逻辑回归的数学原理推导及原理代码实现
1、逻辑回归算法是目前应用最为广泛的一种算法,虽然是回归算法,但是它解决的是分类问题,而不是回归问题,它的原理是将样本的特征与样本发生的概率,而概率是一个数字,因此将其称为回归算法。
2、对于逻辑回归因为得到的预测结果是事件的发生概率,因此它的预测值值域为0-1之间,而概率转换函数一般选用的是sigmoid函数,它可以将这个实数范围转换为0-1,并且0是一个分界点,当t>0时,概率p大于0.5,当t<0时,概率p<0.5。
3、基于逻辑回归算法的思路,建立适当的损失函数,其数学原理推导如下所示:














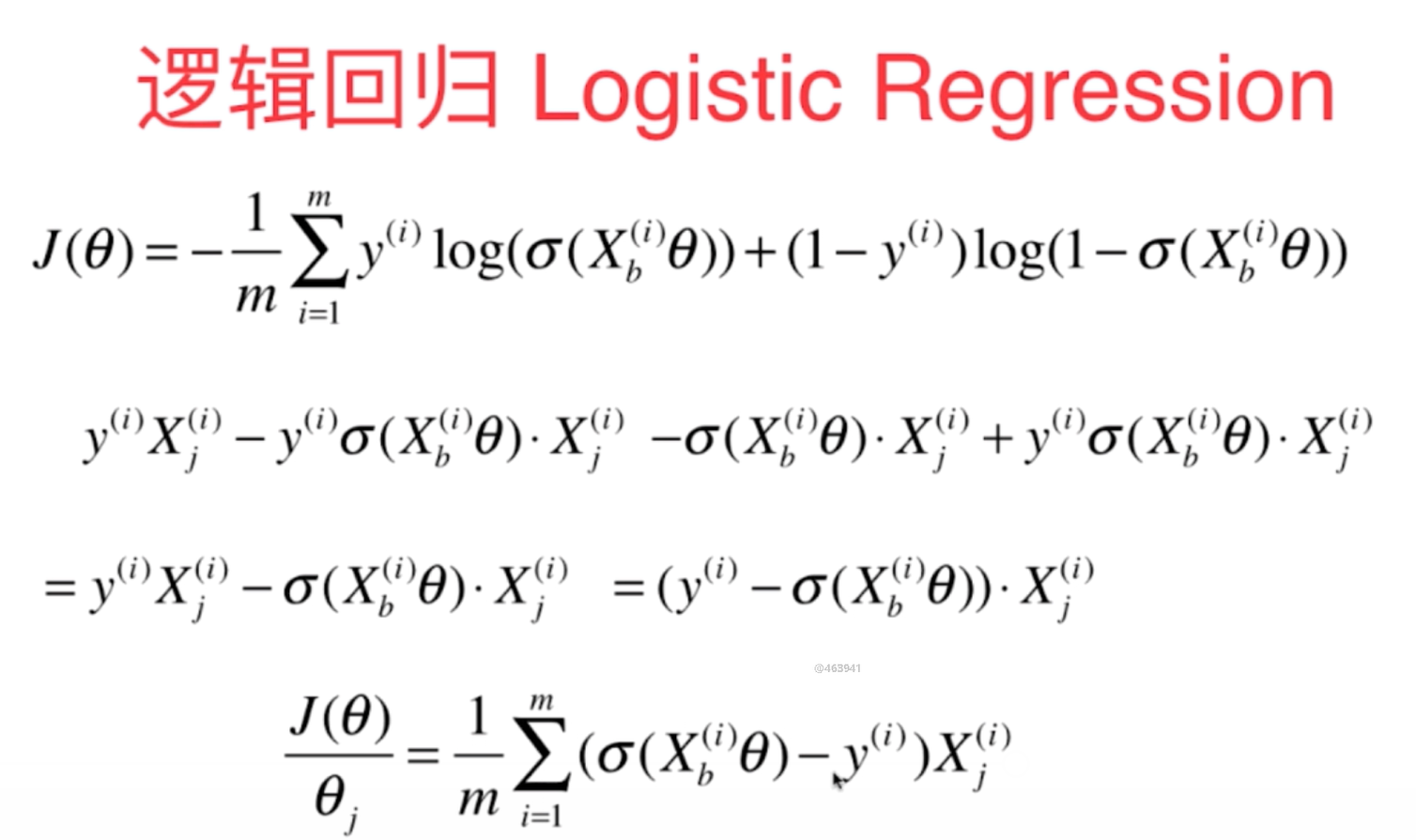


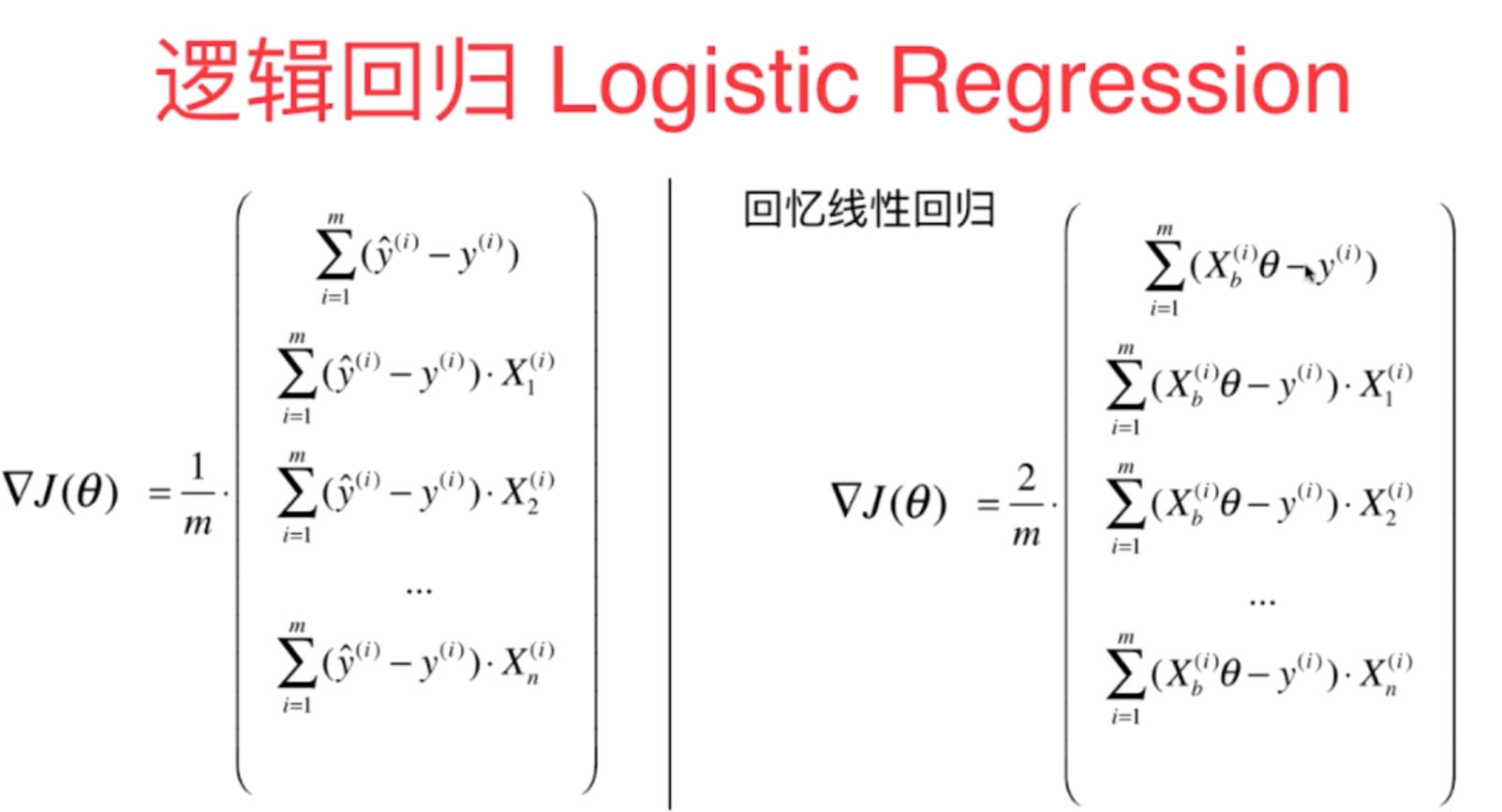
可以通过对比线性回归的损失函数看出来,它们的损失函数几乎是一致的,只是前面的系数差了一倍,另外对于函数的预测计算逻辑回归需要在线性计算的基础上通过sigmoid函数进行转换一下即可。
使用批量计算的方法实现逻辑回归的算法原理代码如下所示:
import numpy as np
import matplotlib.pyplot as plt
#定义概率转换函数sigmoid函数
def sigmoid(t):
return 1/(1+np.exp(-t))
x=np.linspace(-10,10,100)
y=sigmoid(x)
plt.figure()
plt.plot(x,y,"r",label="Sigmoid")
plt.legend(loc=2)
plt.show()
#根据线性回归的损失函数和逻辑回归的损失函数的相似性与一致性(只有前面系数不同,另外y估计的计算需要进行sigmoid函数转换即可))
def J1(theta,x_b,y): #损失函数的定义
y_hat=sigmoid(x_b.dot(theta))
return np.sum(y*np.log(y_hat)+(1-y)*np.log(1-y_hat))/len(x_b)
def DJ2(theta,x_b,y):
res=np.empty(len(theta))
res[0]=np.sum(sigmoid(x_b.dot(theta))-y)
for i in range(1,len(theta)):
