前言
HDFS在近几年中得到了迅速的发展,作为性价比比较高的存储系统,用户、企业只需利用若干台低配廉价的节点机型,就可以构建能够承受TB甚至PB级别的大数据集群,然后在上面做各种类型任务的作业,而且在底层方面,我们完全可以依赖HDFS自身实现的容错机制来应当各种异常情况。但是在当今数据使用场景日益多元化的背景下,HDFS并不是能满足所有的应用需求。如何能够以一种更加高效,方便的方式去存储用户想要保存的数据,成为了一个急需去解决的问题。于是后面诞生出了一个企业级的存储方案:对象存储。对照存储的出现直接方便了一些抽象数据类型的存储。目前市面上也已经有许多相应的对象存储服务,当然了,社区也意识到了这一点,于是在2014年的时候提出了一个观点:基于HDFS内部,提供一个对象存储的服务,名叫Ozone。本文笔者就来好好聊聊这个话题。我们来聊聊Ozone目前的情况以及它未来的一些动向。
Ozone的起源
在前言中笔者已经说过,Ozone的提出在2014年,由Hortonworks率先提出,并建立了一个JIRA:HDFS-7240(Object store in HDFS)。一个大背景是当时许多企业已经推出了对象存储的服务而HDFS还不支持。
现在有一个问题来了,如果在HDFS内部做一套这样的功能,它的工作量绝对是不小的,而且如果做出来了,它如何与市面已有的对象存储服务竞争呢,换句话说它有什么自身的优势呢?说到这里,答案是有的。HDFS作为Hadoop中的一个组件,发展了这么多年,它的普及以及使用率一定是有一些的,用户也已经习惯于将数据存放到HDFS上。如果HDFS这时还能支持对象存储了,可能用户就完全不需要考虑重新花钱去买另外一套服务了,在自身集群内部使用这项功能就可以了。
Ozone的核心设计
Ozone的架构设计可能是更多人所关系的,它是否与业界目前主流的对象存储概念吻合呢?关于这一点,笔者在去年的时候已经写过一篇文章(HDFS对象存储–Ozone架构设计)介绍过HDFS Ozone的一些设计细节了,感兴趣的读者可阅读此文章。
笔者之前曾经学习过AWS的S3存储和阿里云OSS的使用方式,大体上来说,许多概念在定义上是一致的。比如说下面这个共同点:
用户通过创建自身的bucket(桶),在此bucket下存入用户的文件数据,这些文件数据在逻辑层面就是此bucket下的一个个object对象。每个对象对应于一个key。而这个key也是用户在存入数据是指定的,当然,如果我们保证后面文件名一定不会重复的话,我们可以直接拿文件名称作为key值。
笔者去年写的文章是Ozone的初始版本,近期社区给出了一个更新版本,在原先的基础上做了很多地方的改进。所以笔者打算重新拿出来聊聊。
Ozone面向用户的使用方式
首先我们要理解Ozone中涉及对象存储的概念定义,用一个简单的结构图表示如下:
VolumeA
|
BucketA
| |
ObjectA1(keyA1) ObjectA2(keyA2)
没错,就是上面看到的volume->bucket->object这样的3级结构。用户如果想要在HDFS Ozone上存入文件数据,简单的可以概括为如下步骤:
- 1.创建一个新的volume
- 2.创建一个新的bucket
- 3.往刚刚创建的bucket中执行一个put key的操作,put key操作的时候,key由自身指定,伴随一个需要存入的本地文件的路径。此文件即为待存入的对象数据。
