多路复用I/O
它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
流程图如下:
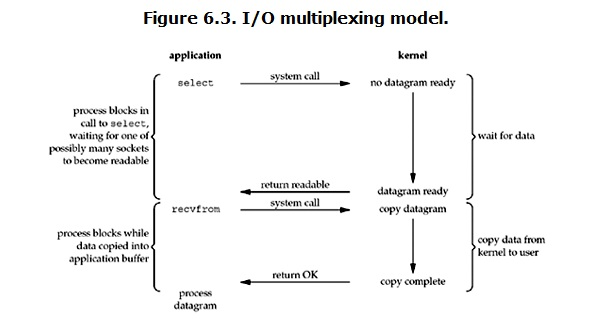
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
强调
1. 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2. 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
结论: select的优势在于可以处理多个连接,不适用于单个连接


1 from socket import *
2 import time
3 import select
4
5
6 server = socket(AF_INET, SOCK_STREAM)
7 server.bind(('127.0.0.1',8080))
8 server.listen(5)
9 server.setblocking(False)
10
11 data_dic={}
12 read_list=[server,]
13 write_list=[]
14 print('start....')
15 while True:
16 # 括号里面应该有四个参数,最后一个参数timeout默认的话就是一直在这边等待,直到接收到参数。
17 # 如果设置超时延时,那么如果在3s未接受到数据,他会自动运行下面的代码。但是如果他在1s就接收到数据,
18 # 就会直接执行下面程序。
19 rl,wl,xl=select.select(read_list,write_list,[]) #read_list=[server,conn1,conn2,conn3,conn4]
20 # print('read_list:%s rl:%s wl:%s ' %(len(read_list),len(rl),len(wl))) #rl=[conn1,conn2]
21 for sk in rl:
22 if sk == server:
23 conn,addr=sk.accept()
24 read_list.append(conn)
25 else:
26 # sk.recv(1024)
27 # print(sk)
28 data=sk.recv(1024)
29 write_list.append(sk)
30 data_dic[sk]=data
31
32 for sk in wl:
33 sk.send(data_dic[sk].upper())
34 data_dic.pop(sk)
35 write_list.remove(sk)
1 from socket import *
2 import os
3
4 client=socket(AF_INET,SOCK_STREAM)
5 client.connect(('127.0.0.1',8080))
6
7 while True:
8 msg='%s say hello' %os.getpid()
9 client.send(msg.encode('utf-8'))
10 data=client.recv(1024)
11 print(data.decode('utf-8'))
异步IO
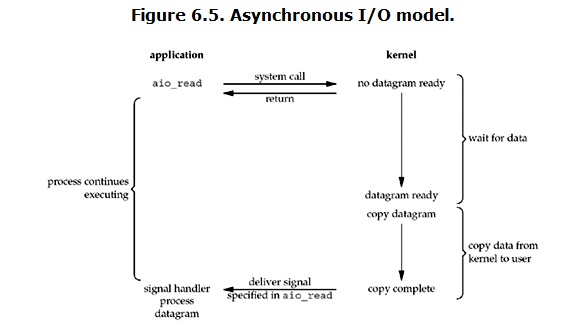
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。流程图如下:
上节课复习:
1、协程
什么是?
协程指的是单线程下由应用程序级别实现的并发
即把本来由操作系统控制的切换+保存状态,在应用
程序里实现了
协程的切换vs操作系统的切换
优点:
切换速度远快于操作系统
缺点:
一个任务阻塞了,其余的任务都无法执行
ps:只有遇到io才切换到其他任务的协程才能提升
单线程的执行效率
为何用?
把单个线程的io降到最低,最大限度地提升单个线程的执行效率
如何实现?
from gevent import spawn,monkey;monkey.patch_all()
2、io模型
block io
nonblocking io
1、对cpu的无效占用率过高
2、不能即时反馈客户端的信息