浅谈webpack打包原理
模块化机制
webpack并不强制你使用某种模块化方案,而是通过兼容所有模块化方案让你无痛接入项目。有了webpack,你可以随意选择你喜欢的模块化方案,至于怎么处理模块之间的依赖关系及如何按需打包,webpack会帮你处理好的。
关于模块化的一些内容,可以看看我之前的文章:js的模块化进程
核心思想:
- 一切皆模块:
正如js文件可以是一个“模块(module)”一样,其他的(如css、image或html)文件也可视作模 块。因此,你可以require(‘myJSfile.js’)亦可以require(‘myCSSfile.css’)。这意味着我们可以将事物(业务)分割成更小的易于管理的片段,从而达到重复利用等的目的。 - 按需加载:
传统的模块打包工具(module bundlers)最终将所有的模块编译生成一个庞大的bundle.js文件。但是在真实的app里边,“bundle.js”文件可能有10M到15M之大可能会导致应用一直处于加载中状态。因此Webpack使用许多特性来分割代码然后生成多个“bundle”文件,而且异步加载部分代码以实现按需加载。
文件管理
- 每个文件都是一个资源,可以用require/import导入js
- 每个入口文件会把自己所依赖(即require)的资源全部打包在一起,一个资源多次引用的话,只会打包一份
- 对于多个入口的情况,其实就是分别独立的执行单个入口情况,每个入口文件不相干(可用CommonsChunkPlugin优化)
打包原理
把所有依赖打包成一个bundle.js文件,通过代码分割成单元片段并按需加载。
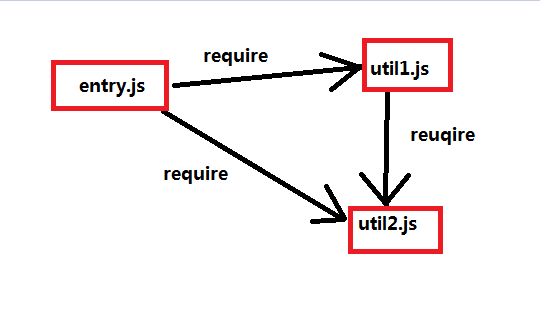
如图,entry.js是入口文件,调用了util1.js和util2.js,而util1.js又调用了util2.js。
打包后的bundle.js例子
/******/ ([ /* 0 */ //模块id /***/ function(module, exports, __webpack_require__) { __webpack_require__(1); //require资源文件id __webpack_require__(2); /***/ }, /* 1 */ /***/ function(module, exports, __webpack_require__) { //util1.js文件 __webpack_require__(2); var util1=1; exports.util1=util1; /***/ }, /* 2 */ /***/ function(module, exports) { //util2.js文件 var util2=1; exports.util2=util2; /***/ } ... ... /******/ ]);
- bundle.js是以模块 id 为记号,通过函数把各个文件依赖封装达到分割效果,如上代码 id 为 0 表示 entry 模块需要的依赖, 1 表示 util1模块需要的依赖
- require资源文件 id 表示该文件需要加载的各个模块,如上代码
_webpack_require__(1)表示 util1.js 模块,__webpack_require__(2)表示 util2.js 模块 exports.util1=util1模块化的体现,输出该模块