待续
Zero:Python库的导入
from __future__ import print_function
import tensorflow.keras
import cv2
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.callbacks import Callback, EarlyStopping, ModelCheckpoint, TensorBoard
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adadelta
from tensorflow.keras.utils import to_categorical
import glob
import numpy as np
import random
import os
import sys
import time
One:各种参数的设置
width = 32
height = 32
channel = 3
train_ratio = 0.8
lr = 0.1
batch = 8
epoch = 4
patienceEpoch = 5
crop_fix_size = (30, 30)
crop_ratio = 0.5
mirrorRatio = 0.5
horizontalRatio = 0.3
verticalRatio = 0.3
diagonalRatio = 0.3
netClass = "VGG16"
lossType = "categorical_crossentropy"
"""
channel:图片通道数(RGB)
train_ratio:训练集占总数居的比例
batch:从数据集中一次拿出的数据量
patinenceEpoch = 5
crop_fix_size:裁剪图片宽高
crop_ratio:数据中裁剪的比例
mirrorRatio:数据中镜像的比例
horizontalRatio: 水平镜像的比率
veriticalRatio:垂直镜像的比率
diagonalRatio:对角镜像的比率
netClass:网络的类别
lossType: 损失函数类别,categorical_crossentropy(交叉熵函数)
"""
Two:自定义读取文件函数
"""
Parameters:
Path:文件夹路径,String
return :
files:所有图片列表,List
labels:所有图片序号列表,List
len(subdirs):图片类别个数
"""
def CountFiles(path):
files = []
labels = []
subdirs = os.listdir(path)
subdirs.sort()
print(subdirs.sort())
for index in range(len(subdirs)):
subdir = os.path.join(path, subdirs[index])
sys.stdout.flush()
for image_path in glob.glob("{}/*.jpg".format(subdir)):
files.append(image_path)
labels.append(index)
return files, labels, len(subdirs)
Three:划分数据,一部分数据用于训练优化神经网络模型参数,另一部分用于测试模型
files, labels, clazz = CountFiles("/root/flower_photos")
c = list(zip(files, labels))
random.shuffle(c)
files, labels = zip(*c)
labels = np.array(labels)
labels = to_categorical(labels, clazz)
print(labels[:10])
train_num = int(train_ratio * len(files))
#将数据集划分为训练和测试,按train_ratio来确定比例
train_x, train_y = files[:train_num], labels[:train_num]
test_x, test_y = files[train_num:],labels[train_num:]
Four:将图片转为np.array数据
size = width,height
def LoadImage(image_path):
img = cv2.imread(image_path)
img = cv2.resize(img, dsize=size, interpolation=cv2.INTER_AREA)
img = img.astype("float32")
img /= 255.
if random.random() < crop_ratio:
im1 = img.copy()
x = random.randint(0, img.shape[0] - crop_fix_size[0] - 1)
y = random.randint(0, img.shape[1] - crop_fix_size[1] - 1)
im1 = im1[x:x+crop_fix_size[0], y:y+crop_fix_size[1], :]
im1 = cv2.resize(im1,dsize=size, interpolation=cv2.INTER_AREA)
img = im1
if random.random() < mirrorRatio:
im1 = img.copy()
if random.random()< horizontalRatio:
im1 = cv2.flip(im1, 1, dst=None)
elif random.random() <verticalRatio:
im1 = cv2.flip(im1, 0, dst=None)
elif random.random() <diagonalRatio:
im1 = cv2.flip(im1, -1, dst=None)
im1 = cv2.resize(im1, dsize=size, interpolation=cv2.INTER_AREA)
img = im1
return np.array(img)
Five:生成图像数据数组,以batch为单位
def LoadImageGen(files_r, labels_r, batch=32, label="label"):
start = 0
while start < len(files_r):
stop = start + batch
if stop > len(files_r):
stop = len(files_r)
imgs = []
lbs = []
mm = time.time()
for i in range(start,stop):
