关键词:rt_sched_class、SCHED_FIFO、SCHED_RR、sched_setscheduler()、sched_setaffinity()、RR_TIMESLICE。
本文主要关注实时进程,及FIFO和RR调度策略的区别。
主要分析rt_sched_class各函数;然后通过可视化,更直观明白的看出两者的区别,也通过RR_TIMESLICE可以看出时隙对调度的影响。
1. 实时进程FIFO和RR区别
Linux进程可以分为两大类:实时进程和普通进程。
实时进程与普通进程的根本不同之处:如果系统中有一个实时进程且可运行,那么调度器总是会选择它,除非另有一个优先级更高的实时进程。
实时进程分为两种:
SCHED_FIFO:没有时间片,在被调度器选择之后,可以运行任意长时间。
SCHED_RR:有时间片,其值在进程运行时会减少。在所有的时间段都到期后,则该值重置为初始值,而进程则置于队列末尾。这确保了在有几个优先级相同的SCHED_RR进程的情况下,它们总是依次执行。
参考资料:《linux进程调度方法(SCHED_OTHER,SCHED_FIFO,SCHED_RR)》
2. 实时调度类代码分析
实时调度器是整个调度器框架的一部分,所以首先需要了解其在框架中的位置;实时调度相关数据结构作为单度部分嵌入到全局中。
比如strcut sched_rt_entity和struct sched_entity对比嵌入到struct task_struct中;strcut rt_rq嵌入到struct rq中。
然后就是实时调度器最核心的区别,实时调度类struct sched_class rt_sched_class。
最后看看进程具备什么条件会使用rt_sched_class作为调度策略,以及rt_sched_class各成员被调用的时机。
下面的代码分析默认CONFIG_RT_GROUP_SCHED关闭。
2.1 实时调度体struct sched_rt_entity
struct sched_rt_entity表示一个可实时调度的实体,包含了完整的实时调度信息,是struct task_struct的一个成员。
struct task_struct { ... int prio, static_prio, normal_prio; unsigned int rt_priority; const struct sched_class *sched_class; struct sched_entity se; struct sched_rt_entity rt; #ifdef CONFIG_CGROUP_SCHED struct task_group *sched_task_group; #endif struct sched_dl_entity dl; ... } struct sched_rt_entity { struct list_head run_list; unsigned long timeout;----------------------------------------watchdog计数,用于判断当前进程时间是否超过RLIMIT_RTTIME。 unsigned long watchdog_stamp; unsigned int time_slice;--------------------------------------针对RR调度策略的调度时隙 struct sched_rt_entity *back;---------------------------------dequeue_rt_stack()中作为临时变量使用 #ifdef CONFIG_RT_GROUP_SCHED struct sched_rt_entity *parent;----------------------------指向上一层调度实体 /* rq on which this entity is (to be) queued: */ struct rt_rq *rt_rq;-----------------------------------当前实时调度实体所在的就绪队列 /* rq "owned" by this entity/group: */ struct rt_rq *my_q;------------------------------------当前实时调度实体的子调度实体所在的就绪队列 #endif }
2.2 实时就绪队列struct rt_rq
核心调度器用于管理活动进程的主要数据结构称之为就绪队列。各个CPU都有自身的就绪队列,各个活动进程只出现在一个就绪队列中。
在多个CPU上同时运行一个进程是不可能的。
就绪队列是全局调度器许多操作的起点,进程并不是由就绪队列的成员直接管理的。这是各个调度器类的职责,因此各个就绪队列中嵌入了特定于调度器类的子就绪队列。
struct rq用于表示就绪队列:
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned int nr_running;-----------------------指定了队列上可运行进程的数目,不考虑器有限激活调度类。
...
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX];------用于跟踪此前的负荷状态。
unsigned long last_load_update_tick;
...
/* capture load from *all* tasks on this cpu: */
struct load_weight load;-----------------------提供了就绪队列当前负荷的度量。队列的负荷本质上与队列上当前活动进程的数成正比,其中的各个进程又有优先级作为权重。
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;-----------------------------完全公平调度器嵌入的子就绪队列
struct rt_rq rt;-------------------------------实时调度器嵌入的子就绪队列
struct dl_rq dl;
...
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
struct task_struct *curr, *idle, *stop;--------curr当前运行的进程task_struct实例,idle空闲进程的task_struct实例。
unsigned long next_balance;
struct mm_struct *prev_mm;
unsigned int clock_skip_update;
u64 clock;-------------------------------------用于实现就绪队列自身的时钟。
u64 clock_task;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct root_domain *rd;
struct sched_domain *sd;
unsigned long cpu_capacity;
unsigned char idle_balance;
/* For active balancing */
int post_schedule;
int active_balance;
int push_cpu;
struct cpu_stop_work active_balance_work;
/* cpu of this runqueue: */
int cpu;
int online;
struct list_head cfs_tasks;
u64 rt_avg;
u64 age_stamp;
u64 idle_stamp;
u64 avg_idle;
/* This is used to determine avg_idle's max value */
u64 max_idle_balance_cost;
#endif
...
}
具有相同优先级的所有实时进程都保存在一个链表中,表头为active.queue[prio],而active.bitmap位图中的每个比特位对应于一个链表,凡包含了进程的链表,对应的比特位则置位。如果链表中没有进程,则对应的比特位不置位。
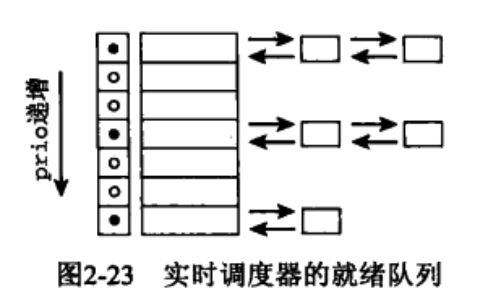
struct rt_prio_array是一组链表,每个优先级对应一个链表。还维护一个bitmap,其中实时进程优先级为0~99,再加上1bit的定界符。
当某个优先级别上有进程被插入列表时,相应的比特位就被置位。
通常用sched_find_first_bit()函数来查询该bitmap,他返回当前被置位的最高优先级的数组下标。
在实时调度中,运行进程根据优先级放到对应的队列里面,对于相同的优先级进程后面来的进程放到同一优先级队列的末尾。
对于FIFO/RR调度,各自的进程需要设置相关的属性。进程运行时,要根据task中的这些属性判断和设置,放弃CPU的时机。
struct rt_prio_array { DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */ struct list_head queue[MAX_RT_PRIO];---------------------------按优先级排列的实时调度器的就绪队列 }
核心调度器的就绪队列也包含了用于实时进程的子就绪队列,是一个嵌入的struct rt_rq实例。
struct rt_rq { struct rt_prio_array active; unsigned int rt_nr_running; #if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED struct { int curr; /* highest queued rt task prio */---------------最高实时任务的优先级 #ifdef CONFIG_SMP int next; /* next highest */------------------------------下一个实时任务最高优先级 #endif } highest_prio; #endif #ifdef CONFIG_SMP unsigned long rt_nr_migratory; unsigned long rt_nr_total; int overloaded; struct plist_head pushable_tasks; #endif int rt_queued; int rt_throttled;------------------------------------------------当前队列的实时调度是否受限 u64 rt_time;-----------------------------------------------------当前队列的累积运行时间 u64 rt_runtime;--------------------------------------------------当前队列的单个period周期内最大运行时间 /* Nests inside the rq lock: */ raw_spinlock_t rt_runtime_lock; #ifdef CONFIG_RT_GROUP_SCHED unsigned long rt_nr_boosted; struct rq *rq; struct task_group *tg; #endif }
2.3 实时调度器类struct sched_class
调度器类提供了通用调度器和各个调度方法之间的关联,
每个调度类都定义了一套操作方法struct sched_class,
struct sched_class { const struct sched_class *next; void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);-------向就绪队列添加一个新进程,在进程从睡眠状态变为运行状态时,即发生该操作。 void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);-------将一个进程从就绪队列去除,在进程从可运行状态切换到不可运行状态时,就会发生该操作。内核有可能因为其他理由将进程从就绪队列去除,比如进程的优先级可能需要改变。 void (*yield_task) (struct rq *rq);-------------------------------------------在进程想要自愿放弃对处理器的控制权时使用,这导致内核调用yield_task。 bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt); void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);-用一个新唤醒的进程来抢占当前进程 /* * It is the responsibility of the pick_next_task() method that will * return the next task to call put_prev_task() on the @prev task or * something equivalent. * * May return RETRY_TASK when it finds a higher prio class has runnable * tasks. */ struct task_struct * (*pick_next_task) (struct rq *rq, struct task_struct *prev);--------------------------------用于选择下一个将要运行的进程,而put_prev_task则在用另一个进程代替当前运行的进程之前调用。 void (*put_prev_task) (struct rq *rq, struct task_struct *p); #ifdef CONFIG_SMP int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags); void (*migrate_task_rq)(struct task_struct *p, int next_cpu); void (*post_schedule) (struct rq *this_rq); void (*task_waking) (struct task_struct *task); void (*task_woken) (struct rq *this_rq, struct task_struct *task); void (*set_cpus_allowed)(struct task_struct *p, const struct cpumask *newmask); void (*rq_online)(struct rq *rq); void (*rq_offline)(struct rq *rq); #endif void (*set_curr_task) (struct rq *rq);----------------------------------------在进程的调度策略发生变化时,需要调用set_curr_task。 