问题导读
1.你认为cinder与swift区别是什么?
2.cinder是否存在单点故障?
3.cinder是如何发展而来的?![]()
在openstack中,我们经常遇到这么个问题,cinder与swift的区别是什么?
cinder与swift各自的用途是什么?
cinder是块存储,用来给虚拟机挂扩展硬盘,就是将cinder创建出来的卷,挂到虚拟机里。cinder是OpenStack到F版,将之前在Nova中的部分持久性块存储功能(Nova-Volume)分离了出来,独立为新的组件Cinder
swift是一个系统,可以上传和下载,里面一般存储的是不经常修改的内容,比如用于存储 VM 镜像、备份和归档以及较小的文件,例如照片和电子邮件消息。更倾向于系统的管理
块存储具有安全可靠、高并发大吞吐量、低时延、规格丰富、简单易用的特点,适用于文件系统、数据库或者其他需要原始块设备的系统软件或应用。
上面其实很多感觉不是太直观,个人认为cinder可以理解为个人电脑的移动硬盘,它可以随意格式化,随时存取。
对于swift可以作为网盘,相信对于云技术的同学来说,网盘应该是不陌生的,如果把一些经常用的内容,放到网盘中是非常不方便的。
Swift 还是 Cinder?何时使用以及使用哪一种?
那么,应该使用哪一种对象存储:Swift 还是 Cinder?答案取决于您的应用程序。如果需要运行商用或遗留应用程序,那么很少需要进行这种选择。这些应用程序不可能被编码来利用 Swift API,但您可以轻松挂载一个 Cinder 磁盘,它表现得就像是直接将存储附加到大多数应用程序。
当然,您还可以对新应用程序使用 Cinder,但是不会从 Swift 自动附带的弹性和冗余中获益。如果编程人员面对这样的挑战,那么 Swift 的分布式可扩展架构是一个值得考虑的特性。
单点故障
Swift 架构是分布式的,可防止所有单点故障和进行水平扩展。
cinder存在单点故障还未解决
更多内容,以下来自ibm资料库:![]()
块存储 (Cinder)
Cinder 是 OpenStack Block Storage 的项目名称;它为来宾虚拟机 (VM) 提供了持久块存储。对于可扩展的文件系统、最大性能、与企业存储服务的集成以及需要访问原生块级存储的应用程序而言,块存储通常是必需的。
系统可以暴露并连接设备,随后管理服务器的创建、附加到服务器和从服务器分离。应用程序编程接口 (API) 也有助于加强快照管理,这种管理可以备份大量块存储。
对象存储 (Swift)
Swift 是两种产品中较为成熟的一个:自 OpenStack 成立以来一直是一个核心项目。Swift 的功能类似于一个分布式、可访问 API 的存储平台,可直接将它集成到应用程序中,或者用于存储 VM 镜像、备份和归档以及较小的文件,例如照片和电子邮件消息。
Object Store 有两个主要的概念:对象和容器。
对象就是主要存储实体。对象中包括与 OpenStack Object Storage 系统中存储的文件相关的内容和所有可选元数据。数据保存为未压缩、未加密的格式,包含对象名称、对象的容器以及键值对形式的所有元数据。对象分布在整个数据中心的多个磁盘中,Swift 可以借此确保数据的复制和完整性。分布式操作可以利用低成本的商用硬件,同时增强可扩展性、冗余性和持久性。
容器类似于 Windows® 文件夹,容器是用于存储一组文件的一个存储室。容器无法被嵌套,但一个租户可以供创建无限数量的容器。对象必须存储在容器中,所以您必须至少拥有一个容器来使用对象存储。
与传统的文件服务器不同,Swift 是横跨多个系统进行分布的。它会自动存储每个对象的冗余副本,从而最大程度地提高可用性和可扩展性。对象版本控制提供了防止数据意外丢失或覆盖的额外保护。
Swift 架构
服务器
- 代理服务器
- 对象服务器
- 容器服务器
- 帐户服务器
帐户服务器通过使用对象存储服务来管理帐户。它的操作类似于在内部提供了清单的容器服务器,在这种情况下,将会枚举分配到给定帐户的容器。
流程
环
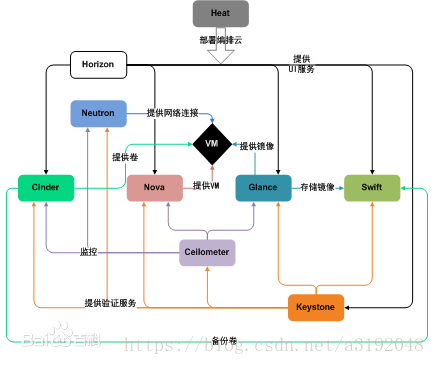
Cinder 架构
图 1. Cinder architecture