res[i]=np.sum((sigmoid(x_b.dot(theta))-y).dot(x_b[:,i]))
return res*2/len(x_b)
def DJ1(theta, x_b, y): #梯度计算公式
return x_b.T.dot(sigmoid(x_b.dot(theta))-y)/len(y)
def gradient_descent1(x_b,y,eta,theta_initial,erro=1e-8, n=1e5): #采用批量梯度下降法来进行寻找损失函数的最小值
theta=theta_initial
i=0
while i<n:
gradient = DJ1(theta,x_b,y)
last_theta = theta
theta = theta - gradient * eta
if (abs(J1(theta,x_b,y) - J1(last_theta,x_b,y)))<erro:
break
i+=1
return theta
#利用iris数据集进行原理代码的验证
from sklearn import datasets
d=datasets.load_iris()
x=d.data
y=d.target
x=x[y<2,:2]
y=y[y<2] #逻辑回归适用于二元分类数据
print(x)
print(y)
plt.figure()
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=1)
x_b=np.hstack([np.ones((len(x_train),1)),x_train])
print(x_b)
theta0=np.zeros(x_b.shape[1])
eta=0.1
theta1=gradient_descent1(x_b,y_train,eta,theta0)
print(theta1)
from sklearn.metrics import accuracy_score
x_b=np.hstack([np.ones((len(x_test),1)),x_test])
y_hat=sigmoid(x_b.dot(theta1))
print(y_hat)
p=np.array(y_hat>0.5,dtype="int")
print(p) #输出预测的分类结果
print(y_test)
print(accuracy_score(p,y_test)) #输出预测的准确度