void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);---------在每次激活周期性调度器时,由周期性调度器调用。 void (*task_fork) (struct task_struct *p);------------------------------------用于建立fork系统调用和调度器之间的关联 void (*task_dead) (struct task_struct *p); /* * The switched_from() call is allowed to drop rq->lock, therefore we * cannot assume the switched_from/switched_to pair is serliazed by * rq->lock. They are however serialized by p->pi_lock. */ void (*switched_from) (struct rq *this_rq, struct task_struct *task); void (*switched_to) (struct rq *this_rq, struct task_struct *task); void (*prio_changed) (struct rq *this_rq, struct task_struct *task, int oldprio); unsigned int (*get_rr_interval) (struct rq *rq, struct task_struct *task); void (*update_curr) (struct rq *rq); #ifdef CONFIG_FAIR_GROUP_SCHED void (*task_move_group) (struct task_struct *p, int on_rq); #endif }
实时调度器类对应rt_sched_class:
const struct sched_class rt_sched_class = { .next = &fair_sched_class, .enqueue_task = enqueue_task_rt,----------------------------将一个task放入到就绪队列头或者尾部 .dequeue_task = dequeue_task_rt,----------------------------将一个task从就绪队列末尾 .yield_task = yield_task_rt,--------------------------------主动放弃执行 .check_preempt_curr = check_preempt_curr_rt, .pick_next_task = pick_next_task_rt,------------------------核心调度器选择就绪队列的哪个任务将要被调度,prev是将要被调度出的任务,返回值是将要被调度的任务。 .put_prev_task = put_prev_task_rt,--------------------------当一个任务将要被调度出时执行 #ifdef CONFIG_SMP .select_task_rq = select_task_rq_rt,------------------------核心调度器给任务选定CPU,用于将任务分发到不同CPU上执行。 .set_cpus_allowed = set_cpus_allowed_rt, .rq_online = rq_online_rt, .rq_offline = rq_offline_rt, .post_schedule = post_schedule_rt, .task_woken = task_woken_rt, .switched_from = switched_from_rt, #endif .set_curr_task = set_curr_task_rt,------------------------当任务修改其调度类或修改其它任务组时,将调用这个函数。 .task_tick = task_tick_rt,----------------------------------当时钟中断出发时被调用,主要更新进程运行统计信息以及是否需要调度。 .get_rr_interval = get_rr_interval_rt, .prio_changed = prio_changed_rt, .switched_to = switched_to_rt, .update_curr = update_curr_rt, }
关于for_each_sched_rt_entity的使用很频繁,通过它可以遍历当前实时调度实体所在组的所有调度实体。
2.3.1 enqueue_task_rt()和dequeue_task_rt()
先了解一下两个函数的flag,有助于理解这两函数。
#define ENQUEUE_WAKEUP 0x01--------------当前进程刚变为可执行状态 #define ENQUEUE_HEAD 0x02----------------将当前进程放入就绪队列的头部 #ifdef CONFIG_SMP #define ENQUEUE_WAKING 0x04 /* sched_class::task_waking was called */ #else #define ENQUEUE_WAKING 0x00 #endif #define ENQUEUE_REPLENISH 0x08-------------- #define ENQUEUE_RESTORE 0x10 #define DEQUEUE_SLEEP 0x01---------------当前进程不再可运行 #define DEQUEUE_SAVE 0x02
首先这两个函数的调用轨迹是:enqueue_task()->enqueue_task_rt()和dequeue_task()->dequeue_task_rt()。
enqueue_task_rt会根据需要将实时调度实体移到链表头或尾,但是dequeue_task_rt()一定会移到链表末尾。两者都会先判断是否在当前rt_rq上,如果在的话需要先移除。
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head) { struct rt_rq *rt_rq = rt_rq_of_se(rt_se); struct rt_prio_array *array = &rt_rq->active; struct rt_rq *group_rq = group_rt_rq(rt_se); struct list_head *queue = array->queue + rt_se_prio(rt_se);-----------通过rt_se得出当前进程的优先级,进而通过array->queue偏移得到当前优先级所在的链表。 ... if (head) list_add(&rt_se->run_list, queue);--------------------------------根据head来执行是插入头部还是插入尾部 else list_add_tail(&rt_se->run_list, queue); __set_bit(rt_se_prio(rt_se), array->bitmap);--------------------------当前优先级对应的bitmap置位 inc_rt_tasks(rt_se, rt_rq);-------------------------------------------更新当前rt_rq的统计信息,比如最高优先级、进程总数等等。 } static void __dequeue_rt_entity(struct sched_rt_entity *rt_se) { struct rt_rq *rt_rq = rt_rq_of_se(rt_se); struct rt_prio_array *array = &rt_rq->active; list_del_init(&rt_se->run_list);--------------------------------------将当前进程在rt_rq->active->queue上优先级对应列表上节点删除 if (list_empty(array->queue + rt_se_prio(rt_se))) __clear_bit(rt_se_prio(rt_se), array->bitmap);--------------------如果当前优先级列表为空,则bitmap清零。 dec_rt_tasks(rt_se, rt_rq);-------------------------------------------类似于inc_rt_tasks反操作。 } /* * Because the prio of an upper entry depends on the lower * entries, we must remove entries top - down. */ static void dequeue_rt_stack(struct sched_rt_entity *rt_se) { struct sched_rt_entity *back = NULL; for_each_sched_rt_entity(rt_se) { rt_se->back = back; back = rt_se; } dequeue_top_rt_rq(rt_rq_of_se(back)); for (rt_se = back; rt_se; rt_se = rt_se->back) { if (on_rt_rq(rt_se))--------------------------------------------判断当前的实时调度实体是否已经在rt_rq上,如果已经在在从中摘除。 __dequeue_rt_entity(rt_se); } } static void enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head) { struct rq *rq = rq_of_rt_se(rt_se); dequeue_rt_stack(rt_se); for_each_sched_rt_entity(rt_se) __enqueue_rt_entity(rt_se, head); enqueue_top_rt_rq(&rq->rt); } static void dequeue_rt_entity(struct sched_rt_entity *rt_se) { struct rq *rq = rq_of_rt_se(rt_se); dequeue_rt_stack(rt_se); for_each_sched_rt_entity(rt_se) { struct rt_rq *rt_rq = group_rt_rq(rt_se); if (rt_rq && rt_rq->rt_nr_running) __enqueue_rt_entity(rt_se, false);-----------------------------一定会被移到链表尾部 } enqueue_top_rt_rq(&rq->rt); } /* * Adding/removing a task to/from a priority array: */ static void enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags) { struct sched_rt_entity *rt_se = &p->rt; if (flags & ENQUEUE_WAKEUP) rt_se->timeout = 0; enqueue_rt_entity(rt_se, flags & ENQUEUE_HEAD);------------------------将当前实时调度实体添加到对应优先级链表上,添加到头部还是尾部蜂聚flags是否包含ENQUEUE_HEAD来判断。 if (!task_current(rq, p) && p->nr_cpus_allowed > 1) enqueue_pushable_task(rq, p); } static void dequeue_task_rt(struct rq *rq, struct task_struct *p, int flags) { struct sched_rt_entity *rt_se = &p->rt; update_curr_rt(rq); dequeue_rt_entity(rt_se);----------------------------------------------这里只是将当前实时调度实体移到链表尾部 dequeue_pushable_task(rq, p); }
2.3.2 update_curr_rt()
task_sched_runtime()->update_curr_rt()
update_curr_rt()除了更新各种运行时间、总执行时间等等,还会根据时间片使用情况设置当前进程是否可以被调度。
