一、 hadoop环境配置
需要用到的工具
jdk(我的是1.8)
hadoop-eclipse-plugin-2.6.5.jar(这里我提供已编译好的包 下载地址,若是其他版本可自行搜索或用ant和hadoop源代码自行编译)
eclipse(我的版本是eclipse-standard-luna-R-linux-gtk-x86_64.tar.gz)
hadoop-2.7.0.tar.gz
二、 eclipse
1. 下载解压eclipse,解压
sudo tar -zxvf eclipse-standard-luna-R-linux-gtk-x86_64.tar.gz点击eclipse中的eclipse.ini文件打开eclipse
2. eclipse打开报错
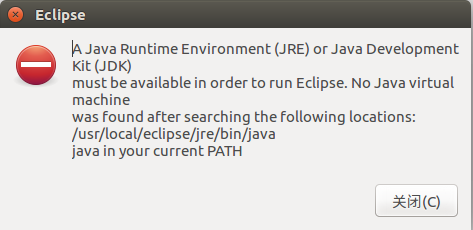
解决,进入eclipse的jre目录,将javabin目录链接到eclipse中
cd ./eclipse/jre
sudo ln -s /usr/local/java-8-openjdk-amd64/bin/ bin![]()
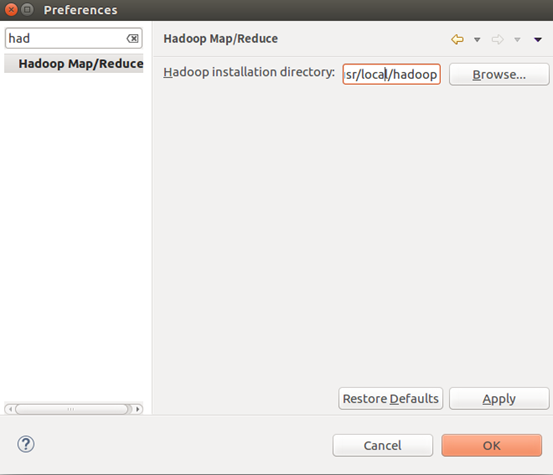
3. 打开eclipse > window > perference搜索mapreduce,添加hadoop目录
4. 显示hadoop连接配置界面Windows > show view > other
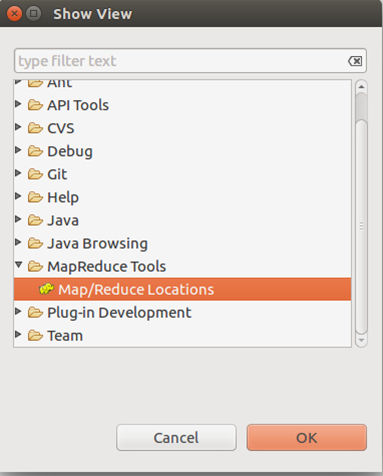