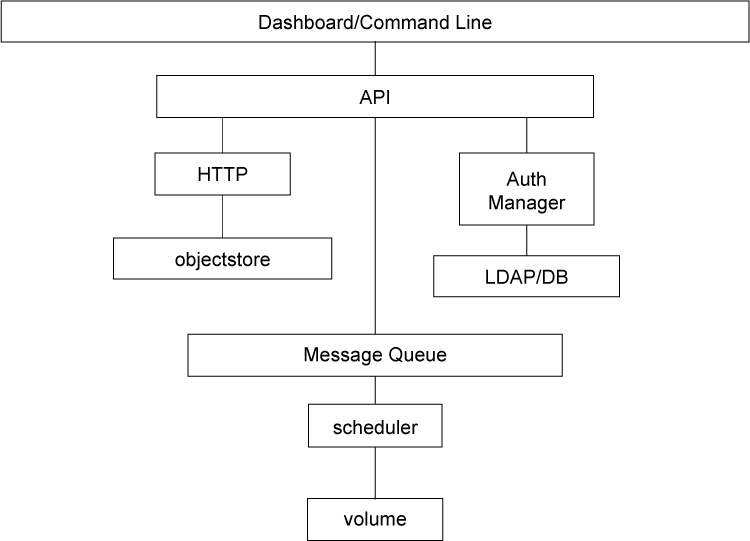
设置
系统要求
安装
Debian:在所有主机上安装基础 Swift 包:
- sudo apt-get install python-swift
- sudo apt-get install swift
- and the server-specific packages on the hosts that will be running them:
- sudo apt-get install swift-auth
- sudo apt-get install swift-proxy
- sudo apt-get install swift-account
- sudo apt-get install swift-container
- sudo apt-get install swift-object
- sudo apt-get install cinder-api
- sudo apt-get install cinder-scheduler
- sudo apt-get install cinder-volume
- sudo yum install openstack-swift
- sudo yum install openstack-swift-proxy
- sudo yum install openstack-swift-account
- sudo yum install openstack-swift-container
- sudo yum install openstack-swift-object
- sudo yum install openstack-swift-doc
- sudo yum install openstack-cinder
- sudo yum install openstack-cinder-doc
openSUSE:使用以下命令:
- sudo zypper install openstack-swift
- sudo zypper install openstack-swift-auth
- sudo zypper install openstack-swift-account
- sudo zypper install openstack-swift-container
- sudo zypper install openstack-swift-object
- sudo zypper install openstack-swift-proxy
- sudo zypper install openstack-cinder-api
- sudo zypper install openstack-cinder-scheduler
- sudo zypper install openstack-cinder-volume
配置
- account-server.conf
- container-server.conf
- object-server.conf
- proxy-server.conf
使用场景
以具有 Member 角色的用户身份登录到 OpenStack Dashboard。
在导航面板中的 Manage Computer 下,单击 Volumes > Create Volume。
图 2. 创建一个卷

卷应出现在项目的列表中。
图 3. 项目中的卷
编辑附件,以便将卷连接到其中一个计算实例。
图 4. 管理卷附件
OpenStack 创建一个惟一的 iSCSI 合格名称,并将其显示给目前具有活动 iSCSI 会话的计算节点。如果实例是逻辑存储(通常是一个 /dev/sdX 磁盘),那么可以使用 Cinder 卷。
作为具有 Member 角色的用户身份登录到 OpenStack Dashboard,在导航面板的 Object Store 下,单击 Containers > Create Container。图 5. 创建容器


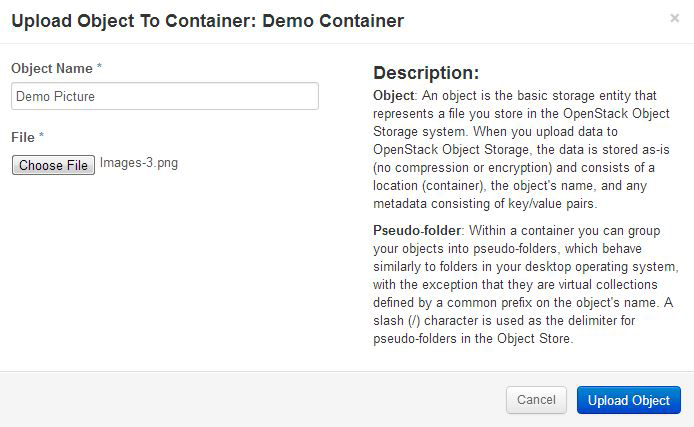
不过,您还可以从仪表板上传对象。在 Object Store 下,单击 Containers > Upload Object 并提供一个包含存储内容的文件。图 7. 上传对象