static void update_curr_rt(struct rq *rq) { struct task_struct *curr = rq->curr; struct sched_rt_entity *rt_se = &curr->rt; u64 delta_exec; if (curr->sched_class != &rt_sched_class)---------------------------保证当前进程的调度策略是rt_sched_class return; delta_exec = rq_clock_task(rq) - curr->se.exec_start;---------------当前进程的单次执行时间 if (unlikely((s64)delta_exec <= 0)) return; schedstat_set(curr->se.statistics.exec_max, max(curr->se.statistics.exec_max, delta_exec));-----------调度统计信息的取最大单次执行时间 curr->se.sum_exec_runtime += delta_exec;----------------------------当前进程的总执行时间 account_group_exec_runtime(curr, delta_exec); curr->se.exec_start = rq_clock_task(rq);----------------------------更新执行开始时间 cpuacct_charge(curr, delta_exec); sched_rt_avg_update(rq, delta_exec); if (!rt_bandwidth_enabled())----------------------------------------当前系统是否打开了RT带宽限制? return; for_each_sched_rt_entity(rt_se) {-----------------------------------遍历组调度实体,更新统计信息 struct rt_rq *rt_rq = rt_rq_of_se(rt_se); if (sched_rt_runtime(rt_rq) != RUNTIME_INF) { raw_spin_lock(&rt_rq->rt_runtime_lock); rt_rq->rt_time += delta_exec;-------------------------------实时就绪队列的总执行时间 if (sched_rt_runtime_exceeded(rt_rq))-----------------------当前rt_rq的运行时间是否超过了分配时间片,如果超过了则将当前进程设置为可调度TIF_NEED_RESCHED。 resched_curr(rq); raw_spin_unlock(&rt_rq->rt_runtime_lock); } } }
2.3.3 yield_task_rt()
yield_task_rt()表示当前进程主动暂时放弃执行,调用轨迹是do_sched_yield()->yield_task_rt()。
从下面的代码可以看出,操作很简单,就是将当前的实时调度实体移到所在优先级链表的尾部。
/* * Put task to the head or the end of the run list without the overhead of * dequeue followed by enqueue. */ static void requeue_rt_entity(struct rt_rq *rt_rq, struct sched_rt_entity *rt_se, int head) { if (on_rt_rq(rt_se)) { struct rt_prio_array *array = &rt_rq->active; struct list_head *queue = array->queue + rt_se_prio(rt_se); if (head) list_move(&rt_se->run_list, queue);---------------------------移到队列头部 else list_move_tail(&rt_se->run_list, queue);----------------------移到队列尾部 } } static void requeue_task_rt(struct rq *rq, struct task_struct *p, int head) { struct sched_rt_entity *rt_se = &p->rt; struct rt_rq *rt_rq; for_each_sched_rt_entity(rt_se) { rt_rq = rt_rq_of_se(rt_se); requeue_rt_entity(rt_rq, rt_se, head); } } static void yield_task_rt(struct rq *rq) { requeue_task_rt(rq, rq->curr, 0);---------------------------------------0表示移到链表的末尾 }
2.3.4 task_tick_rt()
task_tick_rt()对于SCHED_FIFO基本不起作用,因为FIFO没有时间片的概念,调用轨迹是scheduler_tick()->task_tick_rt()。
对于采取RR调度策略的进程,每次执行的时间片是由sched_rr_timeslice决定的。
所以sched_rr_timeslice对于RR是一个关键参数,它首先有一个初始值RR_TIMESLICE,注意这个值的单位是jiffies。
#define RR_TIMESLICE (100 * HZ / 1000)----------------这个定义能保证RR_TIMESLICE无论是多少,其对应的时间总是100ms。
int sched_rr_timeslice = RR_TIMESLICE; static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued) { struct sched_rt_entity *rt_se = &p->rt; update_curr_rt(rq); watchdog(rq, p); /* * RR tasks need a special form of timeslice management. * FIFO tasks have no timeslices. */ if (p->policy != SCHED_RR)-----------------------------------只有RR调度策略有time_slice概念 return; if (--p->rt.time_slice)--------------------------------------当前可用时间片在变小,每次减少一个tick。不为0表示当前的时间片没有用完,不需要考虑主动放弃。 return; p->rt.time_slice = sched_rr_timeslice;-----------------------等于time_slice复位。 /* * Requeue to the end of queue if we (and all of our ancestors) are not * the only element on the queue */ for_each_sched_rt_entity(rt_se) { if (rt_se->run_list.prev != rt_se->run_list.next) { requeue_task_rt(rq, p, 0);---------------------------将当前进程移动到链表尾部 resched_curr(rq);------------------------------------设置当前进程为TIF_NEED_RESCHED,表示可以被调度。 return; } } }
sched_rr_timeslice的另一个相关点是通过/proc/sys/kernel/sched_rr_timeslice_ms进行修改。
这里有需要注意的地方,写入的参数单位是ms,但是读出来的单位是当前系统的jiffies。
int sched_rr_handler(struct ctl_table *table, int write, void __user *buffer, size_t *lenp, loff_t *ppos) { int ret; static DEFINE_MUTEX(mutex); mutex_lock(&mutex); ret = proc_dointvec(table, write, buffer, lenp, ppos); /* make sure that internally we keep jiffies */ /* also, writing zero resets timeslice to default */ if (!ret && write) { sched_rr_timeslice = sched_rr_timeslice <= 0 ? RR_TIMESLICE : msecs_to_jiffies(sched_rr_timeslice);----------写入的参数经过msecs_to_jiffies将ms转换成了jiffes。 } mutex_unlock(&mutex); return ret; } static struct ctl_table kern_table[] = { ... { .procname = "sched_rr_timeslice_ms", .data = &sched_rr_timeslice,-------------------------------读的参数单位是jiffies .maxlen = sizeof(int), .mode = 0644, .proc_handler = sched_rr_handler, }, ... { } }
2.3.5 get_rr_interval_rt()
这个函数很简单,调用轨迹是do_sched_rr_get_interval()->get_rr_interval_rt()。
就是检查当前的调度策略是不是RR,然后返回sched_rr_timeslice参数。
static unsigned int get_rr_interval_rt(struct rq *rq, struct task_struct *task) { /* * Time slice is 0 for SCHED_FIFO tasks */ if (task->policy == SCHED_RR) return sched_rr_timeslice; else return 0; }
2.3.6 check_preempt_curr_rt()
check_preempt_curr_rt()用于检查是否满足可抢占的条件,调用轨迹是check_preempt_curr()->check_preempt_curr_rt()。
static void check_preempt_curr_rt(struct rq *rq, struct task_struct *p, int flags) { if (p->prio < rq->curr->prio) {--------------------------------如果给定进程p实时进程的优先级小于就绪队列当前进程优先级,说明p的优先级更高。 resched_curr(rq);------------------------------------------将就绪队列上的当前进程设置为TIF_NEED_RESCHED。 return; } #ifdef CONFIG_SMP /* * If: * * - the newly woken task is of equal priority to the current task * - the newly woken task is non-migratable while current is migratable * - current will be preempted on the next reschedule * * we should check to see if current can readily move to a different * cpu. If so, we will reschedule to allow the push logic to try * to move current somewhere else, making room for our non-migratable * task. */ if (p->prio == rq->curr->prio && !test_tsk_need_resched(rq->curr)) check_preempt_equal_prio(rq, p); #endif }
2.3.7 pick_next_task_rt()和put_next_task_rt()
pick_next_task_rt()挑选下一个要被执行的实时任务,调用轨迹是schedule()->__schedule()->pick_next_task()->pick_next_task_rt()。
static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq, struct rt_rq *rt_rq) { struct rt_prio_array *array = &rt_rq->active; struct sched_rt_entity *next = NULL; struct list_head *queue; int idx; idx = sched_find_first_bit(array->bitmap);-----------------------------获取当前实时就绪队列上的最高优先级,idx对应了优先级 BUG_ON(idx >= MAX_RT_PRIO); queue = array->queue + idx;--------------------------------------------获取最高优先级对应的链表 next = list_entry(queue->next, struct sched_rt_entity, run_list);------从链表头获取实时调度实体 return next; } static struct task_struct *_pick_next_task_rt(struct rq *rq) { struct sched_rt_entity *rt_se; struct task_struct *p; struct rt_rq *rt_rq = &rq->rt; do { rt_se = pick_next_rt_entity(rq, rt_rq);---------------------------从rt_rq获取最高优先级对应的实时调度实体 BUG_ON(!rt_se); rt_rq = group_rt_rq(rt_se); } while (rt_rq); p = rt_task_of(rt_se); p->se.exec_start = rq_clock_task(rq);---------------------------------更新当前进程的开始执行事件 return p; } static struct task_struct * pick_next_task_rt(struct rq *rq, struct task_struct *prev) { struct task_struct *p; struct rt_rq *rt_rq = &rq->rt; ... /* * We may dequeue prev's rt_rq in put_prev_task(). * So, we update time before rt_nr_running check. */ if (prev->sched_class == &rt_sched_class) update_curr_rt(rq); if (!rt_rq->rt_queued) return NULL; put_prev_task(rq, prev);----------------调用put_prev_task_rt() p = _pick_next_task_rt(rq);-------------从rq中选择最合适的进程,并返回进程描述符 /* The running task is never eligible for pushing */ dequeue_pushable_task(rq, p); queue_push_tasks(rq); return p; }
