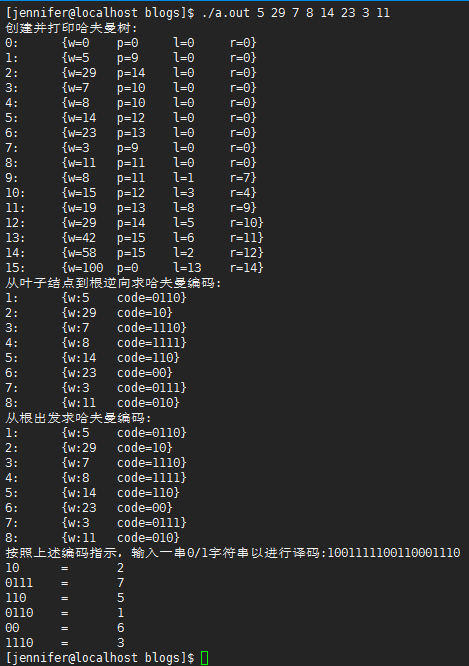
文字描述
结点的路径长度
从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径,路径上的分支数目称作路径长度。
树的路径长度
从树根到每一个结点的路径长度之和叫树的路径长度。
结点的带权路径长度
从该结点到树根之间的路径长度与结点上权的乘积
树的带权路径长度
所有叶子结点的带权路径长度之和
最优二叉树或哈夫曼树
假设有n个权值{w1,w2, … ,wn},试构造一颗有n个叶子结点的二叉树,每个叶子结点带权wi,则其中带权路径长度WPL最小的二叉树称作最优二叉树或哈夫曼树。
哈夫曼算法
目的:构造一颗哈夫曼树
实现:
(1) 根据给定的n个权值{w1,w2, … ,wn}构成n棵二叉树的集合F={T1,T2,…,Tn},其中每棵二叉树Ti中只有一个带权为wi的根结点,其左右子树均为空。
(2) 在F中选取两颗根结点的权值最小的树作为左右子树构造一颗新的二叉树,且置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
(3) 在F中删除这两颗树,同时将新得到的二叉树加入F中
(4) 重复(2)和(3),直到F只含一颗树为止。这颗树便是哈夫曼树。
哈夫曼编码
假设A、B、C、D的编码分别为00,01,10和11,则字符串’ABACCDA‘的电文便是’00010010101100’,对方接受时,可按二位一分进行译码。但有时希望电文总长尽可能的短, 如果让电文中出现次数较多的字符采用尽可能短的编码,则传送电文的总长鞭可减少。但是设计长短不等的编码,则必须是任一字符的编码都不是另一个字符的编码的前缀,以避免同样子电文串有多种译法,这种编码叫前缀编码。
又如何得到使电文总长最短的二进制前缀编码呢?假设字符串中有n种字符,每种字符在电文中出现的次数作为权,设计一颗哈夫曼树。左子树为0,右子树为1,走一条从根到叶子结点的路径进行编码。
哈夫曼译码
译码的过程是分解电文字符串,从根出发,按字符‘0‘或’1‘确定找左孩子或右孩子,直至叶子结点,便求得该子串相应的字符。
示意图
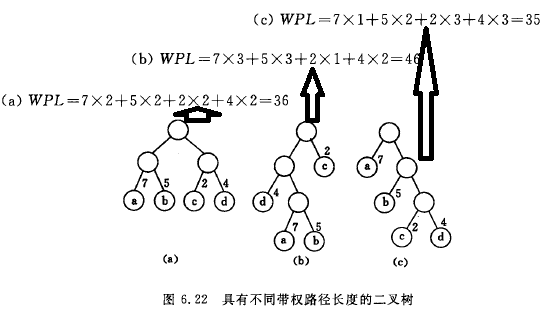

算法分析
略
代码实现


1 /* 2 ./a.out 5 29 7 8 14 23 3 11 3 4 1001111100110001110 5 */ 6 #include <stdio.h> 7 #include <stdlib.h> 8 #include <string.h> 9 10 #define DEBUG 11 //结点的最大个数 12 #define MAX_SIZE 50 13 14 //哈夫曼树和哈夫曼结点的存储结构 15 typedef struct{ 16 unsigned int weight; 17 unsigned int parent, lchild, rchild; 18 }HNode, *HuffmanTree; 19 20 //哈夫曼编码表的存储结构 21 typedef char **HuffmanCode; 22 23 /* 24 * 在HT[1, ..., l]中选择parent为0且weight最小的两个结点,其序号分别为min1,min2 25 */ 26 int Select(HuffmanTree HT, int l, int *min1, int *min2){ 27 int i = 0; 28 *min1 = *min2 = -1; 29 30 //找parent为0且weight最小的min1 31 for(i=1; i<=l; i++){ 32 if(!HT[i].parent){ 33 if(*min1<0){ 34 *min1 = i; 35 }else if(HT[*min1].weight > HT[i].weight){ 36 *min1 = i; 37 }else{ 38 //other 39 } 40 }else{ 41 //other 42 } 43 } 44 45 //找parent为0且weight最小的min2 46 for(i = 1; i<=l; i++){ 47 if(!HT[i].parent && i!=*min1){ 48 if(*min2<0){ 49 *min2 = i; 50 }else if(HT[*min2].weight > HT[i].weight){ 51 *min2 = i; 52 }else{ 53 //other 54 } 55 }else{ 56 //other 57 } 58 } 59 60 //确保min1<min2 61 if(*min1 > *min2){ 62 i = *min1; 63 *min1 = *min2; 64 *min2 = i; 65 } 66 67 if((*min1<0) && (*min2<0)){ 68 return -1; 69 }else{ 70 return 0; 71 } 72 } 73 74 /* 75 * 创建一颗哈夫曼树 76 * 77 * w存放n个字符的权值(权值都为非负数),构造哈夫曼树HT, L表示哈夫曼树的长度(正常情况下为2*n-1) 78 */ 79 void HuffmanCreate(int w[], int n, HuffmanTree *HT, int *L){ 80 if(n<=1){ 81 return; 82 } 83 int m = 2*n-1, i = 0, s1 = 0, s2 = 0; 84 //0号单元不用 85 (*HT) = (HuffmanTree)malloc((m+1)*sizeof(HNode)); 86 HuffmanTree p = *HT; 87 *L = m; 88 89 //给哈夫曼树的叶子结点赋值 90 for(p=(*HT+1), i = 0; i<n; i++){ 91 p[i].weight = w[i]; 92 p[i].parent = p[i].lchild = p[i].rchild = 0; 93 } 94 95 //给哈夫曼树的非叶子结点赋值 96 for(i=n+1; i<=m; ++i){ 97 //在HT[1,...,i-1]中选择parent为0且weight最小的两个结点,其序号分别为s1和s2 98 if( Select(*HT, i-1, &s1, &s2) < 0){ 99 break; 100 } 101 //用s1和s2作为左右子树构造一颗新的二叉树 102 (*HT)[s1].parent = (*HT)[s2].parent = i; 103 (*HT)[i].lchild = s1; 104 (*HT)[i].rchild = s2; 105 //置新的二叉树的根结点的权值为其左右子树上根结点的权值之和 106 (*HT)[i].weight = (*HT)[s1].weight + (*HT)[s2].weight; 107 } 108 return; 109 } 110 111 /* 112 * 哈夫曼编码 113 * 114 * 从叶子到根逆向求每个字符的哈夫曼编码 115 */ 116 void HuffmanEncoding_1(HuffmanTree HT, HuffmanCode *HC, int n){ 117 //分配n个字符编码的头指针向量 118 *HC = (HuffmanCode)malloc((n+1)*sizeof(char *)); 119 //分配求编码的工作空间 120 char *cd = (char*)malloc(n+sizeof(char)); 121 //编码结束符 122 cd[n-1] = '�'; 123 int i = 0, start = 0, c = 0, f = 0; 124 //逐个字符求哈夫曼编码 125 for(i=1; i<=n; i++){ 126 //编码结束位置 127 start = n-1; 128 //从叶子到根逆向求编码 129 for(c=i, f=HT[i].parent; f!=0; c = f, f=HT[f].parent){ 130 if(HT[f].lchild == c){ 131 cd[--start] = '0'; 132 }else{ 133 cd[--start] = '1'; 134 } 135 } 136 //为第i个字符编码分配空间 137 (*HC)[i-1] = (char*)malloc((n-start)*sizeof(char)); 138 //从cd复制编码到HC 139 strncpy((*HC)[i-1], cd+start, n-start); 140 } 141 //释放工作空间 142 free(cd); 143 return ; 144 } 145 146 /* 147 * 哈夫曼编码 148 * 149 * 从根出发,遍历整个哈夫曼树,求得各个叶子结点所表示的字符的哈夫曼编码 150 */ 151 void HuffmanEncoding_2(HuffmanTree HT, HuffmanCode *HC, int n){ 152 *HC = (HuffmanCode)malloc((n+1)*sizeof(char *)); 153 int p = 2*n-1; 154 int cdlen = 0; 155 int i = 0; 156 char *cd = (char*)malloc(n+sizeof(char)); 157 //利用weight,当作遍历哈夫曼树时的结点状态标志 158 for(i=1; i<=(2*n-1); i++){ 159 HT[i].weight = 0; 160 } 161 while(p){ 162 if(HT[p].weight == 0){ 163 //向左 164 HT[p].weight = 1; 165 if(HT[p].lchild != 0){ 166 p = HT[p].lchild; 167 cd[cdlen++] = '0'; 168 }else if(HT[p].rchild == 0){ 169 //登记叶子结点的字符的编码 170 (*HC)[p-1] = (char *)malloc((cdlen+1)*sizeof(char)); 171 