Swift——提供对象存储 (Object Storage),在概念上类似于Amazon S3服务,不过swift具有很强的扩展性、冗余和持久性,也兼容S3 API
Glance——提供虚机镜像(Image)存储和管理,包括了很多与Amazon AMI catalog相似的功能。(Glance的后台数据从最初的实践来看是存放在Swift的)。
Cinder——提供块存储(Block Storage),类似于Amazon的EBS块存储服务,目前仅给虚机挂载使用。
(Amazon一直是OpenStack设计之初的假象对手和挑战对象,所以基本上关键的功能模块都有对应项目。除了上面提到的三个组件,对于AWS中的重要的EC2服务,OpenStack中是Nova来对应,并且保持和EC2 API的兼容性,有不同的方法可以实现)
三个组件中,Glance主要是虚机镜像的管理,所以相对简单;Swift作为对象存储已经很成熟,连CloudStack也支持它。Cinder是比较新出现的块存储,设计理念不错,并且和商业存储有结合的机会,所以厂商比较积极。
Swift出现领域
关于Swift的架构和部署讨论,除了官方网站,网上也有很多文章,这里就不重复.(也可以参考我之前在OpenStack中国行活动中上海站演讲的PPT)。从开发上看,最近也没有太大的结构性调整,所以我想主要说说比较适用的应用领域好了。
从我所了解的实际案例来看,Swift出现的领域有4个,(应该还有更多,希望大家看到实际用例能够指教)
1.网盘。
Swift的对称分布式架构和多proxy多节点的设计导致它从基因里就适合于多用户大并发的应用模式,最典型的应用莫过于类似Dropbox的网盘应用,Dropbox去年底已经突破一亿用户数,对于这种规模的访问,良好的架构设计是能够支撑的根本原因。
Swift的对称架构使得数据节点从逻辑上看处于同级别,每台节点上同时都具有数据和相关的元数据。并且元数据的核心数据结构使用的是哈希环,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。另外数据是无状态的,每个数据在磁盘上都是完整的存储。这几点综合起来保证了存储的本身的良好的扩展性。
另外和应用的结合上,Swift是说HTTP协议这种语言的,这使得应用和存储的交互变得简单,不需要考虑底层基础构架的细节,应用软件不需要进行任何的修改就可以让系统整体扩展到非常大的程度。
2.IaaS公有云
Swift在设计中的线性扩展,高并发和多租户支持等特性,使得它也非常适合做为IaaS的选择,公有云规模较大,更多的遇到大量虚机并发启动这种情况,所以对于虚机镜像的后台存储具体来说,实际上的挑战在于大数据(超过G)的并发读性能,Swift在OpenStack中一开始就是作为镜像库的后台存储,经过RACKSpace上千台机器的部署规模下的数年实践,Swift已经被证明是一个成熟的选择。
另外如果基于IaaS要提供上层的SaaS 服务,多租户是一个不可避免的问题,Swift的架构设计本身就是支持多租户的,这样对接起来更方便。
3.备份归档
RackSpace的主营业务就是数据的备份归档,所以Swift在这个领域也是久经考验,同时他们还延展出一种新业务--“热归档”。由于长尾效应,数据可能被调用的时间窗越来越长,热归档能够保证应用归档数据能够在分钟级别重新获取,和传统磁带机归档方案中的数小时而言,是一个很大的进步。
4. 移动互联网和CDN
移动互联网和手机游戏等产生大量的用户数据,数据量不是很大但是用户数很多,这也是Swift能够处理的领域。
至于加上CDN,如果使用Swift,云存储就可以直接响应移动设备,不需要专门的服务器去响应这个HTTP的请求,也不需要在数据传输中再经过移动设备上的文件系统,直接是用HTTP 协议上传云端。如果把经常被平台访问的数据缓存起来,利用一定的优化机制,数据可以从不同的地点分发到你的用户那里,这样就能提高访问的速度,我最近看到Swift的开发社区有人在讨论视频网站应用和Swift的结合,窃以为是值得关注的方向。
Glance
