

dic={'name':1,'id':'0','age':2,'phone':3,'job':4}
def get_line(filename):
#文件读取
with open(filename,encoding='utf-8')as f:
for line in f:
line=line.strip()
line_str=line.split(',')
yield line_str
def condition_filter(condition):
#调剂筛选
condition=condition.strip()
if '>' in condition:
col,val=condition.split('>')
g=get_line('userinfo')
for line_list in g:
if int(line_list[dic[col]])>int(val):
yield line_list
def view(view_lst,staff_g):
#展示符合条件的员工
for staff_info in staff_g:
info=[]
for i in view_lst:
print(staff_info[dic[i]],end='')
print('')
ret='select name,age where age>22'
view,condition=ret.split('where')
print(view,condition)
view=view.replace('select','').strip()
view_lst=view.split(',')
print(view_lst,condition)
1.和数据结构相关的序列:
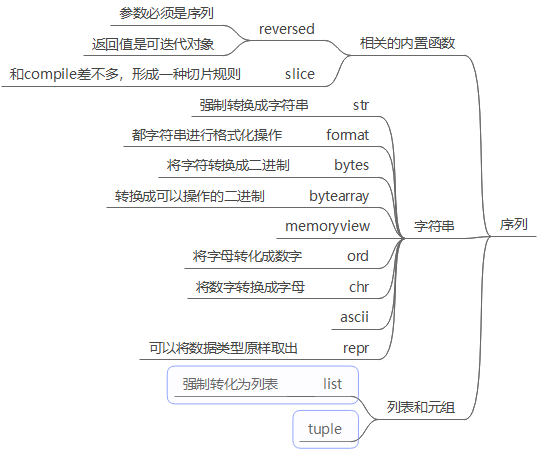
1.1reversed对列表进行反转(次操作不会该改变原列表,而且生成一个新的迭代器)
l=[1,4,6,8,9] l1=l.reverse() #列表里的反转没有返回值 print(l1,l) #列表里的反转会改变原来的数据 结果为 None [9, 8, 6, 4, 1]
l=[1,4,6,8,9] l1=reversed(l) #反转有返回值返回一个迭代器 如果返回为一个内存地址则为迭代器 print(l1,l) #列表里的反转会不会改变原来的数据 print(list(l1)) 结果为 <list_reverseiterator object at 0x000001DEBE75B080> [1, 4, 6, 8, 9] [9, 8, 6, 4, 1]
1.2slice对可迭代对象进行切片得到是切片的范围
l=[1,4,6,8,9] li=slice(1,3) print(l[li]) print(l[1:3]) 结果为 [4, 6] [4, 6]
1.3format前面学习了3种format格式化的方式,现在补充一种:
print(format('test', '>20'))#开辟20个内存空间字符串再最右边 print(format('test', '<20'))#开辟20个内存空间字符串再最左边 print(format('test', '^20'))#开辟20个内存空间字符串再最中间边 结果为 test test test
· 1.4bytes 将内容的类型转换成bytes类型
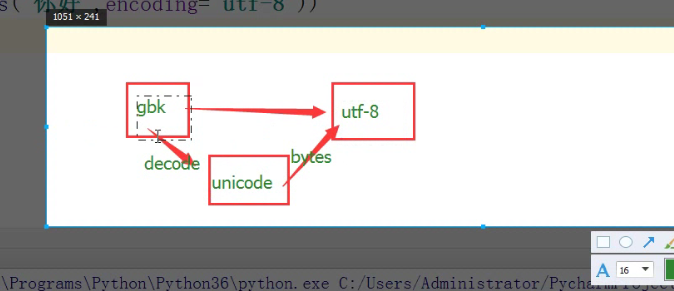
列:我拿到的是gbk编码的,我想转成utf-8编码:
print(bytes('你好',encoding='utf-8')) #因为内存种默认编码方式是unicode次操作是将unicode转为utf-8的bytes print(bytes('你好',encoding='gbk')) #因为内存种默认编码方式是unicode次操作是将unicode转为gbk的bytes 结果为 b'xe4xbdxa0xe5xa5xbd' b'xc4xe3xbaxc3'
1,我拿到的是gbk类型的数据,像转换成utf-8类型的进行的操作为
1.5bytearray(得到的二进制放入类表中,并且可以操作:)注:网络编程中只能传二进制,照片和视频也是只能以二进制来进行存储,html网页爬取是也是要编码方式的:
b_array=bytearray('你好',encoding='utf-8') print(b_array) print(b_array.decode('utf-8')) #进行解码操作 print(b_array[1]) print(b_array[0:3].decode('utf-8')) #可以读取字符串中想要读取的字符 print(b_array[1]+1) 结果为 bytearray(b'xe4xbdxa0xe5xa5xbd') 你好 189 你 190
1.6怎么将s1='alexa'变成s2=alexb
s1='alexa' byte1=bytearray(s1,encoding='utf-8') print(byte1) byte1[-1]=byte1[-1]+1 print(byte1[-1]) s2=byte1 print(s2.decode('utf-8')) 结果为 bytearray(b'alexa') 98 alexb
1.7ord将字符串转换成数字:
print(ord('好')) print(ord('1')) 结果为 22909 49
1.8将字母转换成数字:输入的数字范围为65到122:
print(chr(65)) print(chr(122)) 结果为 A z
1.9repr数据类型原样输去:
name='egg' print('你好%r'%name) #name把字符串的字符串数据类型也会改变 print('你好%s'%name) print(repr('1')) #此数据类型为字符串输出也为字符串 print(repr(1)) 结果为 C:pycharmpython.exe D:/python练习程序/第十五天/内置函数.py 你好'egg' 你好egg '1' 1