memset((*HC)[p-1], 0, (cdlen+1)*sizeof(char)); 172 cd[cdlen] = '�'; 173 //复制编码 174 strncpy((*HC)[p-1], cd, cdlen); 175 } 176 }else if(HT[p].weight == 1){ 177 //向右 178 HT[p].weight = 2; 179 if(HT[p].rchild != 0){ 180 p = HT[p].rchild; 181 cd[cdlen++] = '1'; 182 } 183 }else{ 184 //退到父结点,编码长度减1 185 HT[p].weight = 0; 186 p = HT[p].parent; 187 --cdlen; 188 } 189 } 190 } 191 192 /* 193 *哈夫曼译码 194 * 195 *从根出发走向叶子结点,找到叶子结点后输出该结点的下标值,然后返回根结点重复,直至读完。 196 */ 197 void HuffmanDecoding(HuffmanTree HT, int n, char str[], size_t len) 198 { 199 //1001111100110001110 200 int p = 2*n-1; 201 int i = 0; 202 while(i < len){ 203 printf("%c",str[i]); 204 if(str[i] == '0'){ 205 //走向左孩子 206 p = HT[p].lchild; 207 }else if(str[i] == '1'){ 208 //走向右孩子 209 p = HT[p].rchild; 210 }else{ 211 printf("unexcepted char %c!!! ", str[i]); 212 return; 213 } 214 //看是否走到叶子结点 215 if(p<=n){ 216 //输出结点的下标值,并返回根结点 217 printf(" = %d ", p); 218 p = 2*n-1; 219 } 220 i+=1; 221 } 222 return ; 223 } 224 225 void HuffmanPrint(HuffmanTree HT, int L){ 226 if(L<=0) 227 return ; 228 int i = 0; 229 for(i=0; i<=L; i++){ 230 printf("%d: {w=%d p=%d l=%d r=%d} ", i, HT[i].weight, HT[i].parent, HT[i].lchild, HT[i].rchild); 231 } 232 } 233 234 int main(int argc, char *argv[]) 235 { 236 if(argc < 2){ 237 return -1; 238 } 239 240 int i = 0, L = 0; 241 int w[MAX_SIZE] = {0}; 242 HuffmanTree HT = NULL; 243 244 for(i=1; i<argc; i++){ 245 w[i-1] = atoi(argv[i]); 246 } 247 #ifdef DEBUG 248 printf("创建并打印哈夫曼树: "); 249 #endif 250 HuffmanCreate(w, i-1, &HT, &L); 251 HuffmanPrint(HT, L); 252 253 #ifdef DEBUG 254 printf("从叶子结点到根逆向求哈夫曼编码: "); 255 #endif 256 HuffmanCode HC; 257 HuffmanEncoding_1(HT, &HC, i-1); 258 259 #ifdef DEBUG 260 int j = 0; 261 for(j=0; j<i-1; j++){ 262 printf("%d: {w:%d code=%s} ", j+1, w[j], HC[j]); 263 free(HC[j]); 264 } 265 free(HC); 266 #endif 267 268 #ifdef DEBUG 269 printf("从根出发求哈夫曼编码: "); 270 #endif 271 HuffmanEncoding_2(HT, &HC, i-1); 272 273 #ifdef DEBUG 274 for(j=0; j<i-1; j++){ 275 printf("%d: {w:%d code=%s} ", j+1, w[j], HC[j]); 276 free(HC[j]); 277 } 278 free(HC); 279 #endif 280 281 printf("按照上述编码指示,输入一串0/1字符串以进行译码:"); 282 char str[100] = {0}; 283 scanf("%s", &str); 284 HuffmanDecoding(HT, i-1, str, strlen(str)); 285 return 0; 286 }
运行