分工及贡献
组内有三人去考证了,只剩下6人
| 组员 | 分工 | 贡献比例 |
|---|---|---|
| 王永福 | 前后端,爬虫,博客主体 | 30% |
| 孙承恺 | 建模,算法设计,统筹 | 18% |
| 邱畅杰 | 爬虫 | 15% |
| 徐祖豪 | 前端数据可视化 | 13% |
| 张凌昕 | 前端数据可视化,部分博客 | 11% |
| 丁枢桐 | 数据可视化,聚类算法 | 13% |
GitHub提交日志
程序运行截图
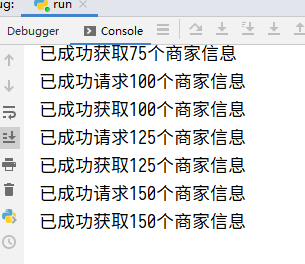
爬虫
服务器端
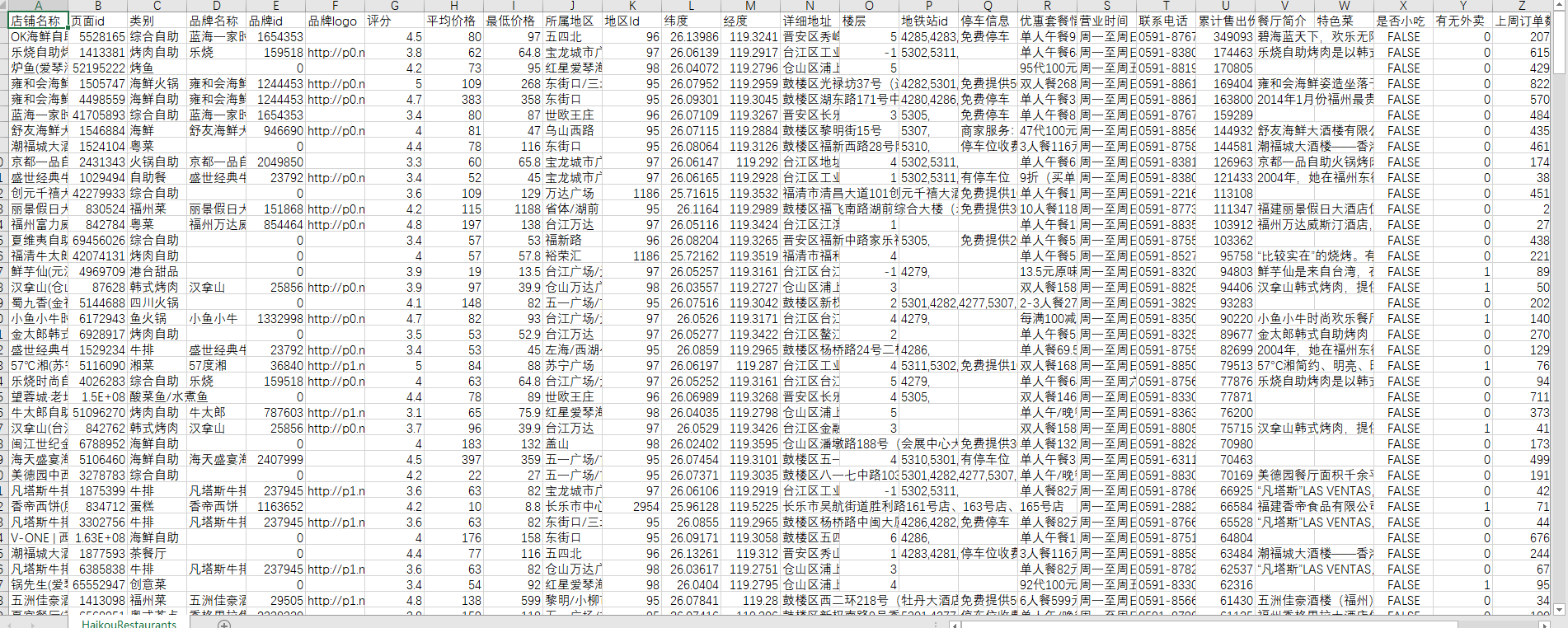
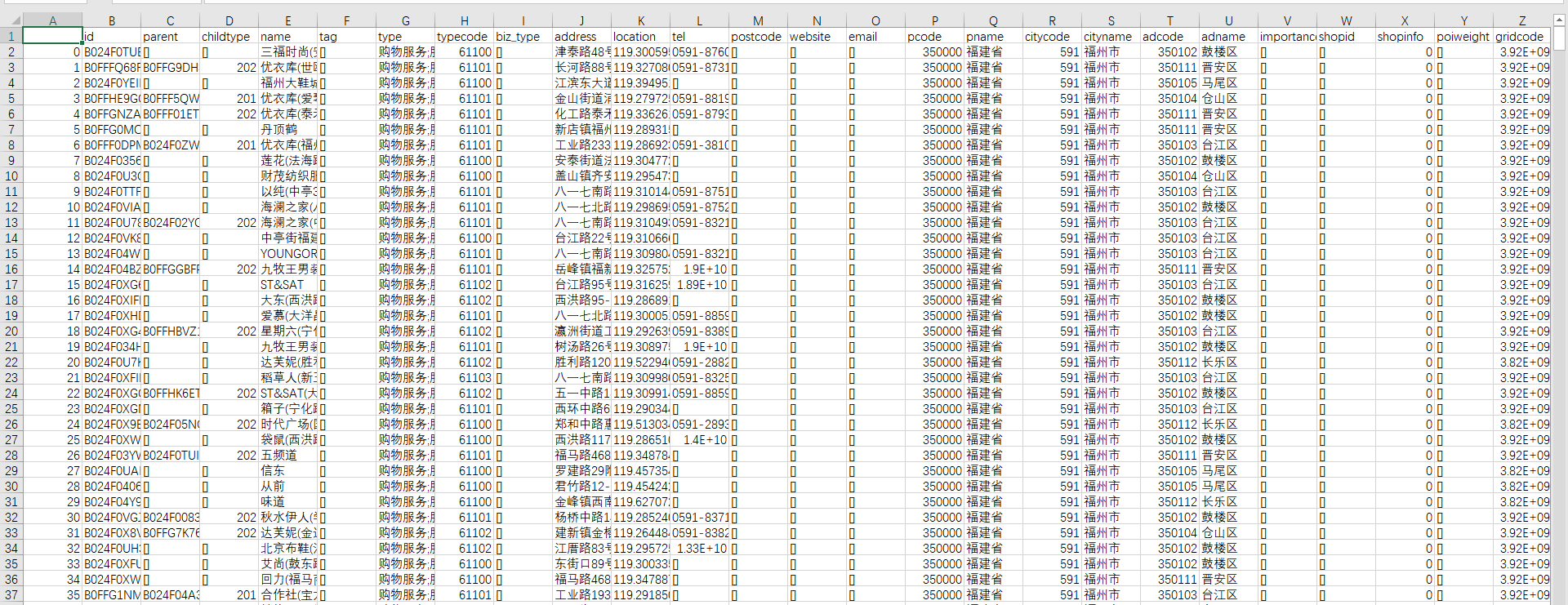
部分数据

程序运行环境
爬虫
- Anaconda 3
- Python 3.7
- 涉及的包比较多,这里不一一列出,稍后我会将Anaconda环境导出到
environment.yml并上传至GitHub,大家可以去看
服务器端
- Python
- Flask
- Flask-CORS
前端页面
- 建议Chrome 76或以上,其他没试过
前端构建
- Node.js 10
- Yarn包管理器
- Vue-cli 3
- 其他依赖包在
package.json中有,可以yarn install直接安装 - 另外需要可用的高德地图的Key
GUI界面



基础功能实现
数据爬取
