一、集合的基础操作
1,head头信息
//获取集合的第一个元素 val list = List(1,3,5) list.head //1
2,tail尾信息
//获取集合除去头元素之外的所有元素 val list = List(1,3,5) list.tail //List(3,5)
3,last最后元素
//获取集合的最后一个元素 val list = List(1,3,5) list.last //5
4,init初始化
//获取集合除去最后一个元素的前面所有元素 val list = List(1,3,5) println(list.init) //List(1,3)
5,reverse反转
//集合反转 val list = List(1,3,5) val resList: List[Int] = list.reverse //List(5, 3, 1)
6,sum、max、min
val list = List(1,3,5) println(list.sum) //9 求和 println(list.max) //5 最大值 println(list.min) //1 最小值
7,take(n)获取前n个元素
val list = List(1,3,5) val takeList = list.take(1) //List(1)
二、集合的高级操作
1,sortBy和sortWith
//sortBy只能按照升序排列,sortWith可自定义升降序 val list = List(10,9,1,4,7,3) val sortByList: List[Int] = list.sortBy(x=>x) //List(1, 3, 4, 7, 9, 10) val sortWithList: List[Int] = list.sortWith((left,right)=>left>right) //List(10, 9, 7, 4, 3, 1),如果要升序可以left<right
2,groupBy分组
//定义按照元素分组会生成对应的map val list = List(3,9,1,4,1,3) val groupByMap: Map[Int, List[Int]] = list.groupBy(x=>x) //Map(4 -> List(4), 1 -> List(1, 1), 9 -> List(9), 3 -> List(3, 3))
3,map映射
在Scala中可以通过map映射操作来解决:将集合中的每一个元素通过指定功能(函数)映射(转换)成新的结果集合。这里其实就是所谓的将函数作为参数传递给另外一个函数,这是函数式编程的特点
//将list集合中的每个元素*2 val list = List(1,3,5) val newList: List[Int] = list.map(_*2) //List(2,6,10)
4,flatMap扁平化
将集合中的每个元素的子元素映射到某个函数并返回新的集合。
val list = List(List(1,2,3),1,List(4,98)) val newList = list.flatMap { case item => //判断类型如果是List[Any]类型就转换 if (item.isInstanceOf[List[Any]]) { item.asInstanceOf[List[Any]] } else { //如果是普通类型就直接List(item)包装 List(item) } } println(newList) //List(1, 2, 3, 1, 4, 98)
5,filter过滤
//filter过滤获取为true的元素组成集合 val list = List(1, 25, 3, 11, 4, 98) val filterList: List[Int] = list.filter(_ > 20) //List(25, 98)
6,reduce化简
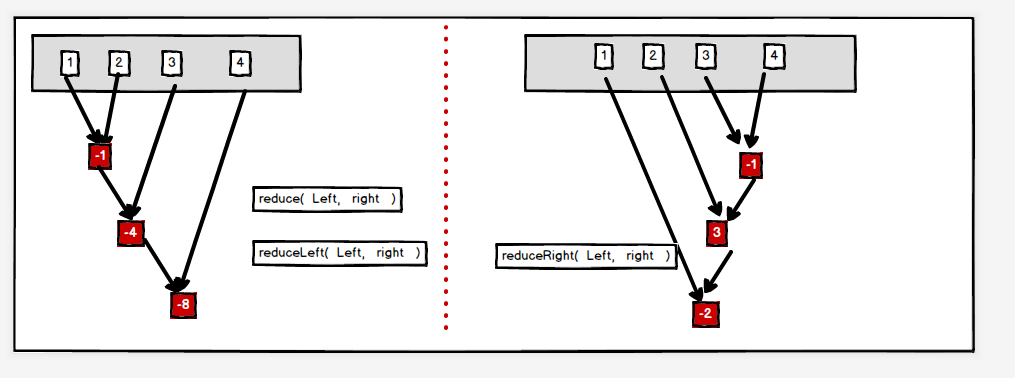
val list = List(1, 2, 3, 4) //1+2+3+4 10 val reduceLeft: Int = list.reduce(_ + _) //1-(2-(3-4)) -2 val reduceRight: Int = list.reduceRight(_ - _)
7,folder折叠
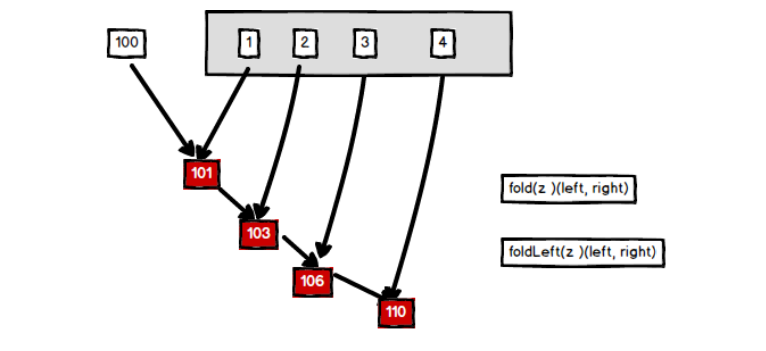
val list = List(1, 2, 3, 4) //集合List //(100,1, 2, 3, 4) =>化简 (((100-1)-2) -3)) – 4 = 90 println(list.foldLeft(100)(_-_)) // [函数柯里化(将多个参数,分别传递)] //(1,2,3,4,100) => 化简 1-(2-(3-(4-100))) = 98 println(list.foldRight(100)(_-_))
三、模式匹配
模式匹配语法中,采用match关键字声明,每个分支采用case关键字进行声明,当需要匹配时,会从第一个case分支开始,如果匹配成功,那么执行对应的逻辑代码,如果匹配不成功,继续执行下一个分支进行判断。如果所有case都不匹配,那么会执行case _ 分支,类似于Java中default语句
1,类型匹配
val oper = '-' val n1 = 20 val n2 = 10 var res = 0 oper match { case '+' => res = n1 + n2 case '-' => res = n1 - n2 case '*' => res = n1 * n2case '/' => res = n1 / n2 case _ => println("oper error") } println("res=" + res) //10
1)如果所有case都不匹配,那么会执行case _ 分支,类似于Java中default语句 2)如果所有case都不匹配,又没有写case _ 分支,那么会抛出MatchError 3)每个case中,不用break语句,自动中断case 4)可以在match中使用其它类型,而不仅仅是字符,可以是表达式 5)=> 等价于 java swtich 的 : 6)=> 后面的代码块到下一个 case, 是作为一个整体执行,可以使用{} 扩起来,也可以不扩。