put_prev_task_rt()用另一个进程代替当前运行的进程,调用轨迹是put_prev_task()->put_prev_task_rt()。
static void put_prev_task_rt(struct rq *rq, struct task_struct *p) { update_curr_rt(rq); /* * The previous task needs to be made eligible for pushing * if it is still active */ if (on_rt_rq(&p->rt) && p->nr_cpus_allowed > 1) enqueue_pushable_task(rq, p); }
2.3.8 prio_changed_rt()
prio_changed_rt()用于判断修改了进程优先级之后,判断是否需要重新调度,调用轨迹是check_class_changed()->prio_changed_rt()。
/* * Priority of the task has changed. This may cause * us to initiate a push or pull. */ static void prio_changed_rt(struct rq *rq, struct task_struct *p, int oldprio) { if (!task_on_rq_queued(p)) return; if (rq->curr == p) { #ifdef CONFIG_SMP /* * If our priority decreases while running, we * may need to pull tasks to this runqueue. */ if (oldprio < p->prio) queue_pull_task(rq); /* * If there's a higher priority task waiting to run * then reschedule. */ if (p->prio > rq->rt.highest_prio.curr) resched_curr(rq); #else /* For UP simply resched on drop of prio */ if (oldprio < p->prio)----------------------------------如果其优先级变大,说明优先级变低了,需要重新调度。 resched_curr(rq); #endif /* CONFIG_SMP */ } else { /* * This task is not running, but if it is * greater than the current running task * then reschedule. */ if (p->prio < rq->curr->prio)---------------------------如果进程p的优先级比rq->curr的优先级大的话,说明rq->curr的优先级较低,需要设置重新调度。 resched_curr(rq); } }
2.3.9 switched_to_rt()
switched_to_rt()用于修改了调度类的情况,调用轨迹是check_class_changed()->switched_to_rt()。
/* * When switching a task to RT, we may overload the runqueue * with RT tasks. In this case we try to push them off to * other runqueues. */ static void switched_to_rt(struct rq *rq, struct task_struct *p) { /* * If we are already running, then there's nothing * that needs to be done. But if we are not running * we may need to preempt the current running task. * If that current running task is also an RT task * then see if we can move to another run queue. */ if (task_on_rq_queued(p) && rq->curr != p) { #ifdef CONFIG_SMP if (p->nr_cpus_allowed > 1 && rq->rt.overloaded) queue_push_tasks(rq); #endif /* CONFIG_SMP */ if (p->prio < rq->curr->prio) resched_curr(rq); } }
2.3.10 set_curr_task_rt()
static void set_curr_task_rt(struct rq *rq) { struct task_struct *p = rq->curr; p->se.exec_start = rq_clock_task(rq); /* The running task is never eligible for pushing */ dequeue_pushable_task(rq, p); }
2.4 RT Bandwith
RT进程和普通进程之间有一个分配带宽的比例,默认情况是RT:CFS=95:5。
通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us来设置。
如果设置sched_rt_runtime_us为-1,则禁止对RT进程的带宽限制。
2.4.1 RT进程带宽初始化
在系统开机的时候start_kernel()->sched_init()->init_rt_bandwidth()进行带宽的设置。
init_rt_bandwidth()将sysctl_sched_rt_period和sysctl_sched_rt_runtime设置到def_rt_bandwidth,并初始化def_rt_bandwidth->rt_pediod_timer,处理函数是sched_rt_period_timer()。
void __init sched_init(void) { ... init_rt_bandwidth(&def_rt_bandwidth, global_rt_period(), global_rt_runtime()); ... } void init_rt_bandwidth(struct rt_bandwidth *rt_b, u64 period, u64 runtime) { rt_b->rt_period = ns_to_ktime(period); rt_b->rt_runtime = runtime; raw_spin_lock_init(&rt_b->rt_runtime_lock); hrtimer_init(&rt_b->rt_period_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL); rt_b->rt_period_timer.function = sched_rt_period_timer; }
start_rt_bandwidth启动rt_bandwidth->rt_period_timer,周期为rt_bandwidth->rt_period,这就保证每隔一定时间回去检查超时问题。
static void start_rt_bandwidth(struct rt_bandwidth *rt_b) { if (!rt_bandwidth_enabled() || rt_b->rt_runtime == RUNTIME_INF) return; raw_spin_lock(&rt_b->rt_runtime_lock); if (!rt_b->rt_period_active) { rt_b->rt_period_active = 1; hrtimer_forward_now(&rt_b->rt_period_timer, rt_b->rt_period); hrtimer_start_expires(&rt_b->rt_period_timer, HRTIMER_MODE_ABS_PINNED); } raw_spin_unlock(&rt_b->rt_runtime_lock); }
sched_rt_period_timer是rt_bandwidth->rt_period_timer定时器的超时函数。
每个周期到达时,将rt_rq->rt_time更新一下,并且根据需要将当前进程重新调度一下。如果当前rt_rq处于idle状态,那么可以停止相应的timer。
static enum hrtimer_restart sched_rt_period_timer(struct hrtimer *timer) { struct rt_bandwidth *rt_b = container_of(timer, struct rt_bandwidth, rt_period_timer); int idle = 0; int overrun; raw_spin_lock(&rt_b->rt_runtime_lock); for (;;) { overrun = hrtimer_forward_now(timer, rt_b->rt_period);--------------overrun表示定时器执行已经超过了interval时间,覆盖到下一次定时一部分,overrun是覆盖次数。 if (!overrun)-------------------------------------------------------overrun为0跳出本次for循环 break; raw_spin_unlock(&rt_b->rt_runtime_lock); idle = do_sched_rt_period_timer(rt_b, overrun);---------------------更新对应rt_rq->rt_time,并且根据需要设置对应进程重新调度。 raw_spin_lock(&rt_b->rt_runtime_lock); } if (idle) rt_b->rt_period_active = 0; raw_spin_unlock(&rt_b->rt_runtime_lock); return idle ? HRTIMER_NORESTART : HRTIMER_RESTART;-----------------------根据是否idle决定是否重启rt_bandwidth->rt_period_timer。 } static int do_sched_rt_period_timer(struct rt_bandwidth *rt_b, int overrun) { int i, idle = 1, throttled = 0; const struct cpumask *span; span = sched_rt_period_mask(); for_each_cpu(i, span) { int enqueue = 0; struct rt_rq *rt_rq = sched_rt_period_rt_rq(rt_b, i); struct rq *rq = rq_of_rt_rq(rt_rq); raw_spin_lock(&rq->lock); if (rt_rq->rt_time) {-----------------------------------------------------当前累计执行时间不为0 u64 runtime; raw_spin_lock(&rt_rq->rt_runtime_lock); if (rt_rq->rt_throttled) balance_runtime(rt_rq);-------------------------------------------如果当前CPU的rt_rq->rt_runtime时间用完,尝试从其它CPU借时间。 runtime = rt_rq->rt_runtime;------------------------------------------每一个周期允许运行的最长时间 rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime);---------------如果overrun为1,那么rt_rq->rt_time减去一个runtime,否则rt_rq->rt_time保持不变。 if (rt_rq->rt_throttled && rt_rq->rt_time < runtime) { rt_rq->rt_throttled = 0; enqueue = 1; if (rt_rq->rt_nr_running && rq->curr == rq->idle) rq_clock_skip_update(rq, false); } if (rt_rq->rt_time || rt_rq->rt_nr_running) idle = 0; raw_spin_unlock(&rt_rq->rt_runtime_lock); } else if (rt_rq->rt_nr_running) { idle = 0; if (!rt_rq_throttled(rt_rq)) enqueue = 1; } if (rt_rq->rt_throttled) throttled = 1; if (enqueue) sched_rt_rq_enqueue(rt_rq);--------------------------------------标记当前rt_rq所在进程为TIF_NEED_RESCHED raw_spin_unlock(&rq->lock); } if (!throttled && (!rt_bandwidth_enabled() || rt_b->rt_runtime == RUNTIME_INF)) return 1; return idle; }
