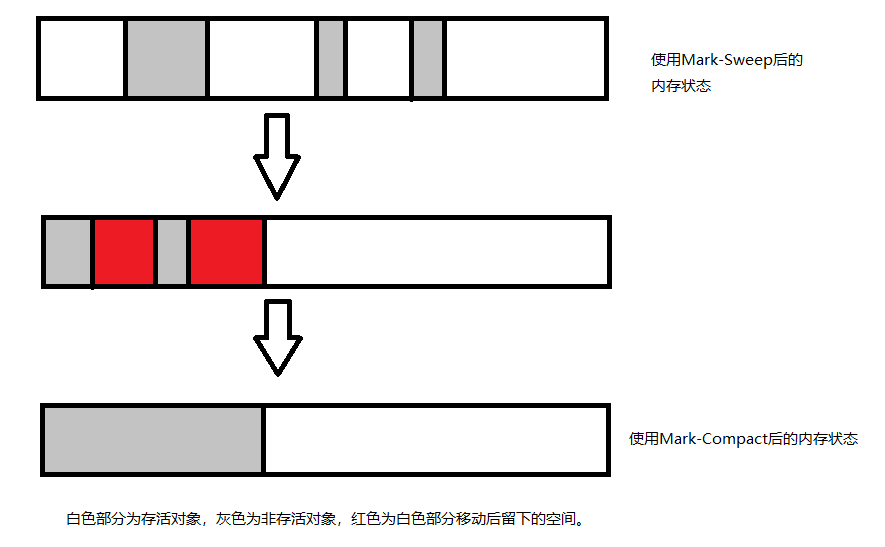
在 v8 中,老生代中主要还是用 Mark-Sweep ,在内存不足以分配时才使用 Mark-Compact。
-
-
增量回收
-
由于垃圾回收时会造成应用逻辑停顿(暂停执行),而在老生代空间中一般存活对象较多,需要标记大量对象,造成停顿较长,影响应用。所以在标记时进行增量标记。
将一次性需要标记的对象分多次进行,标记一些,再让应用执行,然后再暂停标记一些,再让应用执行.....,循环交替,达到改善的目的。
同样在清理与整理时也有增量操作。
常见内存泄露
一般造成内存泄露的原因主要是:缓存、作用域未释放、队列消费不及时。
-
缓存
一般缓存造成的泄露主要就是把内存当缓存使用,一旦把内存当缓存使用,那么这块内存中的对象就会常驻在老生代中,随着缓存增大,超过老生代的空间,进而造成泄露。
限制缓存大小,使用其他缓存(redis)代替都能有效解决。
-
作用域未释放
比较经典的案例就是在导入的模块,而模块内的某一方法为其私有变量添加了内存占用。如下:
1 var leakArray = []; 2 3 exports.leak = function () { 4 5 leakArray.push("leak" + Math.random()); 6 7 };
每执行一次 leak ,其 leakArray 就会添加一次内存占用。这是因为导入模块,会将模块缓存起来,而缓存的模块是常驻在内存中的,直到进程退出。
-
队列消费不及时
如收集日志,将日志存到数据库中,通常日志非常多,而写入数据库的效率又比较慢,而此时就会有很多的数据库写入操作,而正因为这些操作的堆积,操作的作用域也没被释放,最终造成泄露。