本篇和大家谈谈一种通用的设计与处理模型——Pipeline(管道)。
Pipeline简单介绍
Pipeline模型最早被使用在Unix操作系统中。据称,假设说Unix是计算机文明中最伟大的发明,那么,Unix下的Pipe管道就是尾随Unix所带来的还有一个伟大的发明【1】。我觉得管道的出现,所要解决的问题,还是软件设计中老生常谈的设计目标——高内聚,低耦合。它以一种“链式模型”来串接不同的程序或者不同的组件,让它们组成一条直线的工作流。这样给定一个完整的输入,经过各个组件的先后协同处理,得到唯一的终于输出。
Pipeline模型的应用
以下列举了,我熟悉或者有所了解的典型pipeline模型的应用。
公司.net web程序猿非常多,那么首先就谈谈asp.net。一个http请求到达httpserverIIS之后,就是经过pipeline模型被处理的。參见下图:
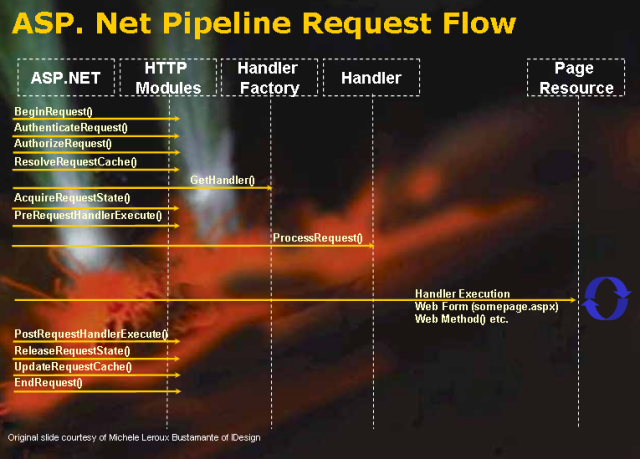
说明一下,这幅图,并没有以下的图形来得直观。它的側重点在于展示管道中各个组件处理事件触发的时序图,而不是pipeline模型。但假设你思考以下,也能体会到当中“管道”的概念(注意右面循环图标,假设须要比划一下的话,就是一个U逆时针旋转90度的形状)。
最后,我还是决定上个清晰点的图:

上图能够请求到达IIS,经过HttpApplication工厂得到一个HttpApplication,创建一个HttpContext上下文,然后就会进入Http Pipeline。好了,这篇的目标并非谈论http处理行为以及asp.net底层架构,所以到此为止。
又一个大家熟悉的web container,特别是java web人员——Tomcat
Tomcat接受请求之后,请求从被接受,被分发,被处理,到最后转变成http响应,会走例如以下的管道【2】:
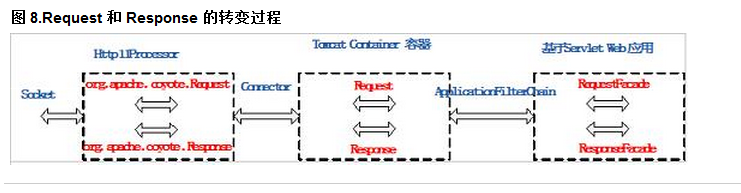
在《Tomcat系统架构与设计模式,第2部分: 设计模式分析》【3】中,你能够清晰地发现一个最为显而易见的设计模式——责任链模式(这是实现管道模型比較经常使用的一种设计模式)

可见,pipeline模型差点儿是大部分主流http server处理请求的通用模型。这样的设计并不意外,由于pipeline模型特定的理念会让你感觉到它似乎就是为了处理请求而生的。事实上,它的应用原不止这些web server架构。
以下,给大家带来的还有一个典型演示样例也是在web架构里广为人知的MVC模型的良好实践——Struts:

