云寻觅中文分词 (Yunxunmi Chinese Word Segmentation) 指的是将一个汉字序列切成一个一个单独的词。云寻觅中文分词就是将连续的字序列按照一定的规范重新组合成词序列的 过程。中文分词也是搜索引擎最核心的技术包括(全文索引,检索,排序权重计算,文本分类,聚类),因此,中文分词的准确性和高效性将直接决定一个搜索引擎的好坏,目前很多搜索引擎包括谷歌对中国各地的方言几乎无法识别,直接导致搜索结果漏洞百出,正是基于上述原因,本人不辞辛苦开发出云寻觅中文分词并开源,希望更多的有识之士从中受益。
云寻觅中文分词词库共有 5个,分别是
ciku860000.dat 共有86万左右的常用中文词汇
ciku1248500.dat 共有120万左右的常用中文词汇,包括互联网热门词汇
ciku1408964.dat 共有140万左右的常用中文词汇,包括互联网热门词汇,古今中外名人,常用地区
ciku2786019.dat 共有270万左右的常用中文词汇,包括互联网热门词汇,古今中外名人,全国各地及方言
ciku4000000.dat 共有400万左右的常用中文词汇,包括互联网热门词汇,古今中外名人,全国各地及方言,音乐,电影,各行业专有词,唐诗,宋词,元曲,四书,三字经,天文,地理, 军事,女优,文言文 等中文词汇
程序在启动时会进行词库的加载,大约需要等待十几秒,之后就可以进行中文分词,程序默认采用的词库是 ciku2786019.dat,与云寻觅中文分词可执行程序在同一目录中,如果需要体验其它词库的中文分词效果,可替换云寻觅中文分词执行程序目录中的ciku.dat文件,重新启动程序即可!
云寻觅中文分词开发者小白救星 2013年于杭州 有任何疑问或建议请联系QQGroup:204725117
云寻觅中文分词完全开源,可以任意使用无任何限制!
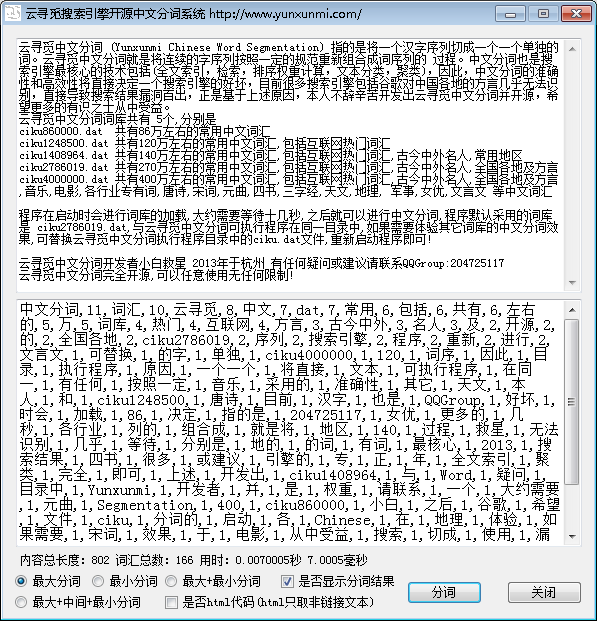
上述内容切分结果如下:
中文分词,11,词汇,10,云寻觅,8,中文,7,dat,7,常用,6,包括,6,共有,6,左右的,5,万,5,词库,4,热门,4,互联网,4,方言,3,古今中外,3,名人,3,及,2,开源,2,的,2,全国各地,2,ciku2786019,2,序列,2,搜索引擎,2,程序,2,重新,2,进行,2,文言文,1,可替换,1,的字,1,单独,1,ciku4000000,1,120,1,词序,1,因此,1,目录,1,执行程序,1,原因,1,一个一个,1,将直接,1,文本,1,可执行程序,1,在同一,1,有任何,1,按照一定,1,音乐,1,采用的,1,准确性,1,其它,1,天文,1,本人,1,和,1,ciku1248500,1,唐诗,1,目前,1,汉字,1,也是,1,QQGroup,1,好坏,1,时会,1,加载,1,86,1,决定,1,指的是,1,204725117,1,女优,1,更多的,1,几秒,1,各行业,1,列的,1,组合成,1,就是将,1,地区,1,140,1,过程,1,救星,1,无法识别,1,几乎,1,等待,1,分别是,1,地的,1,的词,1,有词,1,最核心,1,2013,1,搜索结果,1,四书,1,很多,1,或建议,1,引擎的,1,专,1,正,1,年,1,全文索引,1,聚类,1,完全,1,即可,1,上述,1,开发出,1,ciku1408964,1,与,1,Word,1,疑问,1,目录中,1,Yunxunmi,1,开发者,1,并,1,是,1,权重,1,请联系,1,一个,1,大约需要,1,元曲,1,Segmentation,1,400,1,ciku860000,1,小白,1,之后,1,谷歌,1,希望,1,文件,1,ciku,1,分词的,1,启动,1,各,1,Chinese,1,在,1,地理,1,体验,1,如果需要,1,宋词,1,效果,1,于,1,电影,1,从中受益,1,搜索,1,切成,1,使用,1,漏洞百出,1,默认,1,270,1,排序,1,检索,1,可以任意,1,无任何限制,1,十,1,有识之士,1,杭州,1,的规范,1,等,1,启动程序,1,军事,1,三字经,1,是基于,1,对中国,1,不辞辛苦,1,高效性,1,计算,1,分类,1,直接导致,1,的技术,1,就可以,1,中的,1,个,1,连续,1,5,1,将一个,1
云寻觅中文分词运行效果图如下:
下载地址:
云寻觅中文分词词库.rar
云寻觅中文分词代码.rar
云寻觅中文分词执行程序.rar