- 文章名称:Fast Failure Detection and Recovery in SDN with Stateful Data Plane
- 利用SDN的带状态数据平面进行快速故障检测和恢复
- 发表时间:2017
- 期刊来源:COMMUNICATIONS SURVEYS AND TURORIALS
ABSTRACT (摘要)
在SDN中解决节点、链路故障时,通过网络能力建立替代的路径依赖于控制器的可达性和控制器交换机之间的the round-trip times(RTTs)。而且,当下的SDN数据平面概念对于故障检测,比如 OpenFlow的“快速故障转移”,不允许程序员改变交换机的侦测机制,因此导致SDN操作员依赖于专门的管理接口实现保证的检测和恢复延迟。本文提出SPIDER,一个类似OpenFLow的管道设计,提供1)基于分时链路探测的监测机制和2)快速重路由流,甚至对于在远距离故障的情况,而不用管控制器的可行性。SPIDER的优点是,基于带状态数据平面概念(比如OpenState和P4),可以实现在很短时间内的故障检测和恢复延迟,对于过载和响应性故障可以做到可配置性权衡。本文提出SPIDER管道设计,行为模型,流表内存影响分析,另外实现了对OpenState在恢复延迟性能和数据包损失方面的验证。
I INTRODUCTION(介绍)
网络变成SDN架构,提供了更多的机会以实现更高效的流量工程策略,而在运营商网络中,故障恢复机制是最重要的流量工程设施,因为他们对连接故障使用流量重路由快速反应。现在的SDN中的故障恢复的支持实现相比传统的Multi-Protocol Label Switching(MPLA)Fast Reroute要弱很多,并且被认为不如传统的方法可靠。这个缺陷的缘由是因为流量工程应用比如说故障恢复这样的应用,涉及到数据平面(SDN的关键)的限制,大多的数据平面采用OpenFlow概念的match-actions规则,。但是,OpenFlow的缺点——OpenFlow的适应性和重配性只能通过远程控制器进行执行,对于期望的流量监控和流量控制器没办法保证开销和延迟需求,进而影响了流量重路由方案的高效执行实现。对于故障的情况,OpenFlow快速故障转移仅当在检测到故障的交换机上存在选择性路径才执行。不幸的是,这样的选择性路径可能不可行,这种情况下,需要控制器的介入在网络的另外一点建立重路由,本文认为通过快速数据路径,假设不同的转发规则集可以根据观测到的网络状态进行应用。本文认为,如果完全将状态监测机制和不同状态的规则集暴露给控制器上的应用开发人员,可以通过保留逻辑集中的SDN方法的可编程性。
本文提出SPIDER,为带状态SDN数据平面提出的一种数据包处理管道设计,可以通过完全可编程监测和重路由机制直接在交换机上实现。SPIDER的启发来源于传统的Bidirectinal Forwarding Detection(BFD),和MPLS Fast Reroute (FRR)。SPIDER的特点重路由和监测都是完全的在数据平面实现的,同时不会减慢控制器。因此,SPIDER可以实现很短的恢复延时(<1ms),并且在开销和性能之间权衡实现可配置性。以下将提出在基于OpenState和P4 实现SPIDER,在一些网络拓扑结构上实现它的性能评估。
II RELEATED WORK
研究社区已经在SDN中如何快速进行故障恢复进行研究,通过减少交换机依赖控制器建立选择路径,使SDN更加可靠。Sharma et al在[9]中展示了,在大型OpenFlow网络依赖基于控制器的存储获取carrier grade recovery time(<50)是多么难。为解决这个问题,作者提出基于BFD daemon 运行在交换机上,并且与OpenFlow Fast-failover group type(OpenFlow快速转移组类型)进行整合,实现的恢复时间在50ms内。相似地,VanAdrichem 和Kempf、Sgambelluri、Borokhovich针对不同的场景问题各提出一些解决的方法。