我觉得用这幅图来阐述Pipeline最为清晰,简洁。从上面这幅图中你能够看到对于pipeline模型的多处使用(单向、双向都有)。它也非常好地展示了高内聚,低耦合的设计目标,展示了各个组件以类似“搭建积木”的形式来组合功能(见图中Interceptor),我近期有空也在读struts2的源代码,假设你也有兴趣,能够看看这个专题。
最后一个演示样例了,公司Javaserver的开发者,相信都会对Mina框架有所了解。以下是Mina的处理模型图:
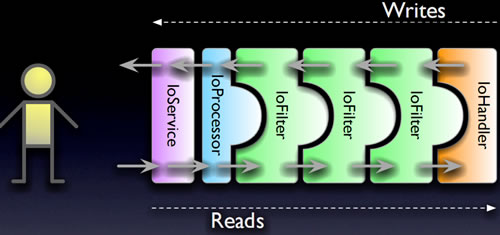
不再废话了,相同是pipeline的优秀实践。
上面介绍了非常多pipeline的优秀实践,他们并非来自同一个领域,有web端,有处理socket的等。但对于他们的一个归纳,能够是——优秀的服务端数据处理模型,我觉得公司在数据处理上比較频繁,这也是选择介绍pipeline模型的原因。
Pipeline模型带来的启发
事实上,关于它的优点已经在上面各种优秀的实践中得以体现。但你还是应该能够从中去发现一些能够为我们所用的设计思想。我总结了我得一些观点,欢迎各位拍砖:
(1) 工作流的參考模型
上面的各个模型图非常难让我不把pipeline模型与工作流模型联想到一块儿去。他们都是链式的(或者说流程式的),就像一条生产线一样。各个组件的前后协同,会让你联想到生产流水线上得工人处理流过自己的产品环节。事实上,我在去年年末的时候在云方圆徐工基础任务流程里面以前尝试使用了该模型,作为工作流模型。
(2) 服务framework的參考构建模型
Pipeline模型的一个特点是,在其内部是以组建的模式来实现组合的(尽管这些组建有先后顺序之分),它假如你把側重点放在它的链式组合上,而不是将側重点放在上面的工作流上(工作流的关注点是流程的先后顺序),那么全然能够用这样的方式来搭建一个复杂的服务,当然这样做的前提是,单个组件的粒度必须尽可能小而且耦合性极低。
在这里我冒昧吐槽几句:
在我的印象中,公司非常多服务都喜欢採用WebService,即使不是Web Service也是Http GET请求。当然,这当中的非常多情况是不得不採用它来和别的系统或者业务平台交互。但我一直坚持觉得,仅仅有在理论上你根本没有可能拿到那些数据时,你才会採用别人提供的服务,比方:股票行情、天气预报、各大开放平台(新浪、支付宝)的API的等。本公司之内的,原则上事实上能够訪问的某些数据,有时我们反而退而求其次选择採用Web Service这样的模式。批量数据走http或者之上的协议(SOAP)在网络上传输,有时web系统还有可能公布在远端。想要性能从哪儿来?我了解你操心安全性,希望保持本业务平台数据库的独立性。告诉我,事实上你也明确有些操心是没有意义的。我直接连你的库,仅仅做一些查询会有什么问题?假设你真的比較慎重的话,你也应该操心一下你的系统有被攻击的可能性,为什么你没有呢。甚至有人希望,某些类似的业务逻辑也把他抽象出来在dll外面包装成web service。假设真得是这样的话,我觉得“可复用的组件”这个词就没有必要存在了。
Pipeline模型应用
刚才谈到,我觉得Pipeline模型带来的启发,我个人更看好第二点。我觉得在NGP构建API的时候,这样的模型也能够派上大用场。
就拿Redis举个样例(在一些场景下):
读取数据流程
(1) 客户程序从Redis读取数据,假设读取到则返回
(2) 假设没有读取到,则从数据库抓取数据
(3) 从数据库抓取到的数据存储到Redis
写入数据流程
(1) 客户程序将数据写入Redis
(2) 将数据写入数据库
假如有一天,你不打算採用Redis,或者Redis服务所有不可用。你怎么让client自己能够“智能感知”,让这些巨大的后端变动对于client透明,而且不会产生调用异常?那么Pipeline模型,就能够派上用场。由于上面这些流程都是可配置的,而开放的API是唯一的。
你是否会觉得普通的封装也能够实现上面的读取数据流程?没错,也能够。但我觉得Pipeline模型带来的:流程式(有序)+可拆卸(配置),比普通的封装机动性更好。
当然,这里仅仅是选择了一个简单的场景来举个样例。
Pipeline模型实现
事实上在上面那个Tomcat的设计模式截图中已经看到,实现该模型最通常的设计模式就是责任链模式,在上面工作流那篇文章中,也是採用责任链模式来实现,但我当时忽略了一个非常重要的东西——Context,这是串联整个Pipeline的重要前提。
你找到一篇不论什么介绍责任链模式的文章,然后搭配淘宝的《基于管道模式的容器设计》【4】就基本能够全然了解Pipeline。
Pipeline模式的缺点
没有那种模式是完美的。Pipeline模式的缺点是,每次它对于一个输入(或者一次请求)都必须从链头開始遍历(參考Http Server处理请求就能明确),这确实存在一定的性能损耗。
引用
【1】:Unix Pipes 管道原稿
【2】:Servlet工作原理解析
【3】:Tomcat系统架构与设计模式,第 2 部分: 设计模式分析
【4】:基于管道模式的容器设计