imgs.append(LoadImage(files_r[i]))
lbs.append(labels_r[i])
mm = time.time() - mm
yield(np.array(imgs), np.array(lbs))
if start + batch < len(files_r):
start += batch
else:
c = list(zip(files_r, labels_r))
random.shuffle(c)
files_r, label_r = zip(*c)
start = 0
Six:定义模型并编译模型
input = Input(shape=(width,height, channel),name='image_input')
model_vgg16_conv = VGG16(weights=None, include_top=False, pooling='avg')
output_vgg16_conv = model_vgg16_conv(input)
output = Dense(clazz, activation='softmax',name='predictions')(output_vgg16_conv)
model = Model(inputs=input, outputs=output)
model.compile(loss=lossType,
optimizer=Adadelta(lr=lr,decay=0),
metrics=['accuracy']
)
Seven:Loss函数值和TensorBorad的数据可视化
#Loss函数值
class LossHistory(Callback):
def on_train_begin(self, logs={}):
self.losses = []
def on_batch_end(self,batch,logs={}):
self.losses.append(logs.get('loss'))
#TensorBorad的数据可视化
class TrainValTensorBoard(TensorBoard):
def __init__(self, log_dir='./logs', **kwargs):
training_log_dir = os.path.join(log_dir, 'train')
super(TrainValTensorBoard, self).__init__(training_log_dir, **kwargs)
self.val_log_dir = os.path.join(log_dir, 'validation')
def set_model(self, model):
self.val_writer = tensorflow.summary.FileWriter(self.val_log_dir)
super(TrainValTensorBoard,self).set_model(model)
def on_epoch_end(self, epoch, logs=None):
logs = logs or{}
val_logs = {k.replace('val_', 'epoch_'):v for k,v in logs.items() if k.startswith('val_')}
for name,value in val_logs.items():
summary = tensorflow.Summary()
summary_value = summary.value.add()
summary_value.simple_value = value.item()
summary_value.tag = name
self.val_writer.add_summary(summary,epoch)
self.val_writer.flush()
logs = {k:v for k,v in logs.items() if not k.startswith('val_')}
super(TrainValTensorBoard, self).on_epoch_end(epoch, logs)
def on_train_end(self, logs=None):
super(TrainValTensorBoard, self).on_train_end(logs)
self.val_writer.close()
Eight:权重和TensoBoard的实例化
history = LossHistory()
tensorBoardCallBack = TrainValTensorBoard(
log_dir="./tensorboard",
histogram_freq=0,
write_graph=True,
write_grads=True,
batch_size=batch,
write_images=True
)
modelCheckpoint = ModelCheckpoint(
filepath="./model.hdf5",
monitor='val_acc',
verbose=0
)
earlyStopping = EarlyStopping(monitor='val_acc', patience=patienceEpoch)
神经网络模型的fit_generator,训练迭代之后,打印损失列表
steps_per_epoch = int((len(train_x) + batch - 1) / batch)
validation_steps = int((len(test_x) + batch - 1) / batch)
outPut = "class num:{},train num:{},batch:{},train steps:{},validation steps:{}".format(
clazz,
len(train_x),
len(train_y),
len(test_x),
batch,
steps_per_epoch,
validation_steps
)
print(outPut)
model.fit_generator(
LoadImageGen(
train_x,
train_y,
batch=batch,
label="train"
),
steps_per_epoch=steps_per_epoch,
epochs=epoch,
verbose=1,
validation_data = LoadImageGen(
test_x,
test_y,
batch=batch,
label="test"
),
validation_steps=validation_steps,
callbacks=[
earlyStopping,
tensorBoardCallBack,
modelCheckpoint,
history
]
)
print(history.losses)
运行结果
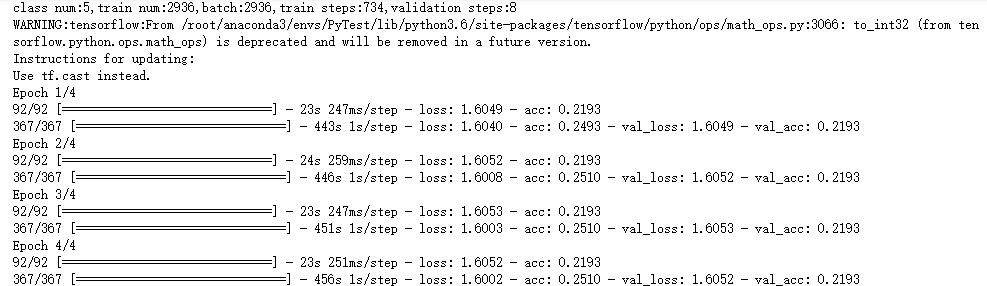
参考