以上操作在HDFS内部对应的通信方式都是走http请求的。所以看到这里,如果大家已经使用过业界已有的企业级对象存储服务,将几乎不需要花额外的时间去学习Ozone的用法。
Ozone中的底层设计:Container
前面讨论了很多bucket,volume的概念,那么这些概念对应存储在哪里呢?还有我们如何保证所存入对象的高可用呢?答案是Container。Container帮助我们解决了上面提到的2个问题。
首先第一个问题,bucket,volume这些概念对象本身不会被存入Container,因为bucket,volume这些概念是针对用户而言的,而在HDFS内部,它的作用仅仅只有一个:组成一个unique的key,然后使得HDFS能找到它所对应的对象数据。所以Container作为Ozone中的一个基本存储单元,它只包含2大类信息,一个是key,一个是文件对象。key由bucket、volume名称拼装而成,而文件对象由其内部的ChunkInfo信息所维护。下图是Container的内部结构图:
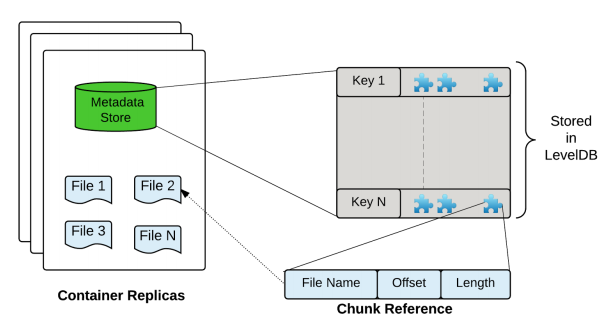
Ozone Container内部结构
在这里,我们可以理解Container是一个大的对象池,用户对应的数据,将会以key-data的形式往里进行put。
第二个问题,数据的容错性。Container是Ozone中的基本数据单元,类似于HDFS中的block的概念。所以Ozone将block拥有的一些机制再度应用到了Container的身上,比如说写数据的时候Container也是基于Pipeline的方式的(但是这个Pipeline在实现上是不同于DataNode的Pipeline的),同样它也有自己的副本对象。Container对象作为一个存储单元,可以被看作是各个DatraNode上的一个资源容器。用户要存入数据的时候,需要从DataNode中寻找到相应的Container,然后将数据存入。这里就牵扯到了Ozone内部调用过程的内容了。
Ozone的原理过程
Ozone的调用过程可以理解为是一个寻找Container的过程。中间过程中,需要向2大服务KSM、SCM进行Container的定位和获取。前者负责提供Container的位置,然后后者负责返回Container对象。(但是目前代码中这2个功能都耦合在了SCM上面)。社区将其分离化的一个主要目的是为了方便后续的扩展。
对应上面的描述,流程图如下所示:
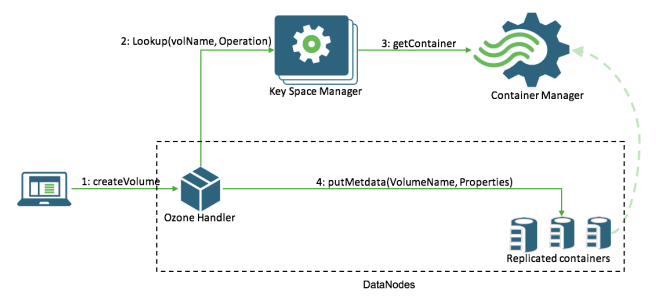
Ozone请求调用过程
上面只是局部的过程,下面为全链路的过程:
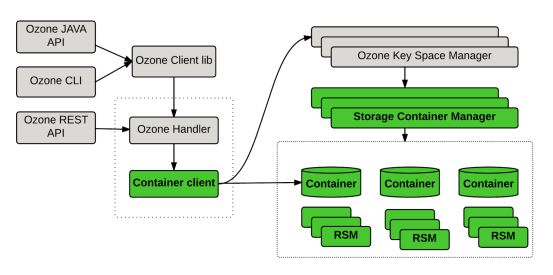
Ozone内部调用过程
以上就是笔者想要介绍Ozone相关的内容,希望能够带给大家对于Ozone更多的了解。
参考资料
[1].Object store in HDFS, https://issues.apache.org/jira/browse/HDFS-7240
[2].Ozonedesignupdate, https://issues.apache.org/jira/secure/attachment/12806271/Ozonedesignupdate.pdf