根据题目要求,我们需要爬取相关数据,根据对题目的分析,以及对美团和大众点评、高德地图的前期调研,我们认为可以将前三个评测目标划为一组,数据一起爬取,因为它们需要的字段比较相似(可以见上面的数据截图);第四个目标我们在美团上找不到数据,大众点评难以爬取,因此转向高德POI搜索爬取。
美团的数据主要从手机版网页爬取(PC版网页没有经纬度且需要计算token),使用Chrome Developer Tools模拟手机访问网页抓取数据进行分析,发现Cookie只需要设置ci和uuid即可爬取,其他仿照抓取到的请求设置。
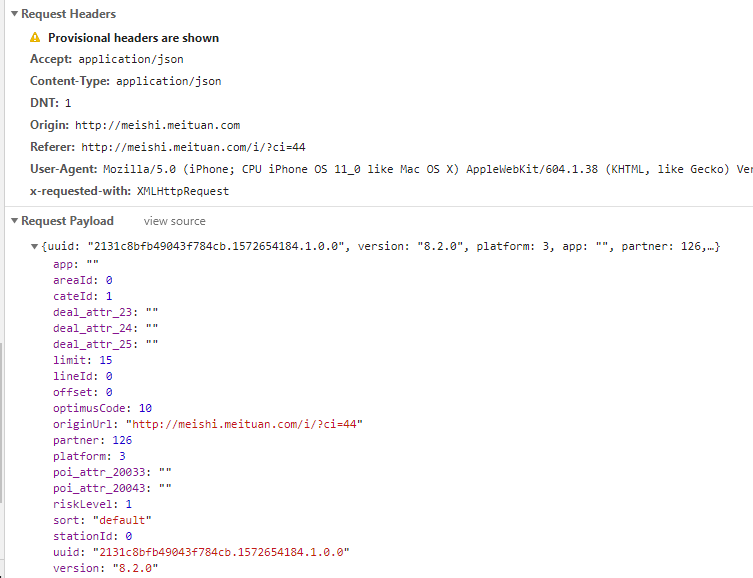
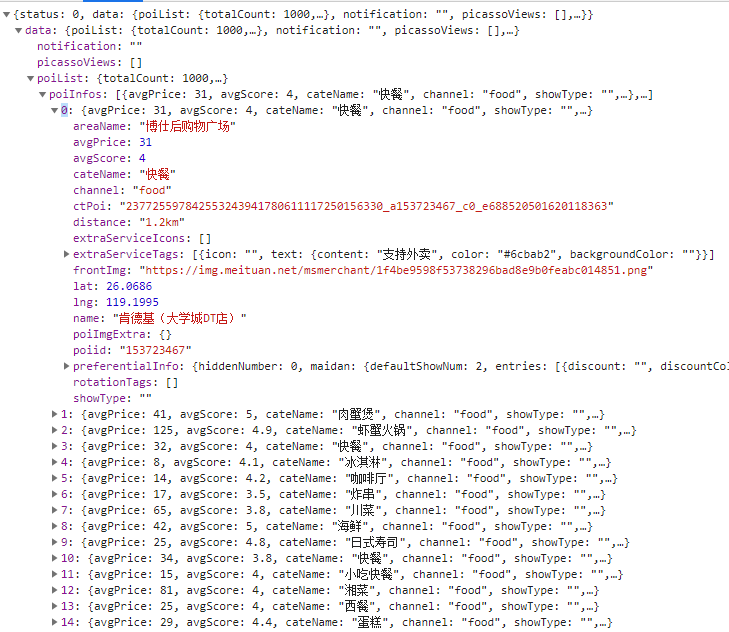
爬取时需要注意美团反爬技术非常硬,需要不断更换IP和ID,否则没一会就会白给,早上我们已经白给好多次了。我们的爬虫理论上具备获取所有数据的能力,但由于疯狂白给,最后只获取了少量数据用于制作demo。
另外高德API虽然不反爬,但是API有调用配额限制,爬多了也会白给。建议多准备几个Key
数据处理
获取到数据后,需要对数据进行预处理以进行展示,对于不同的评测目标,采取不同的方法
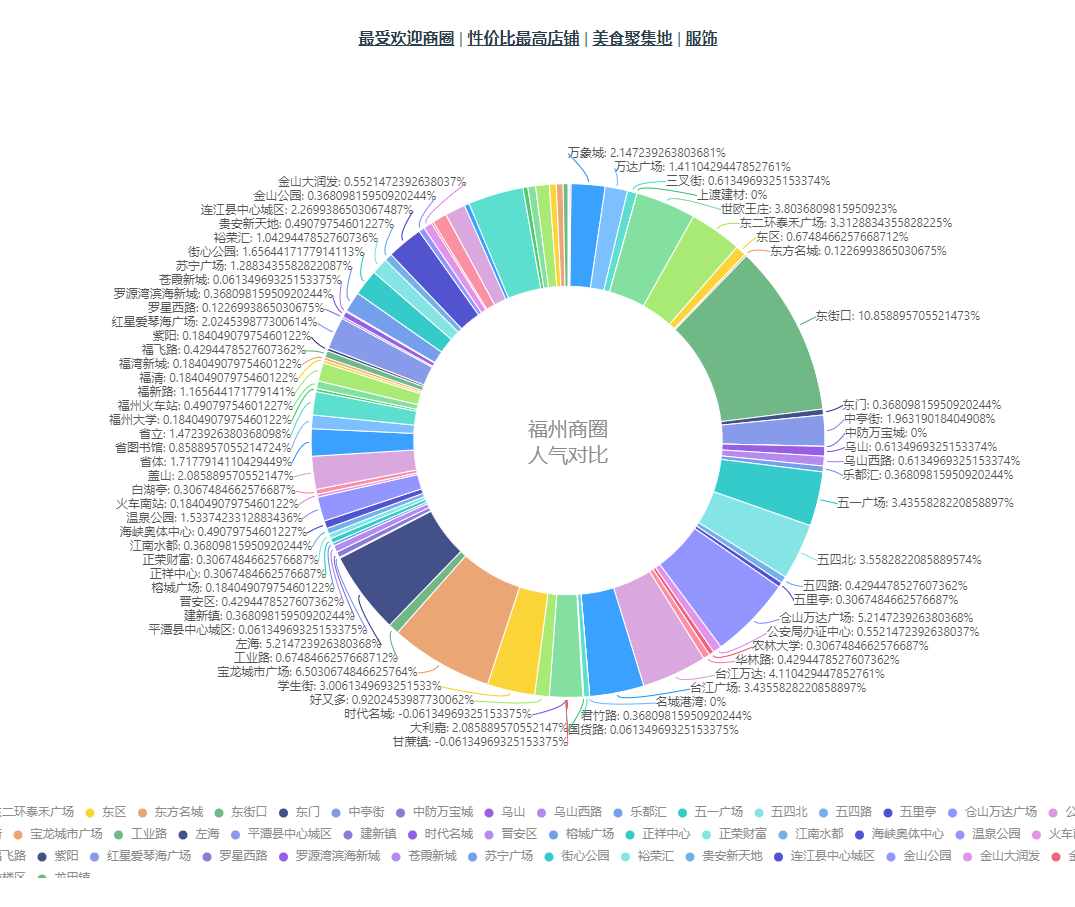
测评出福州最受欢迎的商圈
将美团爬取到的数据按销量降序排列,按商圈聚类,然后根据全局排名,分阶梯对每一个商铺赋权,再将商圈内的商铺权值求和,排序,得到最受欢迎的商圈。
分别测评出福州人均消费50以下,50-100、100-200、200以上最佳(性价比最高)的前五家美食餐厅(参考评价与价格)
这个比较简单,直接按人均消费所属阶层聚类,组内排序,第一关键字评分降序,第二关键字人均价格升序。