。1.10 len计算某个变量的长度:
name='fjkdjfkj' print(len(name)) 结果为 8
1.11all (如果迭代对象中有一个为False,则返回False,否则返回True)
print(all(['','jfkdj'])) print(all(['f','jfkdj'])) 结果为 False True
1.12 any 如果可迭代对象中有一个为True,则返回为True
print(any(['','jfkdj'])) print(any(['',None])) 结果为 True False
1.13zip函数将几个可迭代的对象的所有相同的索引值放在同一个元组中:如果里面包含字典则只取字典的key值(而且遵循最少迭代对象里面元素的原则)
l=[1,2,4,5,6] l2=['1','2','4','a'] print(list(zip(l,l2))) 结果为 [(1, '1'), (2, '2'), (4, '4'), (5, 'a')]
l=[1,2,4,5,6] l2=['1','2','4','a'] dic={'nam3':'fjj','fjkf':'jfkj'} print(list(zip(l,l2,dic))) 结果为 [(1, '1', 'nam3'), (2, '2', 'fjkf')]
1.14filter其主要功能时进行筛选:不会改变原来函数的值,但是执行之后元素的个数会小于等于原来的:
def is_odd(x): return x%2 ret=filter(is_odd,[1,4,6,7,9,33]) #如果函数里结果为True,才会有返回值 print(ret) #得到的是一个迭代器 print(list(ret)) 结果为 <filter object at 0x000001B2C4A390B8> [1, 7, 9, 33]
1.15map 执行前后元素的个发生改变但是值有可能不会边:
l=[1,-4,6,-7,9,33] ret=map(abs,l)#对函数里每一个元素进行前面函数的操作,才会有返回值 print(ret)#得到的是一个迭代器 print(list(ret)) 结果为 <map object at 0x0000021B69A99278> [1, 4, 6, 7, 9, 33]
1.16sorted:对列表里的元素进行排序,而且生成一个列表不会生成一个迭代器,但是不会改变原来数据:
l=[1,-4,6,-7,9,33] l1=l.sort() #列表里的排序没有返回值 print(l,l1)#列表里的反转会改变原来的数据 结果为 [-7, -4, 1, 6, 9, 33] None
l=[1,-4,6,-7,9,33] l1=sorted(l) #列表里的排序没有返回值 print(l)#列表里的反转不会改变原来的数据 print(l1)#会生成一个新的列表 结果为 [1, -4, 6, -7, 9, 33] [-7, -4, 1, 6, 9, 33]
再排序的过程中可以指定key(指定排序的类型)和reversed进行从大小的排序
l=[1,-4,6,-7,9,33] l1=sorted(l,key=abs,reverse=True) #列表里的排序没有返回值 print(l)#列表里的反转不会改变原来的数据 print(l1)#会生成一个新的列表 结果为 [1, -4, 6, -7, 9, 33] [33, 9, -7, 6, -4, 1]
以字符串的长度来进行排序l=[' ',[1,4],'hello','fjkljdflj']
l=[' ',[1,4],'hello','fjkljdflj'] ret=sorted(l,key=len) print(ret) 结果为 [' ', [1, 4], 'hello', 'fjkljdflj']
3.匿名函数:lambd 公式:函数名=lambda 参数:返回值
def add(x,y): return x+y ret=add(1,3) print(ret) add1=lambda x,y:x+y ret=add1(1,3) print(ret) 结果为 4 4
4.计算字典中value值最大的key
dic={'k1':10,'k2':324,'k3':56}
def func(key):
return dic[key]
print(max(dic,key=func))
结果为
k2
print(max(dic,key=lambda key:dic[key])) 结果为 k2
求列表的里每个元素的平方:
ret=map(lambda x:x**2,[-1,3,-4,6]) print(list(ret)) 结果为 [1, 9, 16, 36]
求列表里大于10的元素:
l=[4,6,88,99,3] ret=filter(lambda x:x>10,l) print(list(ret)) 结果为 [88, 99]
12. min max filter map sorted —— lambda
13.计算下个函数的输出结果
d=lambda p:p*2 t=lambda p:p*3 x=2 x=d(x) x=t(x) x=d(x) print(x) 结果 24
14.现有两元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
s1=(('a'),('b')) s2=(('c'),('d')) s3=zip(s1,s2) #进行拉链操作把两个函数相对应的索引值放到一起 ret=map(lambda t:{t[0]:t[1]},s3) print(list(ret)) 结果为 [{'a': 'c'}, {'b': 'd'}]
15。
def multipliers(): return [lambda x:i*x for i in range(4)] print([m(2) for m in multipliers()]) 结果为 [6, 6, 6, 6]