Glance比较简单,是一个虚机镜像的存储。向前端nova(或者是安装了Glance-client的其他虚拟管理平台)提供镜像服务,包括存储,查询和检索。这个模块本身不存储大量的数据,需要挂载后台存储(Swift,S3。。。)来存放实际的镜像数据。
Glance主要包括下面几个部分:
1.API service: glance-api 主要是用来接受Nova的各种api调用请求,将请求放入RBMQ交由后台处理,。
2.Glacne-registry 用来和MySQL数据库进行交互,存储或者获取镜像的元数据,注意,刚才在Swift中提到,Swift在自己的Storage Server中是不保存元数据的,这儿的元数据是指保存在MySQL数据库中的关于镜像的一些信息,这个元数据是属于Glance的。
3.Image store: 后台存储接口,通过它获取镜像,后台挂载的默认存储是Swift,但同时也支持Amazon S3等其他的镜像。
Glance从某种角度上看起来有点像虚拟存储,也提供API,可以实现比较完整的镜像管理功能。所以理论上其他云平台也可以使用它。
Glance比较简单,又限于云内部,所以没啥可以多展开讨论的,不如看看新出来的块存储组件Cinder,目前我对Cinder基本的看法是总体的设计不错,细节和功能还有很多需要完善的地方,离一个成熟的产品还有点距离。
Cinder
OpenStack到F版本有比较大的改变,其中之一就是将之前在Nova中的部分持久性块存储功能(Nova-Volume)分离了出来,独立为新的组件Cinder。它通过整合后端多种存储,用API接口为外界提供块存储服务,主要核心是对卷的管理,允许对卷,卷的类型,卷的快照进行处理。
Cinder包含以下三个主要组成部分
API service:Cinder-api 是主要服务接口, 负责接受和处理外界的API请求,并将请求放入RabbitMQ队列,交由后端执行。 Cinder目前提供Volume API V2
Scheduler service: 处理任务队列的任务,并根据预定策略选择合适的Volume Service节点来执行任务。目前版本的cinder仅仅提供了一个Simple Scheduler, 该调度器选择卷数量最少的一个活跃节点来创建卷。
Volume service: 该服务运行在存储节点上,管理存储空间,塔处理cinder数据库的维护状态的读写请求,通过消息队列和直接在块存储设备或软件上与其他进程交互。每个存储节点都有一个Volume Service,若干个这样的存储节点联合起来可以构成一个存储资源池。
Cinder通过添加不同厂商的指定drivers来为了支持不同类型和型号的存储。目前能支持的商业存储设备有EMC 和IBM的几款,也能通过LVM支持本地存储和NFS协议支持NAS存储,所以Netapp的NAS应该也没问题,好像华为也在努力中。我前段时间还在Cinder的blueprints看到IBM的GPFS分布式文件系统,在以后的版本应该会添加进来到目前为止,Cinder主要和Openstack的Nova内部交互,为之提供虚机实例所需要的卷Attach上去,但是理论上也可以单独向外界提供块存储。
部署上,可以把三个服务部署在一台服务器,也可以独立部署到不同物理节点
现在Cinder还是不够成熟,有几个明显的问题还没很好解决,一是支持的商业存储还不够多,而且还不支持FC SAN,另外单点故障隐患没解决,内部的schedule调度算法也太简单。另外由于它把各种存储整合进来又加了一层,管理倒是有办法了,但是效率肯定是有影响,性能肯定有损耗,但这也是没办法的事了。
Openstack通过两年多发展,变得越来越庞大。目前光存储就出现了三种:对象存储、镜像存储和块存储。这也是为了满足更多不同的需求,体现出开源项目灵活快速的特性。总的说来,当选择一套存储系统的时候,如果考虑到将来会被多个应用所共同使用,应该视为长期的决策。Openstack作为一个开放的系统,最主要是解决软硬件供应商锁定的问题,可以随时选择新的硬件供应商,将新的硬件和已有的硬件组成混合的集群,统一管理,当然也可以替换软件技术服务的提供商,不用动应用。这是开源本身的优势!
原文链接:http://www.aboutyun.com/thread-10060-1-1.html