from pyhanlp import *
def my_segment(sentence):
seg = HanLP.segment(sentence)
seg2 = list(seg)
seg3 = list(map(lambda x: str(x), seg2))
seg4 = list(map(lambda x: x.split('/')[0], seg3))
return seg4
seg = my_segment('自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。')
print(seg)
运行结果如下
['自然语言处理', '是', '计算机', '科学', '领域', '与', '人工智能', '领域', '中的', '一个', '重要', '方向', '。']
观察分词结果,我们发现“计算机科学”这个词被分成了两个部分,为了解决这个问题,接下来我们将“计算机科学”这个词加入自定义词典中,有两种方式可以实现。
方法一:动态添加
CustomDictionary.add("计算机科学")
seg = my_segment('自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。')
运行结果如下
['自然语言处理', '是', '计算机科学', '领域', '与', '人工智能', '领域', '中的', '一个', '重要', '方向', '。']
方法二:追加词典
pyhanlp是hanlp的python接口,我们进入对应的hanlp目录(这个目录的路径在pyhanlp的__init__.py文件中由用户添加),接着进入该目录下的 /data/dictionary/custom 子目录,打开CustomDictionary.txt文件,然后将要添加的词写入该文件即可,不写词性和词频也可以运行,运行结果与上一种方式的结果相同。
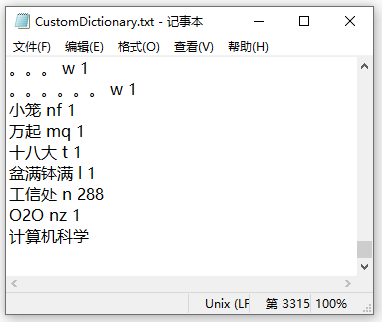
在pyhanlp的安装目录 C:python36Libsite-packagespyhanlp 下的 statichanlp.properties.in 文件中可以找到这种添加方式的依据,如下所示
#自定义词典路径,用;隔开多个自定义词典,空格开头表示在同一个目录,使用“文件名 词性”形式则表示这个词典的词性默认是该词性。优先级递减。
#另外data/dictionary/custom/CustomDictionary.txt是个高质量的词库,请不要删除。所有词典统一使用UTF-8编码。
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; 现代汉语补充词库.txt; 全国地名大全.txt ns; 人名词典.txt; 机构名词典.txt; 上海地名.txt ns;data/dictionary/person/nrf.txt nrf;
参考文献:
HanLP分词+用户自定义词典