2.4.2 sysctl调节RT进程带宽及占比
系统启动是有默认参数,还可以通过sysct进行设置,l操作交给sched_rt_handler(),
unsigned int sysctl_sched_rt_period = 1000000; int sysctl_sched_rt_runtime = 950000; static struct ctl_table kern_table[] = { ... { .procname = "sched_rt_period_us", .data = &sysctl_sched_rt_period, .maxlen = sizeof(unsigned int), .mode = 0644, .proc_handler = sched_rt_handler, }, { .procname = "sched_rt_runtime_us", .data = &sysctl_sched_rt_runtime, .maxlen = sizeof(int), .mode = 0644, .proc_handler = sched_rt_handler, }, ... } int sched_rt_handler(struct ctl_table *table, int write, void __user *buffer, size_t *lenp, loff_t *ppos) { int old_period, old_runtime; static DEFINE_MUTEX(mutex); int ret; mutex_lock(&mutex); old_period = sysctl_sched_rt_period; old_runtime = sysctl_sched_rt_runtime; ret = proc_dointvec(table, write, buffer, lenp, ppos); if (!ret && write) { ret = sched_rt_global_validate();------------验证sysctl_sched_rt_period和sysctl_sched_rt_runtime有效性 if (ret) goto undo; ... ret = sched_rt_global_constraints();---------更新每个CPU的rt_rq->rt_runtime if (ret) goto undo; sched_rt_do_global();------------------------设置sysctl_sched_rt_runtime和sysctl_sched_rt_period到def_rt_bandwidth中 sched_dl_do_global(); } if (0) { undo: sysctl_sched_rt_period = old_period; sysctl_sched_rt_runtime = old_runtime; } mutex_unlock(&mutex); return ret; } static void sched_rt_do_global(void) { def_rt_bandwidth.rt_runtime = global_rt_runtime(); def_rt_bandwidth.rt_period = ns_to_ktime(global_rt_period()); } static inline u64 global_rt_period(void) { return (u64)sysctl_sched_rt_period * NSEC_PER_USEC; } static inline u64 global_rt_runtime(void) { if (sysctl_sched_rt_runtime < 0) return RUNTIME_INF; return (u64)sysctl_sched_rt_runtime * NSEC_PER_USEC; } static inline u64 sched_rt_runtime(struct rt_rq *rt_rq) { return rt_rq->rt_runtime; } static inline u64 sched_rt_period(struct rt_rq *rt_rq) { return ktime_to_ns(def_rt_bandwidth.rt_period); }
rt_bandwidth_enabled()用于判断当前系统是否打开了RT带宽限制,这也是设置sched_rt_runtime_us为-1就可以关闭带宽限制的原因。
sched_rt_runtime_exceeded()判断当前rt_rq是否超出分配的可执行时间。
static inline int rt_bandwidth_enabled(void) { return sysctl_sched_rt_runtime >= 0; } static int sched_rt_runtime_exceeded(struct rt_rq *rt_rq) { u64 runtime = sched_rt_runtime(rt_rq);------------------------获取rt_rq->rt_runtime,也即当前CPU的RT进程总执行时间的限制。 ... runtime = sched_rt_runtime(rt_rq); if (runtime == RUNTIME_INF) return 0; if (rt_rq->rt_time > runtime) {-------------------------------当前CUP的RT进程执行时间已经超出执行时间限制。 struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq); /* * Don't actually throttle groups that have no runtime assigned * but accrue some time due to boosting. */ if (likely(rt_b->rt_runtime)) { rt_rq->rt_throttled = 1; printk_deferred_once("sched: RT throttling activated "); } else { /* * In case we did anyway, make it go away, * replenishment is a joke, since it will replenish us * with exactly 0 ns. */ rt_rq->rt_time = 0; } if (rt_rq_throttled(rt_rq)) { sched_rt_rq_dequeue(rt_rq); return 1;----------------------------------------------表示当前rt_rq的执行事件已经超额,需要放弃控制权。 } } return 0; }
可能导致重新调度的点包括,update_curr_rt()中sched_rt_runtime_exceeded()时间用完。
或者rt_bandwidth->rt_period_timer超时。
或者实时进程改变了优先级switched_to_rt()等等。
这也是设置RT带宽参数能保证RT进程用完执行事件后,留一段事件给普通进程使用的原因。
2.5 何时进程会采用rt_sched_class调度类
2.5.1 哪些情况设置rt_sched_class调度策略
主要在do_fork()和sched_setscheduler()两个函数中进行调度器相关设置。
2.5.1.1 shed_fork
sched_fork主要被系统调用fork调用,do_fork()->copy_process()->sched_fork()。
sched_fork()主要进行调度器相关设置,其中一个重要操作就是设置调度器类。
static inline int rt_prio(int prio) { if (unlikely(prio < MAX_RT_PRIO)) return 1; return 0; } int sched_fork(unsigned long clone_flags, struct task_struct *p) { ... if (dl_prio(p->prio)) { put_cpu(); return -EAGAIN; } else if (rt_prio(p->prio)) {----------------------当前进程task_struct->prio小于100,使用rt_sched_class。 p->sched_class = &rt_sched_class; } else { p->sched_class = &fair_sched_class;-------------其它情况使用公平调度类fair_sched_class。 } ... }
2.5.1.2 sched_setscheduler
内核中有很多直接调用sched_setscheduler()设置进程的调度策略和优先级的地方,但是更常用的方法是通过系统调用sys_sched_setscheduler()在用户空间对进程进行设置。
在调用__setscheduler()进行设置之前,__sched_setscheduler()进行了一些有效性检查。
然后根据task_struct->prio来判断采用哪个调度类,对于实时进程需要满足条件prio<100。
static int __sched_setscheduler(struct task_struct *p, const struct sched_attr *attr, bool user, bool pi) { int newprio = dl_policy(attr->sched_policy) ? MAX_DL_PRIO - 1 : MAX_RT_PRIO - 1 - attr->sched_priority;--------------------这里的newprio已经经过了转换,是99-sched_param->sched_priority。DL就对应-1。 int retval, oldprio, oldpolicy = -1, queued, running; int new_effective_prio, policy = attr->sched_policy; ... /* * Valid priorities for SCHED_FIFO and SCHED_RR are * 1..MAX_USER_RT_PRIO-1, valid priority for SCHED_NORMAL, * SCHED_BATCH and SCHED_IDLE is 0. */ if ((p->mm && attr->sched_priority > MAX_USER_RT_PRIO-1) || (!p->mm && attr->sched_priority > MAX_RT_PRIO-1))----------------因为MAX_USER_RT_PRIO和MAX_RT_PRIO都为100,所以只要sched_priority大于99都返回-EINVAL。 return -EINVAL; if ((dl_policy(policy) && !__checkparam_dl(attr)) || (rt_policy(policy) != (attr->sched_priority != 0)))--------------FIFO和RR调度策略的sched_priority不能为0,所以范围变成1~99。 return -EINVAL; ... }
调用路径如下sched_setscheduler()->__sched_setscheduler()->__setscheduler(),下面就来看看如何设置调度策略和优先级的。
#define MAX_USER_RT_PRIO 100 #define MAX_RT_PRIO MAX_USER_RT_PRIO static inline int rt_prio(int prio) { if (unlikely(prio < MAX_RT_PRIO))------------------------------------判断当前优先级是否是实时进程优先级,进而判断当前进程是否是实时进程。从0~99即为实时进程。 return 1; return 0; } static inline int rt_policy(int policy) { if (policy == SCHED_FIFO || policy == SCHED_RR)----------------------FIFO和RR两者是实时调度策略 return 1; return 0; } static inline int task_has_rt_policy(struct task_struct *p) { return rt_policy(p->policy); } static inline int __normal_prio(struct task_struct *p) { return p->static_prio; } /* * Calculate the expected normal priority: i.e. priority * without taking RT-inheritance into account. Might be * boosted by interactivity modifiers. Changes upon fork, * setprio syscalls, and whenever the interactivity * estimator recalculates. */ static inline int normal_prio(struct task_struct *p) { int prio; if (task_has_rt_policy(p)) prio = MAX_RT_PRIO-1 - p->rt_priority; else prio = __normal_prio(p); return prio; } static void __setscheduler_params(struct task_struct *p, int policy, int prio) { p->policy = policy;-----------------------------------------设置进程调度策略 p->rt_priority = prio;--------------------------------------设置实时进程优先级 p->normal_prio = normal_prio(p);----------------------------如果是普通进程等于task_struct->static_prio;如果使用了FIFO或者RR调度策略,等于99-rt_priority。 set_load_weight(p); } /* Actually do priority change: must hold rq lock. */ static void __setscheduler(struct rq *rq, struct task_struct *p, int policy, int prio)---------------p表示当前进程task_struct,policy表示调度策略,prio表示优先级。 { __setscheduler_params(p, policy, prio); /* we are holding p->pi_lock already */ p->prio = rt_mutex_getprio(p); if (rt_prio(p->prio)) p->sched_class = &rt_sched_class; else p->sched_class = &fair_sched_class; }
