借用官网的一个例子:
假设存在一个序列,序列中的元素是具有不同颜色与形状的图形,我们希望在序列里相同颜色的图形中寻找满足一定顺序模式的图形对(比如在红色的图形里,有一个长方形跟着一个三角形)。 同时,我们希望寻找的模式也会随着时间而改变。
在这个例子中,我们定义两个流,一个流包含图形(Item),具有颜色和形状两个属性。另一个流包含特定的规则(Rule),代表希望寻找的模式。
Flink 开发的时候,经常会遇到这种情况,数据的输入源有多个,需要将一些流先关联起来(比如:清洗规则、动态配置),再做后续的计算。
对于这样的场景,可能很容易就想到使用 join api ,直接将两个流 join 起来。
实际上,这样个需求,使用 join api 是不太适合的, join 是基于窗口的,要在窗口内有关联的数据,才能进行后续的计算。 这个需要中,规则流的某些规则在整个程序的执行周期里,可能只会有一次。
对应这样的需要,Flink 提供了 “Broadcast State” 来解决,具体请查看官网:The Broadcast State Pattern https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/stream/state/broadcast_state.html (现在有中文翻译了)
调用DateStream 的 broadcast 方法,将一个流解释成广播流,再调用非广播流(keyed 或者 non-keyed)的 connect() 关联, 将 BroadcastStream 当做参数传入。 这个方法的返回参数是 BroadcastConnectedStream,具有类型方法 process(),传入一个特殊的 CoProcessFunction 来书写我们的关联逻辑。
一般来说使用广播流的时候,在每个并发中都会保留广播的全部数据(可能没办法区分那些是需要的,那些不需要),这样就会导致广播状态越来越大,如果广播状态更新比较频率的,就不太适用了。
注: 广播状态使用的是 Operator State,运行时保存在内存中。
所以就进入了今天的重点是 connect 在非广播流中的使用。
官网关于 connect 算子,只在 算子概览(https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/stream/operators/) 中简单的描述了 connect 算子
DataStream,DataStream → ConnectedStreams "Connects" two data streams retaining their types. Connect allowing for shared state between the two streams. DataStream<Integer> someStream = //... DataStream<String> otherStream = //... ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
看过上面广播状态内容的同学应该知道,connect 的顺序是很重要的,那非广播流的 connect 呢?
进入主题前,先思考这几个问题:
1、两个 non keyed 流 connect 的时候,数据是怎么分配的(不同并发的数据怎么分,随机分配、循环?)
2、keyed 流 connect non keyed 流 的时候,数据是怎么分配的
3、non keyed 流 connect keyed 流 的时候,数据是怎么分配的
4、两个 keyed 流 connect 的时候,数据是怎么分配的
对应问题4,很容易就想到: 两个流的 keyBy 都是对下游 CoProcessFunction 的并发做的分区,所以相同 key 的数据一定会发到一起。
为了解决其他问题,有了如下程序:
大致业务: 数据流关联配置流,获取编码对应转码值,关联不上的就用默认值。
为了方便数据源就实现个 SourceFunction 生成 0 到 300 的数值,拼接 5 位随机的字符串
class RadomSourceFunction extends SourceFunction[String] { var flag = true override def cancel(): Unit = { flag = false } override def run(ctx: SourceFunction.SourceContext[String]): Unit = { while (flag) { for (i <- 0 to 300) { var nu = i.toString while (nu.length < 3) { nu = "0" + nu } // code + other ctx.collect(nu + "," + StringUtil.getRandomString(5)) Thread.sleep(2000) } } } }
主程序如下:
val config = new FlinkKafkaConsumer[String]("dynamic_config", new SimpleStringSchema, Common.getProp) val configStream = env .addSource(config) .name("configStream") val input = env.addSource(new RadomSourceFunction) .name("radomFunction") // 非并发的souce function 不能添加并发 .map(str => str) .setParallelism(4) val stream = input.connect(configStream) .process(new CoProcessFunction[String, String, String] { var mapState: MapState[String, String] = _ //var map: util.HashMap[String, String] = null override def open(parameters: Configuration): Unit = { // thinking broken, if use keyed state, must keyby upstream // Keyed state can only be used on a 'keyed stream', i.e., after a 'keyBy()' operation. mapState = getRuntimeContext.getMapState(new MapStateDescriptor[String, String]("mapState", classOf[String], classOf[String])) //map = new util.HashMap[String, String]() } override def processElement1(element: String, context: CoProcessFunction[String, String, String]#Context, out: Collector[String]): Unit = { // checkouk map keys val it = mapState.keys().iterator() var size = 0 while (it.hasNext) { val key = it.next() size += 1 } //val size = map.size() println("keys size : " + size) val citeInfo = element.split(",") val code = citeInfo(0) var va = mapState.get(code) // var va = map.get(code) // 不能转码的数据默认输出 中国(code=xxx) if (va == null) { va = "中国(code=" + code + ")"; } else { va = va + "(code=" + code + ")" } out.collect(va + "," + citeInfo(1)) } override def processElement2(element: String, context: CoProcessFunction[String, String, String]#Context, collector: Collector[String]): Unit = { println(getRuntimeContext.getIndexOfThisSubtask + ", " + element) val param = element.split(",") // update mapState mapState.put(param(0), param(1)) //map.put(param(0), param(1)) } override def close(): Unit = { mapState.clear() } }).setParallelism(4) val sink = new FlinkKafkaProducer[String]("non_key_connect_demo", new SimpleStringSchema(), Common.getProp) stream.print() env.execute("NonKeyedConnectDemo")
然后就。。。。
Caused by: java.lang.NullPointerException: Keyed state can only be used on a 'keyed stream', i.e., after a 'keyBy()' operation. at org.apache.flink.util.Preconditions.checkNotNull(Preconditions.java:75) at org.apache.flink.streaming.api.operators.StreamingRuntimeContext.checkPreconditionsAndGetKeyedStateStore(StreamingRuntimeContext.java:223) at org.apache.flink.streaming.api.operators.StreamingRuntimeContext.getMapState(StreamingRuntimeContext.java:216) at com.venn.stream.api.connect.KeyedConnectDemo$$anon$1.open(KeyedConnectDemo.scala:67) at org.apache.flink.api.common.functions.util.FunctionUtils.openFunction(FunctionUtils.java:36) at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.open(AbstractUdfStreamOperator.java:102) at org.apache.flink.streaming.api.operators.co.CoProcessOperator.open(CoProcessOperator.java:59) at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:291) at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$beforeInvoke$0(StreamTask.java:473) at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.runThrowing(StreamTaskActionExecutor.java:47) at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:469) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:522) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:721) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:546) at java.lang.Thread.run(Thread.java:745)
直接赏我个 NullPointerException,突然想起来,如果不做 keyBy,不能用 keyed state
这点小小的麻烦,当然难不倒我
直接上 使用 hashmap 存更新流的数,一样看结果(注: 数据量不大可以使用 Operator State)
代码基本一样,就不重复添加了,具体请查看 github: https://github.com/springMoon/flink-rookie/tree/master/src/main/scala/com/venn/stream/api/connect
执行图如下:
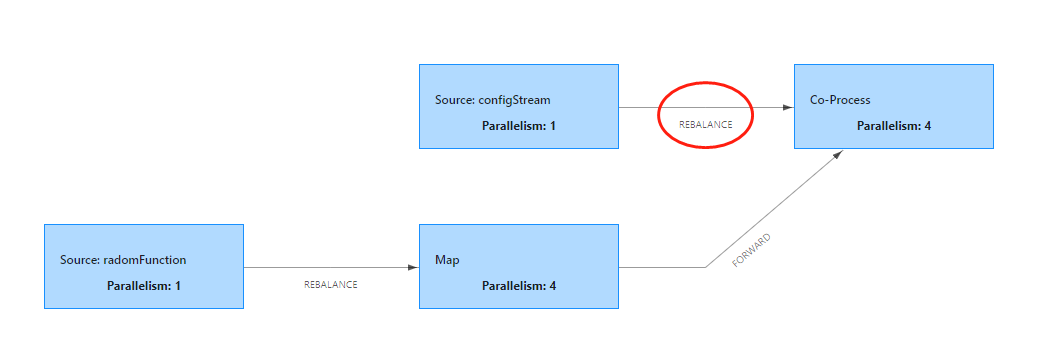
配置流是1个并发,下游 Co-Process 是 4 个并发,特意在处理更新流的procesElement2 中打印出接收到数据对应的 subtask id
println(getRuntimeContext.getIndexOfThisSubtask + ", " + element)
从 kafka 输入数据,查看打印的数据,随意截取部分数据贴在这里:
subtask id : 2, 031,营口市 subtask id : 3, 016,宁波市 subtask id : 1, 030,锦州市 subtask id : 0, 041,黄州市 subtask id : 1, 034,朝阳市 subtask id : 3, 020,丽水市 subtask id : 1, 038,襄城市
对应 configStream 往下游发数据的策略是 REBALANCE ( 数据循环的往下游算子发 官网: https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/stream/operators/#physical-partitioning)
数据在各个并发之间循环发送,但是啊,没有做 key 的流,只有一个并发拿到了配置数据,其他的怎么办呢?
只有在不用 broadcast 和 keyed 的时候,需要考虑这个问题,代码里面已经给了解决办法,感兴趣的同学可以去看下
总结下 connect 算子的内容,一般场景下,使用 broadcast connnect 和 keyed connect,能保证每个并发(key)能拿到需要的数据,广播是通过广播数据到下游的所有并发来保证的,keyed 是通过 对相同键做 key 来保证的。
keyed 、 non keyd 、 broadcast 的例子 都可以在 github : https://github.com/springMoon/flink-rookie/tree/master/src/main/scala/com/venn/stream/api 可以找到
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