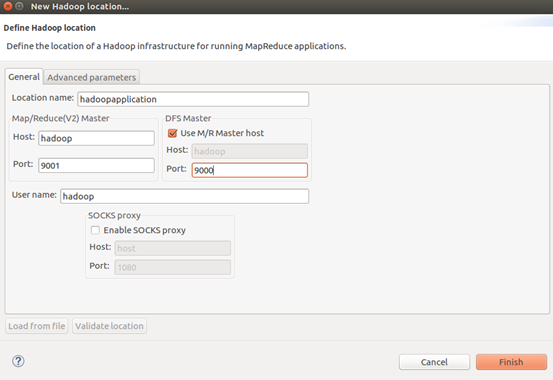
5. 在Map.Reduce Locations中 右键 > new application
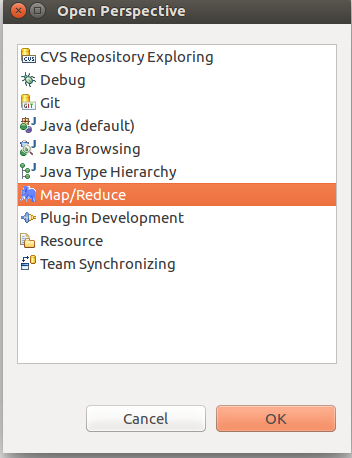
6. 打开mapreduce的hdfs,在左侧就有hdfs目录了
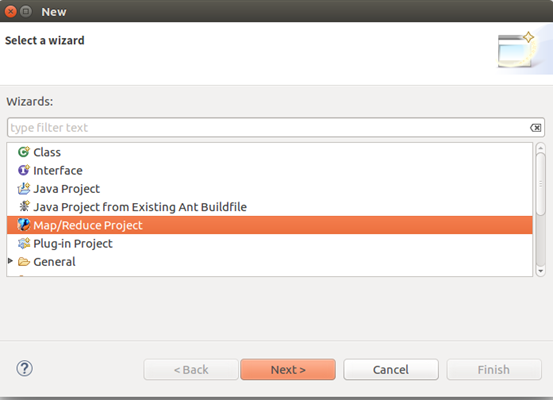
8. 新建mapreduce project
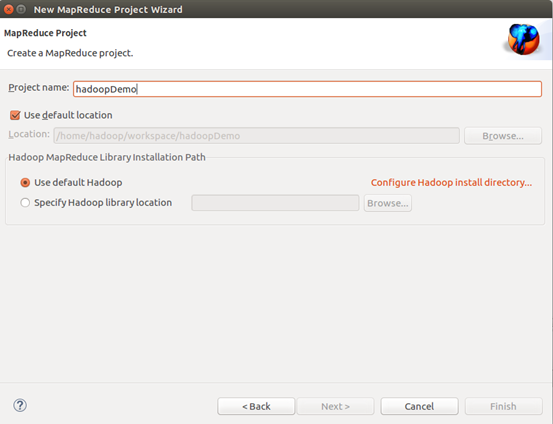
9. 新建包和类输入测试代码
package com.hadoop.test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Wordcount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(Wordcount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
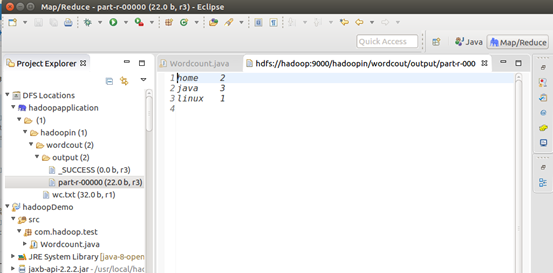
10. 创建单词文件,并上传到hdfs上
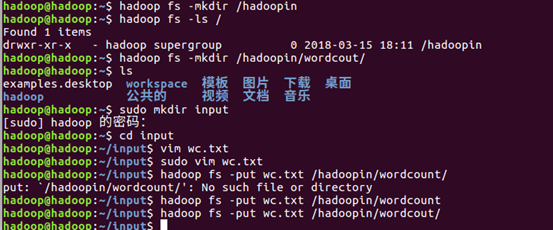
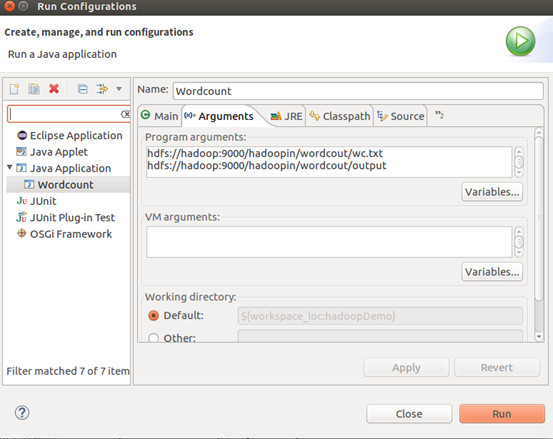
11. 右键》run As 》run on configuration,输出