3. SCHED_FIFO和SCHED_RR的测试
3.1 构造测试用例
构造测试之前,首先借用perf timechart测试代码,然后稍微修改一下分成机组进行对比测试。
1. 初始情况:普通进程,默认调度策略SCHED_NORMAL。
2. 设置FIFO调度策略:设置为SCHED_FIFO,并且优先级为49。
3. 设置FIFO并CPU亲和性:在2的基础上,固定进程在CPU0上。
4. 设置RR调度策略:设置为SCHED_RR,并且优先级为49。
5. 设置RR并CPU亲和性:在4的基础上,固定进程在CPU0上。
代码如下,主要是对颜色部分带代码进行组合排列:
#define _GNU_SOURCE #include <stdio.h> #include <sched.h> #include <stdlib.h> #include <unistd.h> void test_little(void) { int i,j; for(i = 0; i < 30000000; i++) j=i; } void test_medium(void) { int i,j; for(i = 0; i < 60000000; i++) j=i; } void test_high(void) { int i,j; for(i = 0; i < 90000000; i++) j=i; } void test_hi(void) { int i,j; for(i = 0; i < 120000000; i++) j=i; } int main(void) { int i, pid, result; cpu_set_t mask; struct sched_param param; //Set CPU affinity. CPU_ZERO(&mask); CPU_SET(0, &mask); if(sched_setaffinity(0, sizeof(cpu_set_t), &mask) == -1) { exit(EXIT_FAILURE); } //Set scheduler and priority. param.sched_priority = 50; sched_setscheduler(0, SCHED_FIFO, ¶m); for(i = 0; i<2; i++) { result = fork(); if(result>0) printf("i=%d parent parent=%d current=%d child=%d ", i, getppid(), getpid(), result); else printf("i=%d child parent=%d current=%d ", i, getppid(), getpid()); if(i==0) { test_little(); sleep(1); } else { test_medium(); sleep(1); } } pid = wait(NULL); test_high(); printf("pid=%d wait=%d ", getpid(), pid); sleep(1); pid = wait(NULL); test_hi(); printf("pid=%d wait=%d ", getpid(), pid); return 0; }
3.1.1 设置CPU亲和性
设置CPU亲和性的API是sched_setaffinity()。
#define _GNU_SOURCE
#include <sched.h>void CPU_ZERO(cpu_set_t *set);-------------------------------初始化一个空cpu_set_t
void CPU_SET(int cpu, cpu_set_t *set);-----------------------将cpu加入到set
void CPU_CLR(int cpu, cpu_set_t *set);-----------------------将cpu从set移除
int CPU_ISSET(int cpu, cpu_set_t *set); ----------------------判断cpu是否在set中,在返回true。
int sched_setaffinity(pid_t pid, size_t len, cpu_set_t *set);
示范如下:
cpu_set_t mask; struct sched_param param; //Set CPU affinity. CPU_ZERO(&mask); CPU_SET(0, &mask); if(sched_setaffinity(0, sizeof(cpu_set_t), &mask) == -1) { exit(EXIT_FAILURE); }
参考资料:《Linux中CPU亲和性(affinity)》
3.1.2 设置优先级和调度策略
#include <sched.h>
struct sched_param {
int sched_priority; /* Scheduling priority */
};
int sched_setscheduler(pid_t pid, int policy, const struct sched_param *param);
policy常用的包括SCHED_OTHER、SCHED_FIFO、SCHED_RR。
实际在进程中看到的SCHED_FIFO优先级,是99减去sched_priority。比如这里设置为50,看到的是49。
示例如下:
//Set scheduler and priority. param.sched_priority = 50; sched_setscheduler(0, SCHED_FIFO, ¶m);
3.2 分析测试手段
在执行包含sched_setscheduler()函数的时候,必须具有root权限才能修改调度器类或者优先级。
可以通过perf timechart可视化查看fork及其子进程的执行情况。
sudo perf timechart record -T ./fork
sudo perf timechart -p fork
trace-cmd+kernelshark查看个进程间的执行情况。
sudo trace-cmd record -e sched_wakeup -e sched_switch ./fork
kernelshark
两个方法对比下来,trace-cmd结果更清晰点。
3.3 SCHED_NORMAL/SCHED_FIFO/SCHED_RR对比分析如下,以及RR_TIMESLICE修改
3.3.1 初始情况:普通进程,默认调度策略SCHED_NORMAL
可以看出,由于具有相同优先级且调度策略为SCHED_NORMAL,几个线程在不停的调入调出。
并且择机在CPU0或者CPU1上运行。
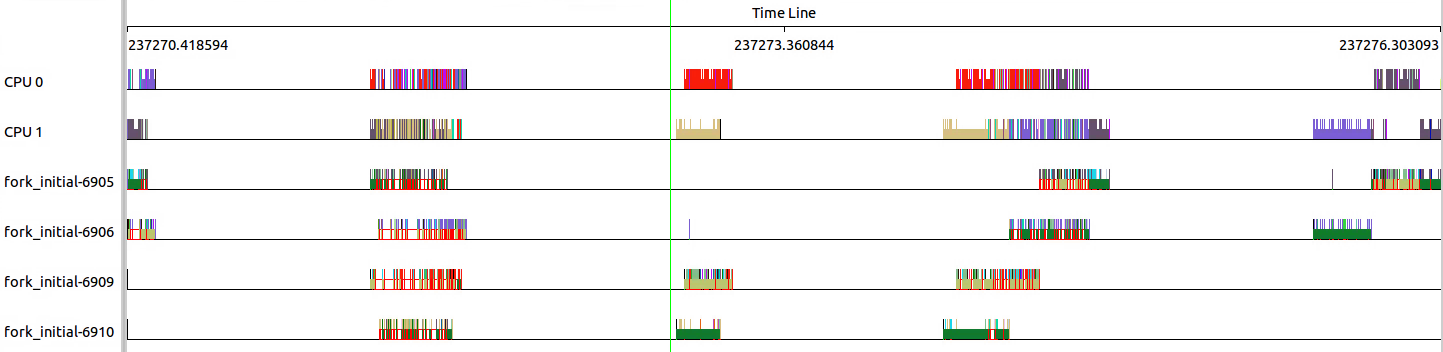
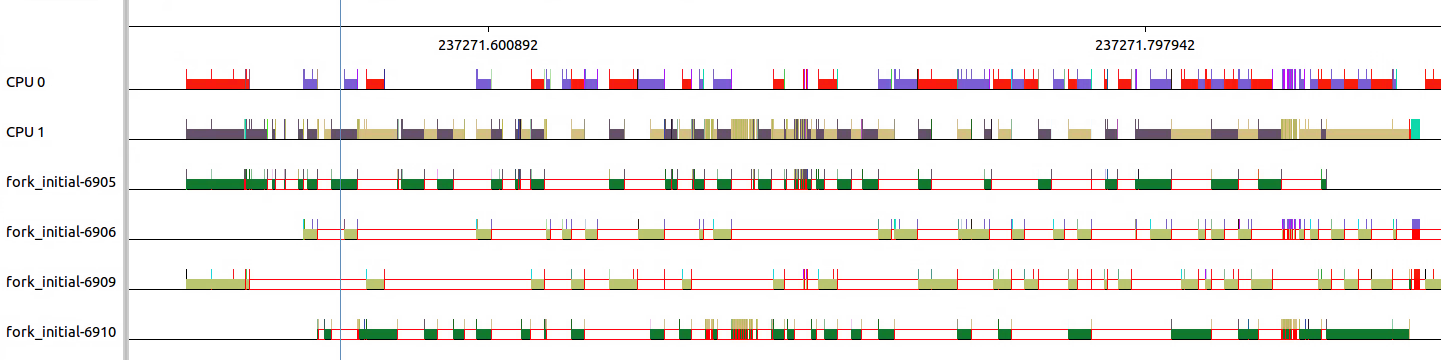
看一下细节,可以看出四个线程之间的频繁切换。
3.3.2 设置FIFO调度策略:设置为SCHED_FIFO,并且优先级为49
设置了SCHED_FIFO之后,可以清晰看出FIFO调度策略的特性。
由于优先级为49,已经非常低,没有其他进程会抢占fork,并且fork都是49,所以知道其它进程执行完毕才有机会调度到。
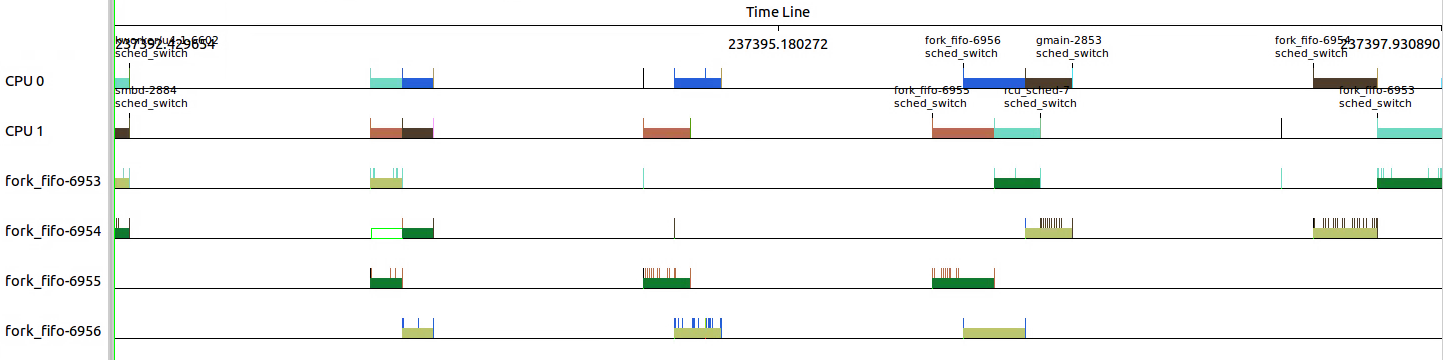
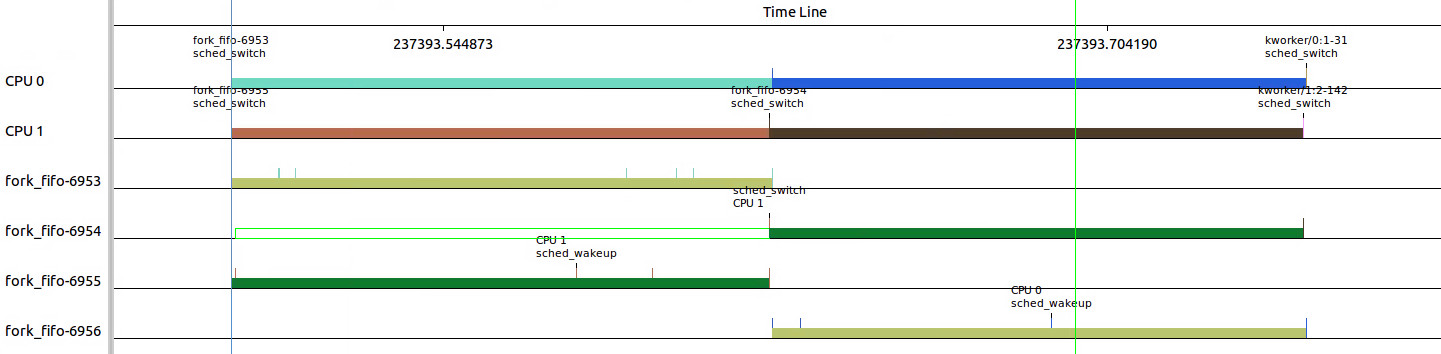
下面不同线程颜色看出6953和6956 在CPU0上执行,6954和6955在CPU1上执行。
6954在6955执行稍后就sched_wakeup了,但是知道6955换出后才得到执行的机会。6955在执行的过程中是不会被抢占的。
3.3.3 设置FIFO并CPU亲和性:在2的基础上,固定进程在CPU0上
在3.3.2基础上设置了,CPU亲和性,可以看出所有的线程都集中在CPU0上。
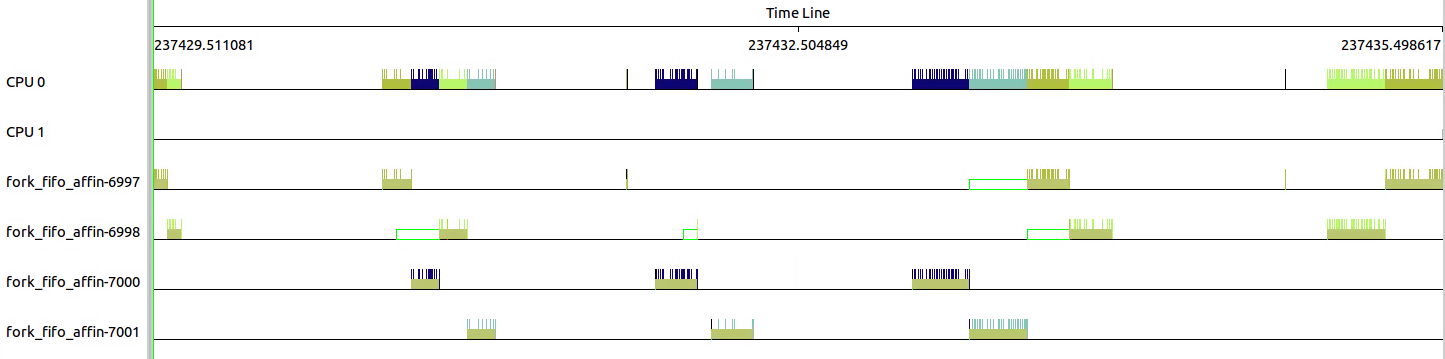
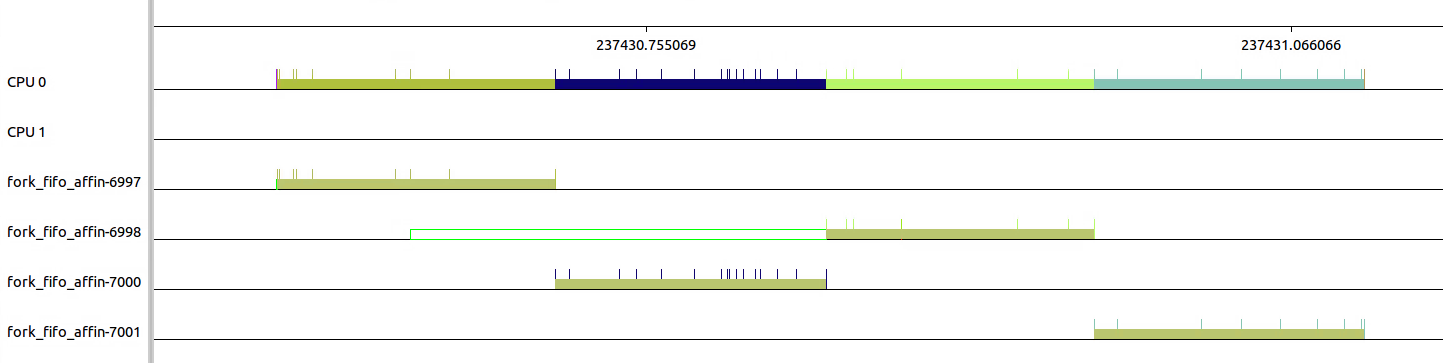
可以看出四个线程串行在一个CPU上,等待时间更长了。
3.3.4 设置RR调度策略:设置为SCHED_RR,并且优先级为49
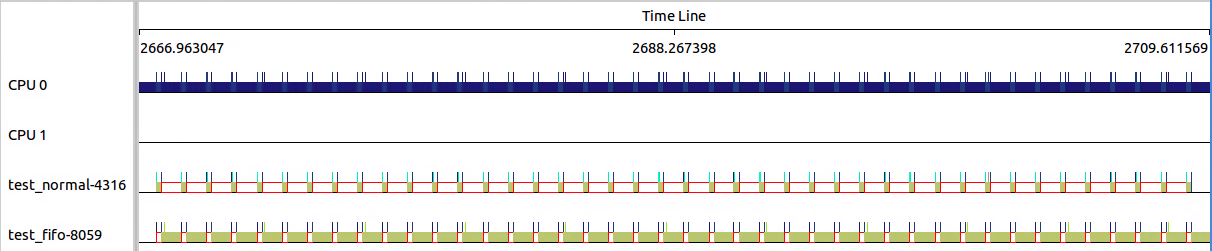
和3.3.2对比可以看出,SCHED_RR进程在执行过程中存在换入换出的情况。
那么RR的timeslice怎么样的呢?
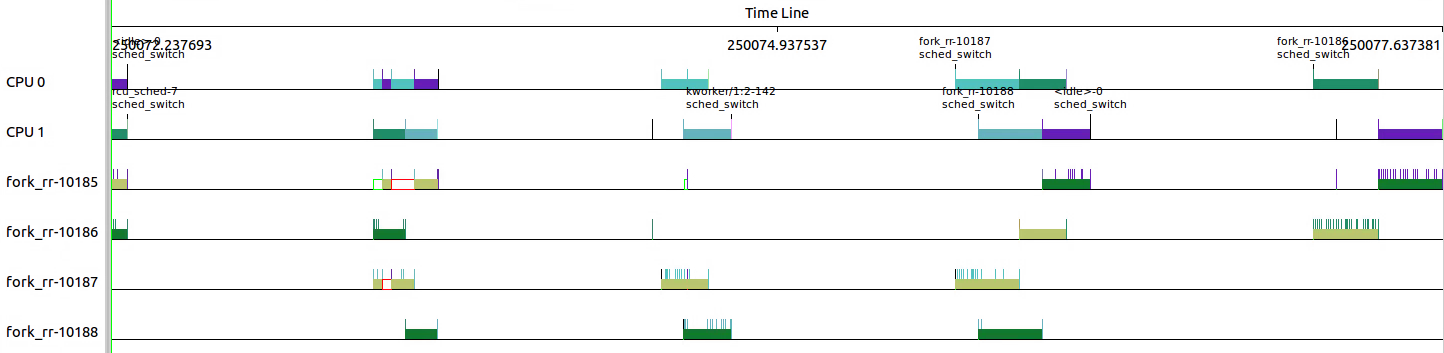

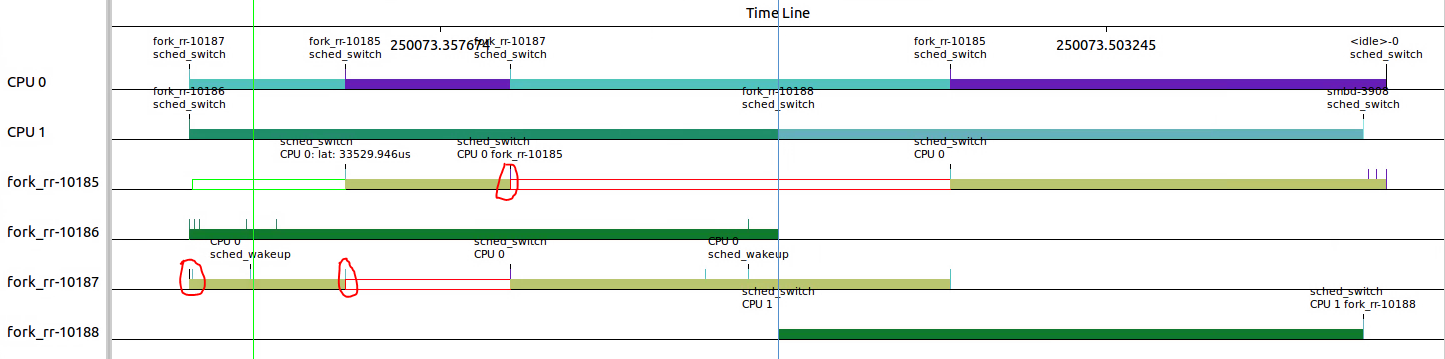
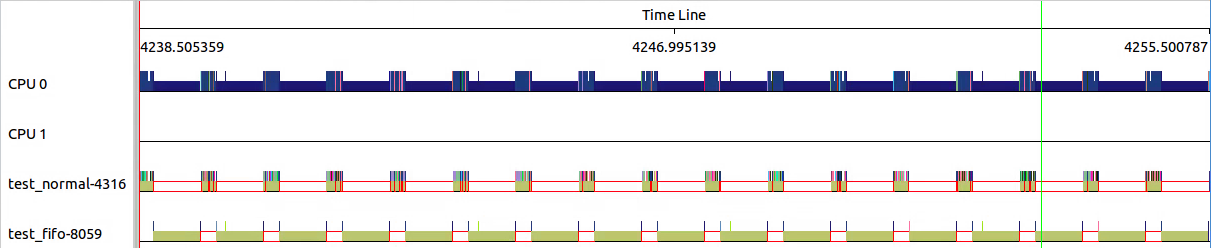
下图中三个点分别对应上图三个sched_switch,可以看出10187的第一段为36ms左右,10185的第一段也为36ms左右。
但是从/proc/sys/kernel/sched_rr_timeslice_ms读出的置位25,也即25*4ms=100ms。
这两者不符,why?应该是开头36ms之后部分,还没有超过100ms的timeslice,所以不存在进程切换。
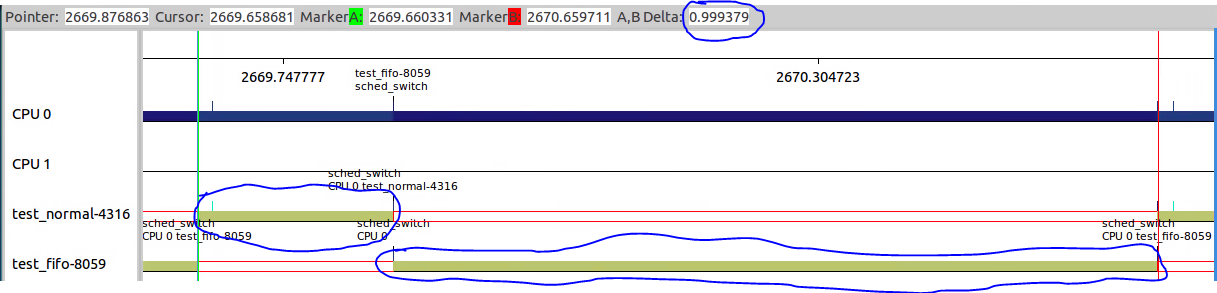
3.3.5 设置RR并CPU亲和性:在4的基础上,固定进程在CPU0上
和3.3.4对比,可以看出四个线程固定在CPU0上。它们之间的调度相对于3.3.4应该更加频繁。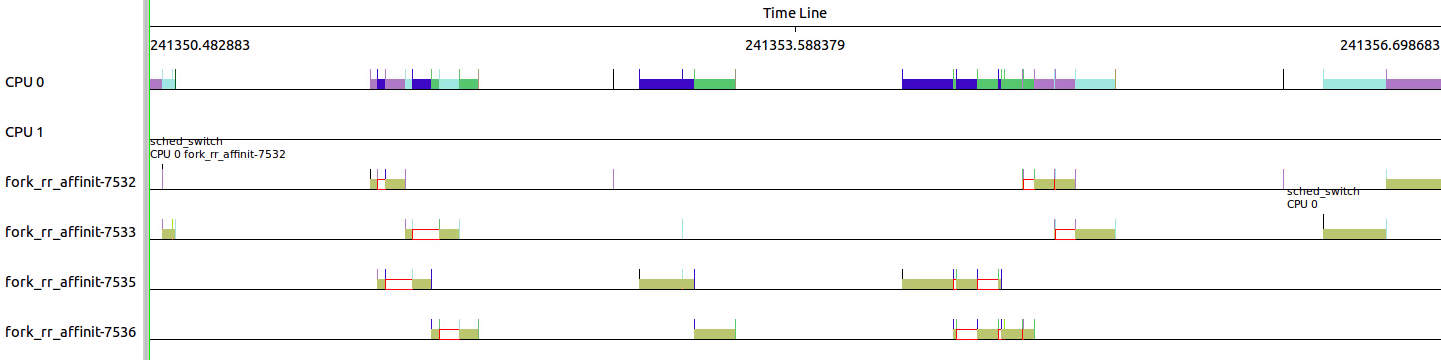
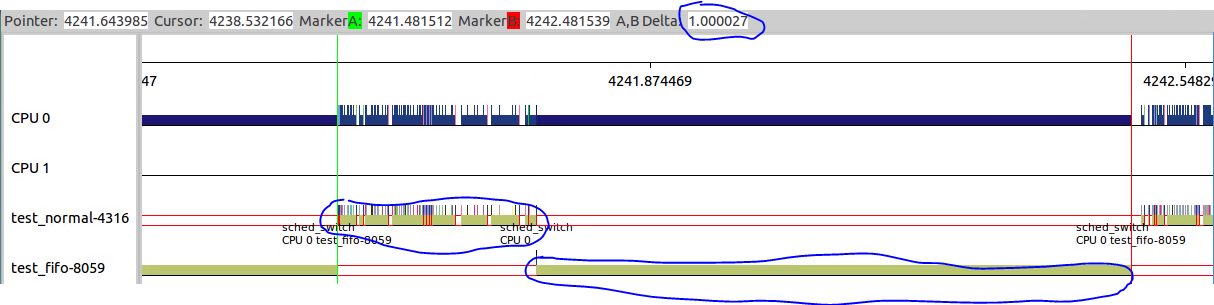
来看一下细节,7532在执行了34ms后调出给7535执行;7535执行了36ms之后跳出给7532执行。
7532执行完之后,7533开始执行;7532执行了34ms之后调出给7535执行。
7535执行完之后,7536开始执行;7536执行了34ms之后调出给7533执行。
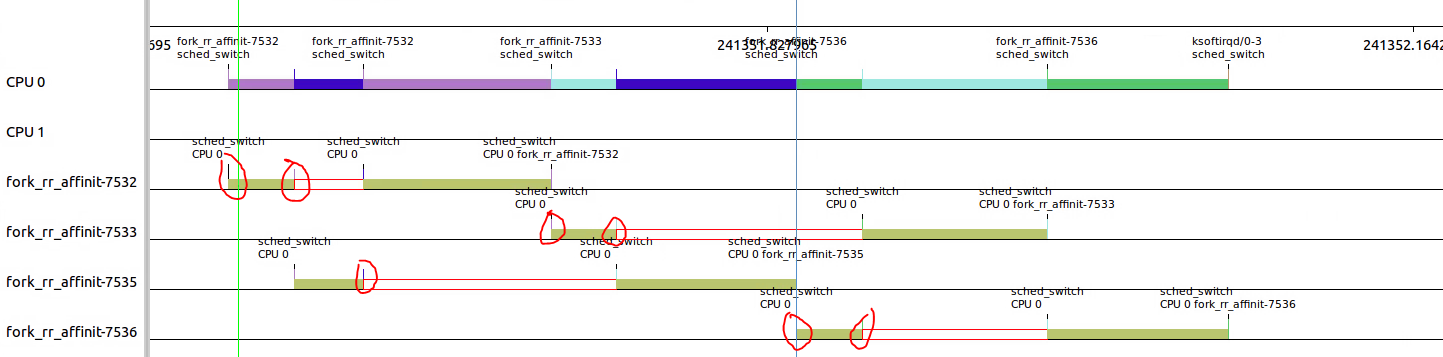
当前RR_TIMESLICE为100ms,后面执行的事件可能都不到100ms,所以加大循环次数,让执行事件超过200ms。
发现规律如下:每个线程第一次执行的事件都在36ms左右,后面就按照RR_TIMESLICE进行切换。上图看不出切换的原因是,36ms后剩下的不到100ms。所以不会存在切换的需求。
查看下图就会发现,除了每个线程开头运行36ms和结尾不定(进程主动放弃原因)之外,所有的段都在100ms左右。这就解释了RR_TIMESLICE所起的作用。
调整代码如下:
void test_medium(void) { int i,j; for(i = 0; i < 120000000; i++) j=i; } void test_high(void) { int i,j; for(i = 0; i < 240000000; i++) j=i; } void test_hi(void) { int i,j; for(i = 0; i < 360000000; i++) j=i; }
3.3.6 调整RR_TIMESLICE
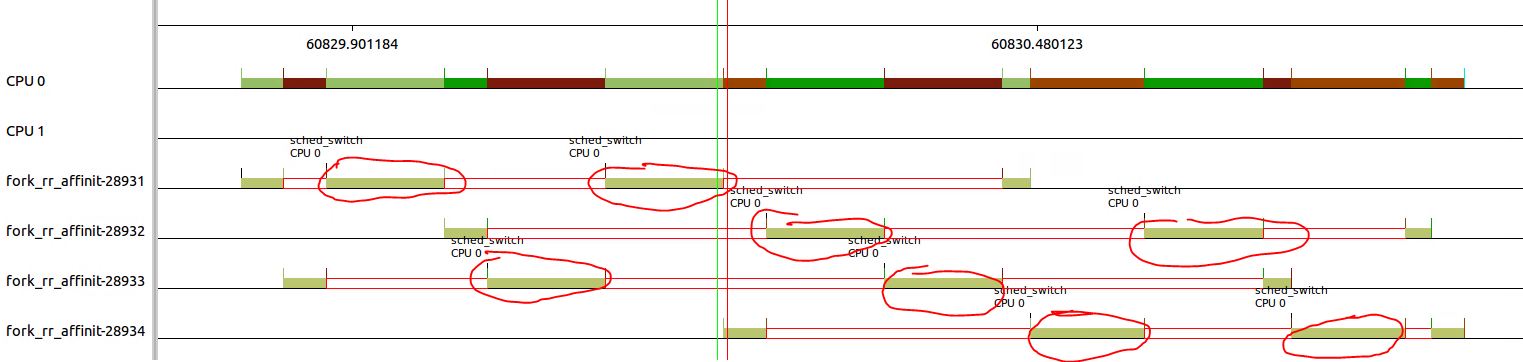
对RR_TIMESLICE的调整可以通过/proc/sys/kernel/sched_rr_timeslice_ms进行,这个sysfs节点的单位是jiffies。
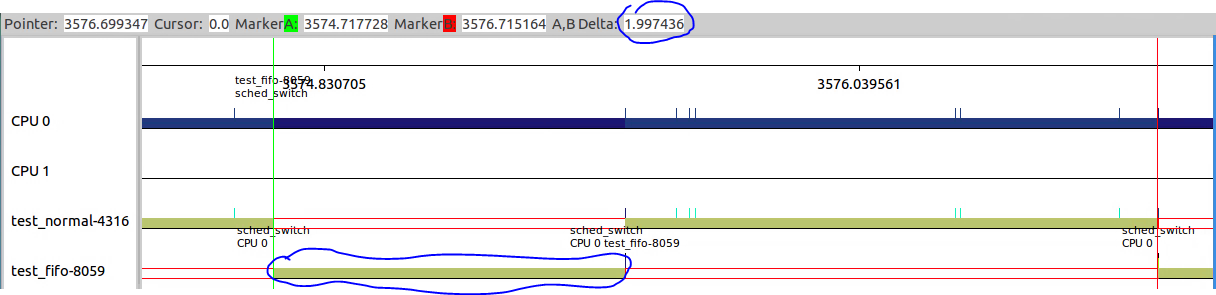
echo 100 > /proc/sys/kernel/sched_rr_timeslice_ms,读出来的结果是25,说明jiffies为4ms。
然后修改RR_TIMESLICE为50ms,读出的结果变成13,所以实际的timeslice应该是13*4=52ms。
从下图可以看出,每个timeslice确实变成了52ms,并且进程切换的次数增加了,每个进程中间包含了4个52ms的timeslice。
3.3.7 当RR和FIFO混合调度
首先以都采用SCHED_FIFO或者SCHED_RR作为参照,然后分别修改父进程为RR和修改子进程为RR,进行对比看看FIFO和RR混合时调度情况。
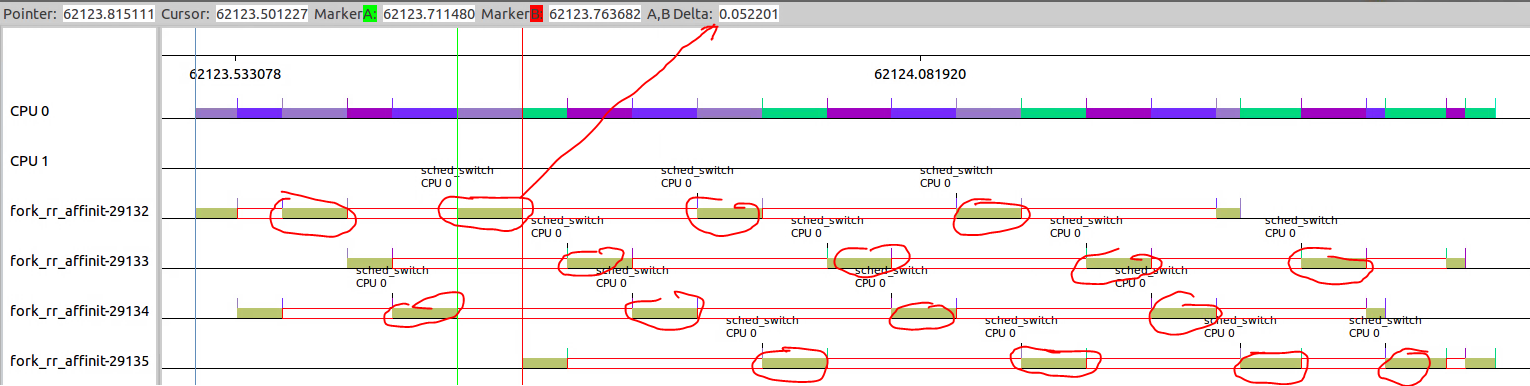
1.全部采用FIFO情况,从下图可以看出8653和8654分成四部分,8659和8668分成三部分。
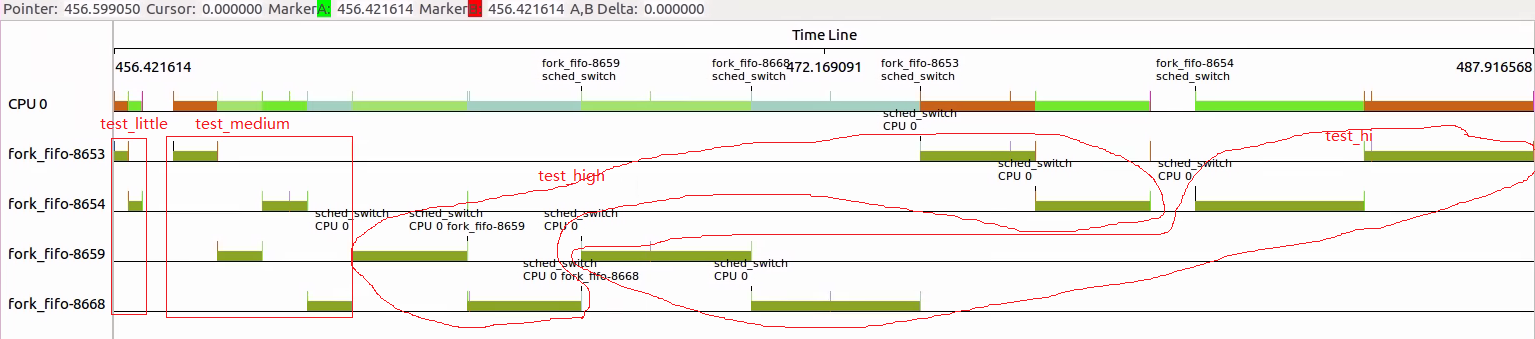
2.全部采用RR情况,test_medium部分4个线程互相抢占,后面test_high和test_hi部分由于wait()需要等待,只有个两两抢占。
3.那么如果将三个子进程都改成RR,结果如何呢?