测评出福州最佳美食聚集地
两条路:
- 对每家商铺赋权并按经纬度聚类,生成聚类图,由于算法比较复杂且数据序列化困难,故Web端不采用此方法生成的数据,此方法生成的图可用
clustering中的代码生成 - 将原始数据提取经纬度直接在地图上打热力图。此方法较为简单,Web前端采用此方法。理论上虽有失偏颇,但是由于我们爬取的原始数据按销量和评分降序,因此爬到的都是排名靠前的,说是最佳美食聚集地应该也没什么问题吧
(逃
测评出福州服饰类综合评分最高的商圈
从高德地图爬取的数据参照第一个评测目标相似的方法处理
数据可视化
主要采用了Vue框架来管理视图路由,AntV进行可视化展示,展示效果可见截图。地图部分采用了高德地图JS SDK
服务器端
理论上不需要这部分,但是没用网络感觉很low,为了高级一点,也为了可扩展性,用Flask加了个服务端,动态提供数据
UI
跟数据可视化一起做了,页面上的东西基本都是有交互的,饼图有Tooltip,点击下面的图例可以取消显示某一类,做到部分展示。地图可以旋转,改变俯仰角,热力图是3D的
关于功能的其他想法
高级可视化
可以在可视化上做一些炫酷或者高级的交互,比如说:
- 像SyncFusion的Essential JS 2 的可视化组件Chart的Drilldown的多级饼图
- 热力图交互,如点击弹出推荐列表
- 根据实时数据的动态视图,或类似延时摄影的视图变迁
数据分析
如果能爬到大量数据
- 多平台交叉验证
- 评论情感分析
- 时间序列分析
脑洞
做一整个推荐平台,同时收集用户数据
遇到的困难及解决方法
王永福
困难
- 数据来源反爬机制过强
- 数据可视化不熟练,前端不熟练,Python不熟练