2,匹配列表
for (list <- Array(List(0), List(1, 0), List(88), List(0, 0, 0), List(1, 0, 0))) { val result = list match { case 0 :: Nil => "0" // 匹配的 List(0) case x :: y :: Nil => x + " " + y // 匹配的是有两个元素的List(x,y) case 0 :: tail => "0 ..." // 匹配 以0 开头的后面有任意元素的List case x :: Nil => List(x) case _ => "something else" } println(result)
}
3,匹配元组
//请返回 (34, 89) => (89,34) for (pair <- Array((0, 1),(34,89), (1, 0), (1, 1),(1,0,2))) { val result = pair match { // case (0, _) => "0 ..." // 表示匹配 0 开头的二元组 case (y, 0) => y //表示匹配 0 结尾的二元组 case (x,y) => (y,x) case _ => "other" //.默认 } println(result) }
4,对象匹配
val number: Double = 36.0 //Square(6.0) number match { case Square(n) => println(n) // 6.0 case _ => println("nothing matched") } //说明 //1. unapply 为对象提取器 //2. apply 对象构建器 object Square { //静态性质 def unapply(z: Double): Option[Double] = { println("unapply 被调用 z =" + z) // 36.0 Some(math.sqrt(z)) // Some(6.0) } def apply(z: Double): Double = z * z }
1)构建对象时apply会被调用 ,比如 val n1 = Square(5) 2)当将 Square(n) 写在 case 后时[case Square(n) => xxx],会默认调用unapply 方法(对象提取器) 3)number 会被 传递给def unapply(z: Double) 的 z 形参 4)如果返回的是Some集合,则unapply提取器返回的结果会返回给 n 这个形参 5)case中对象的unapply方法(提取器)返回some集合则为匹配成功 6)返回None集合则为匹配失败
4,for循环
val map = Map("A"->1, "B"->0, "C"->3) //map集合 for ( (k, v) <- map ) { //每次遍历,取出k和v println(k + " -> " + v) } //说明: 只会取出 value= 0 的 k-v println("==================================") for ((k, 0) <- map) { println(k + " --> " + 0) } println("=====================================") //说明 取出 value 在 [0,3] 的范围的 key-val for ((k, v) <- map if v > 0 && v < 3) { println(k + " ---> " + v) }
5,样例类
1)样例类仍然是类 2)样例类用case关键字进行声明。 3)样例类是为模式匹配(对象)而优化的类 4)构造器中的每一个参数都成为val——除非它被显式地声明为var(不建议这样做) 5)在样例类对应的伴生对象中提供apply方法让你不用new关键字就能构造出相应的对象 6)提供unapply方法让模式匹配可以工作 7)将自动生成toString、equals、hashCode和copy方法(有点类似模板类,直接给生成,供程序员使用)
四、Scala泛型
1,scala的类和方法、函数都可以是泛型。 2,关于对类型边界的限定分为上边界和下边界(对类进行限制) 上边界:表达了泛型的类型必须是"某种类型"或某种类型的"子类",语法为“<:”, 下边界:表达了泛型的类型不做限,可以传任意值,语法为“>:”, 3, "<%" :view bounds可以进行某种神秘的转换,把你的类型在没有知觉的情况下转换成目标类型, 其实你可以认为view bounds是上下边界的加强和补充,语法为:"<%",要用到implicit进行隐式转换 4,"T:classTag":相当于动态类型,你使用时传入什么类型就是什么类型,(spark的程序的编译和运行是区分了Driver和Executor的,只有在运行的时候才知道完整的类型信息) 语法为:"[T:ClassTag]"下面有列子 5,逆变和协变:-T和+T(下面有具体例子)+T可以传入其子类和本身(与继承关系一致)-T可以传入其父类和本身(与继承的关系相反), 6,"T:Ordering" :表示将T变成Ordering[T],可以直接用其方法进行比大小,可完成排序等工作
/** * +T告诉scala允许协变,即 * 在类型检查期间,让scala接收某个类型及其子类 */ class MyList[+T] var list1 = new MyList[Int] //不写类型,默认为MyList[Nothing] var list2: MyList[Any] = null list2 = list1 /** * 告诉scala允许逆变 * 即允许接收某个类型及其超类 */ class MyList2[-T] var list3 = new MyList2[Any] var list4: MyList2[Int] = null list4 = list3
五、AKKA
概念参考:https://blog.csdn.net/pml18710973036/article/details/87807387
SparkDemo:https://blog.csdn.net/itcats_cn/article/details/91129794