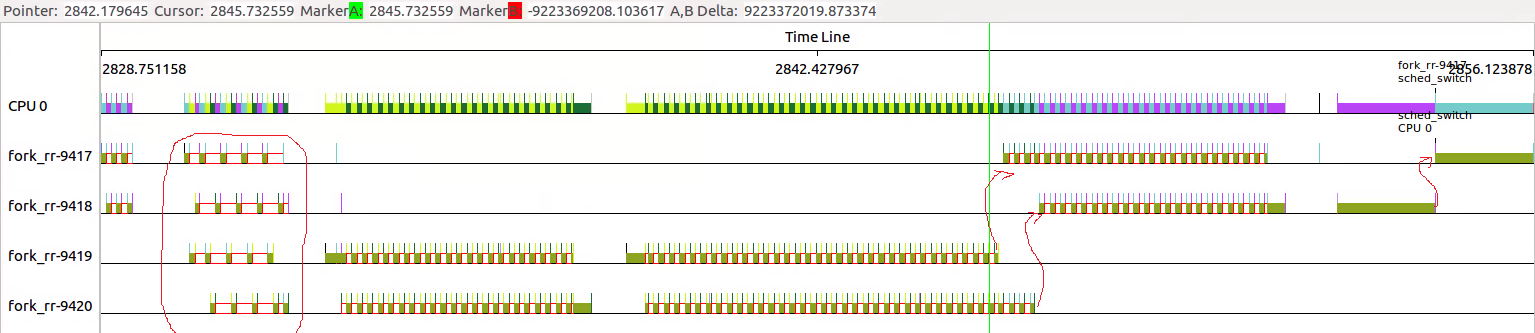
test_little部分,由于8983和8984不能交叉调度。
因为进程8983是FIFO,在(1)等到子进程8985结束之后,得到执行的机会。此时虽然8986也由调度机会,但是因为8983是FIFO,只能等8983执行结束,主动放弃。
所以直到(2)8986才有机会调度,执行完毕。
8984在8986结束过后(3),wait条件满足后继续执行,直到8984结束过后(4)继续8983执行。
和全部RR的区别主要在于(1)~(3)部分。
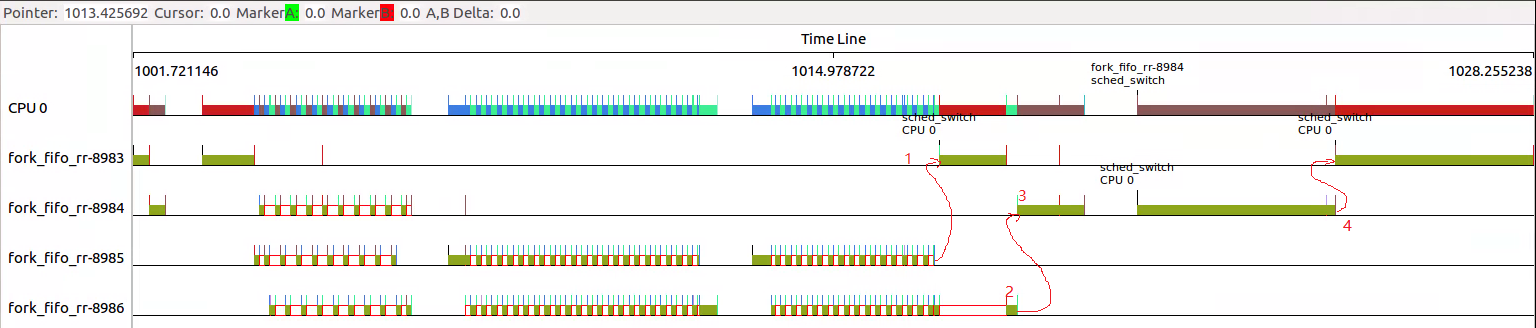
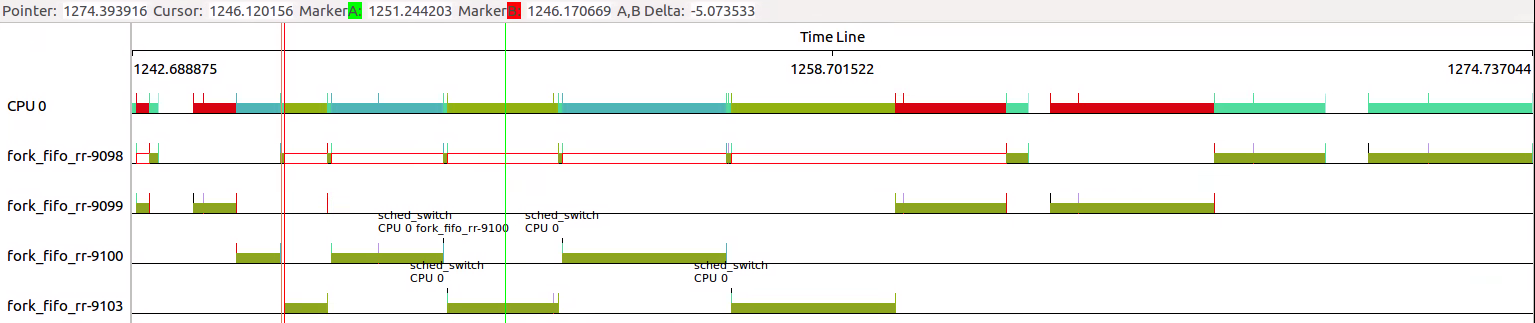
4. 那么只将父进程改成RR呢?
可以看出wait()的逻辑关系仍然被严格遵循着,只不过由于9098是RR,其他线程是FIFO。
所以9098被抢占的严重,9098的test_medium执行时间拉的很长,被其他FIFO线程阻塞较多。
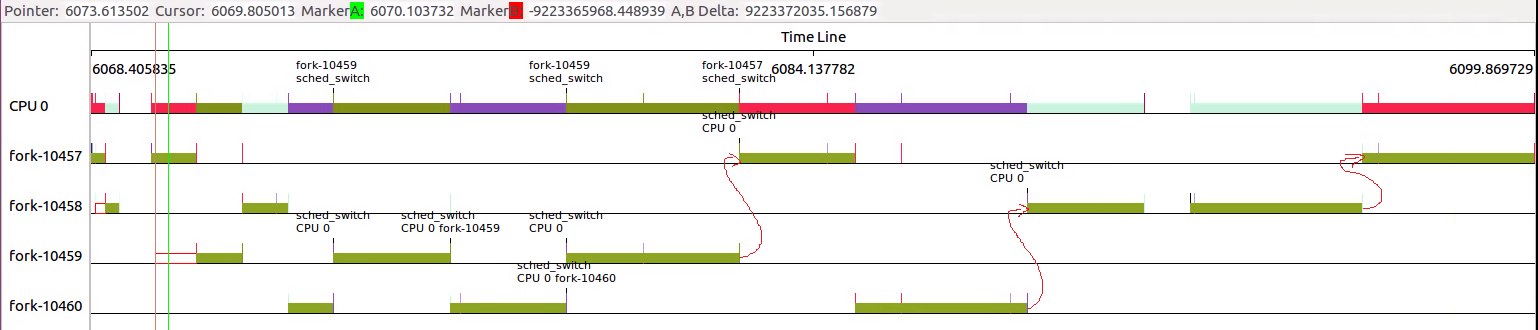
那么提高父进程RR的优先级会是什么情况呢?
可以看出,虽然10457是RR调度策略,但是由于优先级较高,10458必须等待10457执行完毕,才有机会得到调度。
所以10457的test_medium部分先得到机会执行。后面的10459虽然也处于可被调度情况,但苦于优先级较低,无法得到执行,只能等待10457主动放弃执行。
后面部分仍然严格遵循wait逻辑。
4. 对实时进程的优化
4.1 调整调度策略和优先级
通过chrt(Change Real Time)来改变进程的属性。
如,chrt -r -p 20 xxx设置进程调度策略为RR,优先级为20。
chrt -m可以查看支持的调度策略,以及优先级取值范围。
4.2 sysctl动态调整调度器各种参数
sysctl variable获取属性的值。
sysctl variable=value设置属性的值。
4.3 实时调度策略相关调节参数
这些参数都位于/proc/sys/kernel中。
sched_rr_timeslice_ms:针对SCHED_RR类型实时进程的时隙,用完时隙之后实时进程可能被强占并放入队列尾部。
sched_rt_period_us:实时进程调度的单位CPU时间,默认1000000us。
sched_rt_runtime_us:在sched_rt_pediod_us基础上,实时进程的占比,默认950000us。
4.3.1 sched_rt_period_us和sched_rt_runtime_us
关于sched_rr_timeslice_ms的测试,上面已经进行了相关说明。
下面看看修改sched_rt_period_us和sched_rt_runtime_us参数对实时进程和普通进程调度的影响。
测试环境:Ubuntu+Kernel 4.4.0-116 @ Dual CPUs
测试代码:
创建两个可执行文件,执行死循环。test_fifo采用FIFO调度策略,优先级为49;test_normal采用NORMAL调度策略,优先级wie120。
同时为了方便查看两者的占比情况,将两个进程都绑定到CPU0上。
#define _GNU_SOURCE #include <stdio.h> #include <sched.h> #include <stdlib.h> #include <unistd.h> int main(void) { int i, pid, result; cpu_set_t mask; struct sched_param param; //Set CPU affinity. CPU_ZERO(&mask); CPU_SET(0, &mask); if(sched_setaffinity(0, sizeof(cpu_set_t), &mask) == -1) { exit(EXIT_FAILURE); } //Set scheduler and priority. param.sched_priority = 50; sched_setscheduler(0, SCHED_FIFO, ¶m);------------------------test_normal只要注释这部分代码 while(1) { } return 0; }
4.3.1.1 2CPU sched_rt_runtime_us=950000
可以看出test_fifo占用了100%的CPU,看不到test_normal的身影。
为什么呢?