- 人少
解决方法
- 找代理池,找开源项目
- 捡起来学
- 一人顶俩
丁枢桐
困难
- 对网络爬虫相关的类库不熟悉,对于相关网站特别是反爬虫的网站难以获取有效信息
- 对用web前端进行数据可视化的方法不熟悉,只能当场找模板现学
解决方法
- 现场学习
- 现场学习
张凌昕
困难
在这次现场编程中我主要负责的是前端这一块,在写饼图的时候,我刚刚开始不是很懂G2,并且在挑选饼图形式的时候,比较不知道挑选哪个比较好
解决方法
多看一些模板,并且有的模板上会给一些注释,让我更了解G2的一些使用方法,用起来更容易。在饼状图格式的挑选上,先是选了一个不是太好看的,后来又选了一个比较合适的。
徐祖豪
困难
- 有几个组员要去考教资,现场编程只有六个人
- 前端技术太久没复习,不太熟悉
解决方法
- 好在提前知道有几个同学会缺席,所以事先分配了任务,进展还算顺利
- 现场学习
孙承恺
困难
短时间的分析和设计很令人烦躁,api接口没开放增加工作量
解决方法
化繁为简
邱畅杰
困难
数据难以爬取,token算法未知
解决方法
对于美团爬取手机版页面,采用代理池
对于大众点评,放弃
马后炮
- 徐祖豪:如果自己能再早几天复习,准备充足一点,项目的进展会更顺利
- 孙承恺:如果这门课不是必修,那么我一定不会选
- 丁枢桐:如果之前我有系统地学习如何使用python进行网络爬虫,那么这次就会很快地为团队获取有效数据。而不会导致前面一直在为数据苦恼
- 丁枢桐:如果之前我有系统地学习web前端的开发,那么这次就可以写出更棒的UI界面
- 王永福:如果我没这么菜,这次可以完成得更好
(如果这门课不是必修,那么我一定不会选) - 邱畅杰:如果黑夜给了我黑色的眼睛,那么我将用它来寻找光明
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| Estimate | 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 90 | 120 |
| Analysis | 需求分析(包括学习新技术) | 30 | 40 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审 | 0 | 0 |
| Coding Standard | 代码规范(为开发制定合适的规范) | 0 | 0 |
| Design | 具体设计 | 30 | 50 |
| Coding | 具体编码 | 30 | 30 |
| Code Review | 代码复审 | 0 | 0 |
| Test | 测试(自我测试,修改,提交修改) | 0 | 0 |
| Reporting | 报告 | 30 | 30 |
| Test Report | 测试报告 | 0 | 0 |
| Size Measurement | 计算工作量 | 0 | 0 |
| Postmortem & Process Improvement Plan | 事后总结并提出过程改进计划 | 30 | 30 |
| 合计 | 125 | 155 |
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 6 | 210 | 3092 | 8 | 8 | 重新复习了下爬虫 |