因为这是在一个双核的系统上,并且test_fifo和test_normal都固定在CPU0上。
sched_rt_runtime_us=950000就导致了test_fifo可以独占CPU0,test_normal得不到执行的机会。
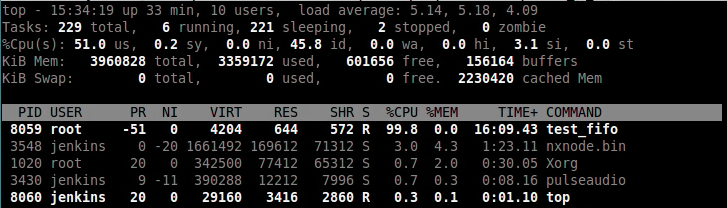
test_fifo独占了CPU0。

4.3.1.2 2CPU sched_rt_runtime_us=400000
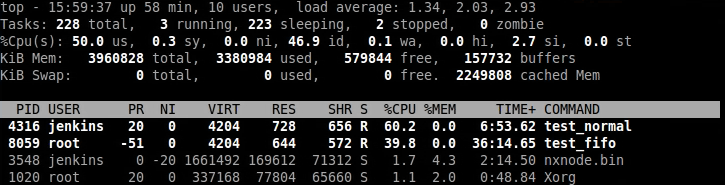
那么简单修改sched_rt_runtime_us到50%一下看看效果。
可以看到两者的比例变成了test_fifo:test_normal=4:1,这符合在双核系统上的预期,80%/2=40%。
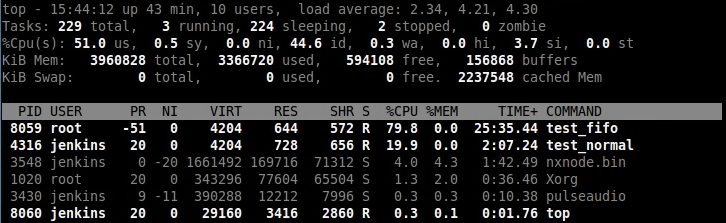
来看看细节,可以看出test_normal得到了调度。
看看细节如何,test_normal+test_fifo的总时间为1s,test_fifo执行事件为800ms。这在双核系统上也说得过去。
可以看出在SMP系统上sched_rt_runtime_us是如何分配的。
4.3.1.3 2 CPU sched_rt_runtime_us=400000 sched_rt_pediod_us=2000000
那么增大sched_rt_pediod_us到2000000us情况如何呢?
可以看出40%/2=20%=400000/2000000,符合预期。
可以看出test_fifo和test_normal的比例改变了。

test_fifo+test_normal的总时间变成2000000us,并且test_fifo执行事件为800ms,不变。
4.3.1.4 1CPU sched_rt_pediod_us=1000000 sched_rt_runtime_us=750000
将CPU1 offline,echo 0 > /sys/bus/cpu/devices/cpu1/online。
可以看到test_fifoCPU占比变成了75%,剩下的test_normal和其它进程使用。
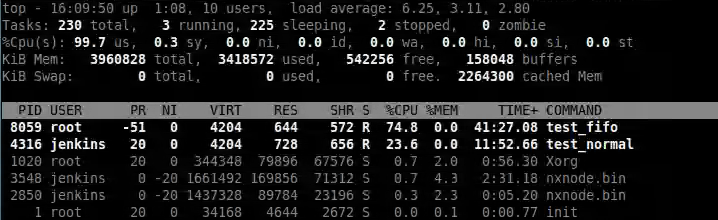
可以看出test_fifo在单核状态下,和设置的参数是一一对应的。
test_fifo CPU占比75%,执行时间为750ms,剩余的250ms由test_normal和其它进行分配。
虽然test_normal的nice为-20,但是对于CFS调取器来说,其它进程仍然有机会得到调度。
4.3.1.5 1CPU sched_rt_pediod_us=10000 sched_rt_runtime_us=9000
这样的目的是CFS得到很平滑的调度,并且保证普通进程占比10%。
实际情况是,test_fifo基本接近90%占比。
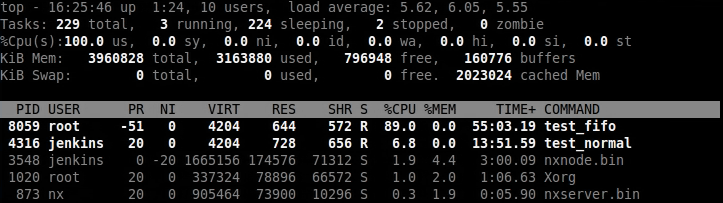
可以看到test_normal和test_fifo之间的调度更加频繁了。
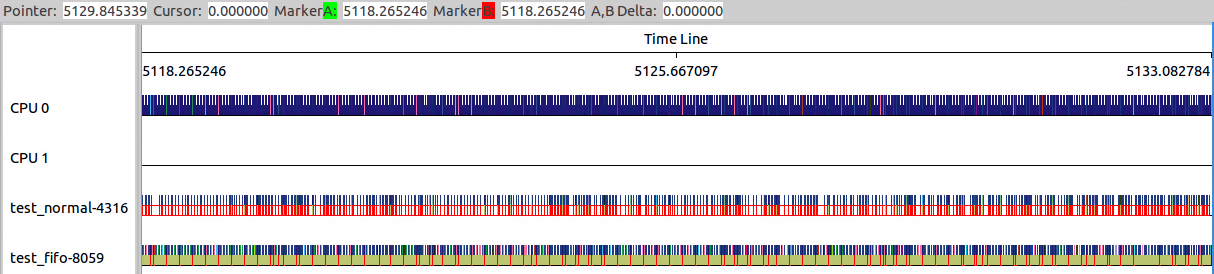
可以看出test_normal+test_fifo并不等于10ms,而是20ms。
但是两者的比例是一致的,test_fifo:test_normal=9:1
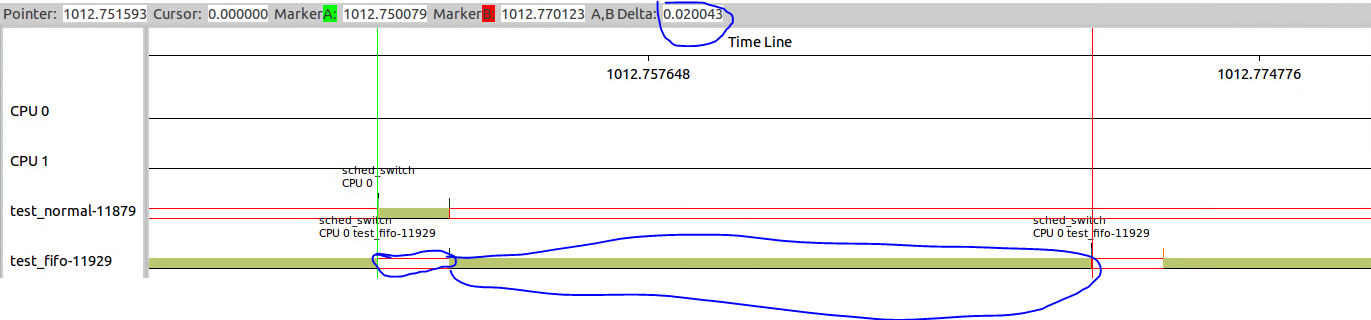
那么将sched_rt_runtime_us=36000、sched_rt_pediod_us=40000,呢?
结果如下,可以看出test_fifo+test_normal=40ms,两者比例也符合预期。
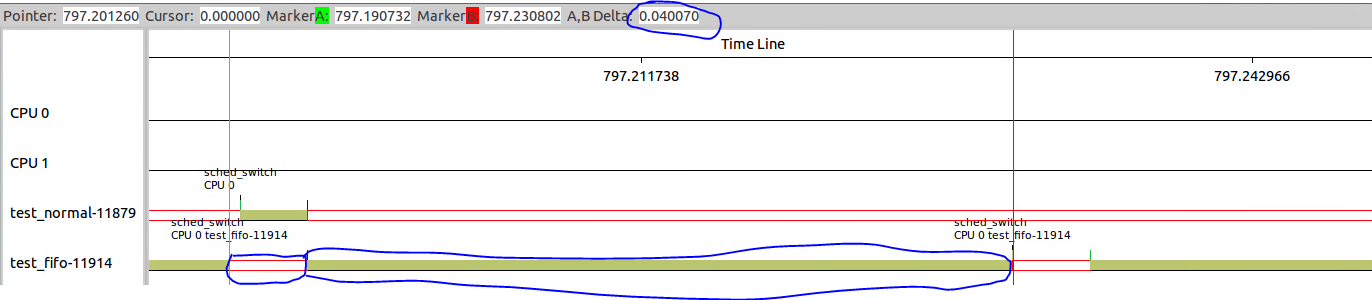
难道sched_rt_pediod_us有最小值20ms的限制?
4.3.2 一个实时任务很重的场景调节sched_rt_runtime_us
Linux默认sched_rt_runtime_us为950000,在此场景下场景上下行速率离目标差很远。
将其设置为-1,差不多达到目标。
所以在实际调度中,打开RT Bandwidth的开销还是很大的。
要保证CFS保留5%的CPU,花费的开销要大很多。
4.4 调试和统计接口
/proc/sched_debug:全局调试信息,包括cfs/rt/dl等就绪队列信息,以及运行中进程相关信息。
/proc/schedstat:全局调度的统计信息。
version 15
timestamp 4549804362
cpu0 4340 0 492167328 210807124 220972523 109642580 93539887439988 27717517566019 281300914
domain0 3 55479654 55454558 22085 8414771 3745 67 217 55454341 1092592 1029317 50266 11959758 15413 301 280 1029037 13709443 9063193 3910056 865357935 837652 599 2432437 6630756 41 0 41 0 0 0 0 0 0 111329937 41920159 0
cpu1 4546 0 527388167 223958553 306630172 161858229 91272746397129 25577018812315 303373597
domain0 3 77608259 77584351 20709 8378910 4007 137 221 77584130 716522 672167 31250 295259964 15454 273 97 672070 14581612 9475898 4287779 3002623546 925448 622 2366766 7109132 116 1 115 0 0 0 0 0 0 144771943 42740754 0
/proc/pid/sched:单个进程的统计信息,
test_fifo (17739, #threads: 1) ------------------------------------------------------------------- se.exec_start : 1019445477.050445 se.vruntime : -2.507707 se.sum_exec_runtime : 810819.452208 se.statistics.sum_sleep_runtime : 0.000000 se.statistics.wait_start : 0.000000 se.statistics.sleep_start : 0.000000 se.statistics.block_start : 0.000000 se.statistics.sleep_max : 0.000000 se.statistics.block_max : 0.000000 se.statistics.exec_max : 4.008440 se.statistics.slice_max : 0.000000 se.statistics.wait_max : 0.041248 se.statistics.wait_sum : 0.050407 se.statistics.wait_count : 4 se.statistics.iowait_sum : 0.000000 se.statistics.iowait_count : 0 se.nr_migrations : 1 se.statistics.nr_migrations_cold : 0 se.statistics.nr_failed_migrations_affine : 0 se.statistics.nr_failed_migrations_running : 0 se.statistics.nr_failed_migrations_hot : 0 se.statistics.nr_forced_migrations : 0 se.statistics.nr_wakeups : 0 se.statistics.nr_wakeups_sync : 0 se.statistics.nr_wakeups_migrate : 0 se.statistics.nr_wakeups_local : 0 se.statistics.nr_wakeups_remote : 0 se.statistics.nr_wakeups_affine : 0 se.statistics.nr_wakeups_affine_attempts : 0 se.statistics.nr_wakeups_passive : 0 se.statistics.nr_wakeups_idle : 0 avg_atom : 3955.216840 avg_per_cpu : 810819.452208 nr_switches : 205 nr_voluntary_switches : 0 nr_involuntary_switches : 205 se.load.weight : 1024 se.avg.load_sum : 48293853 se.avg.util_sum : 48244723 se.avg.load_avg : 1002 se.avg.util_avg : 1002 se.avg.last_update_time : 1018634657576560 policy : 2 prio : 49 clock-delta : 22 mm->numa_scan_seq : 0 numa_pages_migrated : 0 numa_preferred_nid : -1 total_numa_faults : 0 current_node=0, numa_group_id=0 numa_faults node=0 task_private=0 task_shared=0 group_private=0 group_shared=0
5. 总结
从上面可以看出实时进程的调度很简单,对于FIFO严格按照优先级来执行,同一优先级先进先得到执行。
对于RR调度策略,存在一个RR_TIMESLICE时隙设置,可以通过调节时隙让各进程得到相对公平的机会。
当相同优先级的FIFO和RR进程执行时,RR相对吃亏,因为FIFO一旦抢占会执行到主动放弃。