本文通过扩展两个早期的会议[15][16](最先在基于OpenState的行为模型执行快速重路由并且提供可编程的故障检测包括流表项分析结果、数据包损失结果、heartbeat overhead)。本文通过P4实现SPIDER,在将SPIDER与传统技术(比如BFD和MPLS Fast Reroute)对比,再谈论数据平面应用于当前SDN平台的协调方案。。SPIDER是实现利用可编程带状态概念在快速路径实现故障检测和故障恢复的先例。
III STATEFUL DATA PLANE ABSTRACTIONS
OpenFlow为数据包转发描述了一个无状态的数据平面概念。遵从SDN的精髓,控制和数据平面分离,网络中的状态仅通过控制器进行保存,基于反应的方法,根据事件(比如新来的流,拓扑改变,基于监控的事件由流表统计信息的定期轮询触发)对设备的流表进行更新。我们认为提高可扩展性和网络应用的响应可以通过采用动态带状态概念解决,交换机可以提前预知不同集合的转发行为,比如,流表项可以根据不同级别的数据包级别事件和时间触发器(timer)动态的激活或者停用。OpenState、FAST、OVS和P4是典型的带状态转发。OpenState和FAST通过为状态迁移定义精致的结构,比如状态表和原语(primitives),为编程数据平面状态机提供了很好的支持。相反,OVS由于特殊的学习动作,允许在运行时根据数据包匹配当前的流表项,创建新的流表项,对于带状态转发提供了不明确的支持。另外,我们注意到研究社区已经开始研究OVS中的带状态快速路径9a stateful fast-path in OVS)[18]。最后,当前版本的P4语言允许基于内存注册表定义转发行为,内存注册表可以在数据包处理时进行访问。
因为两个原因,我们使用OpenState进行设计实现。第一个原因是,我们相信OpenState提供了一个简单的转发概念,可以更好的描述SPIDER以Finite State Machines(FSMs)形式实现的行为模型,以及对每一个流表状态进行操作。第二个原因是SPIDER建立时,假设可以通过线速对转发状态进行更新,直接处理快速数据路径(fast data path)。OpenState 概念同样建立在这个假设,并且硬件上基于TCAM的架构的实验性证明已在[20]解决。最后P4可以用于配置转发概念等同于OpenState。
A . OpenState
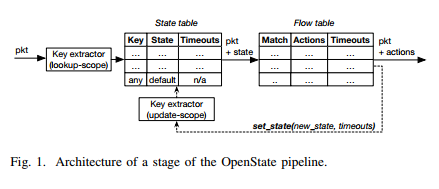
有必要对OpenState进行了解。Figure 1描述了OpenState管道的不同元素。 传统OpenFlow的流表前面是用于存储“流状态”的状态表。每次,一个新的数据包都是通过流表进行处理,它首先会匹配状态表。匹配的执行是精确地匹配(比如非通配符)flow key,flow key 是“lookup-scope”(比如一些列OpenFlow的首部字段标识符)定义的字段。如果在状态表中根据flow key没有找到匹配的状态表项,状态表将返回“default”状态,否则返回对应匹配的状态。然后数据包通过流表进行处理,这里可以定义流条目以匹配状态表返回的状态值。。而且,新定义的“set-state”动作,用于在管道中的任意状态表进行插入、更新状态表。在set-state 动作中,状态表是通过使用flow
key进行更新,不同于用于lookup 阶段和“update-scope”阶段的定义(在解决bidirectional 流是必要的)。最后,idle 和hard 状态超时值可以进行定义,等同于用于OpenFlow流表项。“Rollback state”与每一个timeout关联,它的值用于每次timeout时间到期对状态进行更新。在给定条目与给定间隔的任何数据包不匹配之后,空闲超时到期,而硬超时从插入/更新状态条目的瞬间开始计数。在配置完lookup-scope,update-scope和flow table,state table 初始化是空的。。接着,基于流表定义的set-state action进行填充或者更新state table,并且由于数据包匹配流表中的流表项进行执行。
IV. APPROACH SKETCH
SPIDER提供了机制,使用动态的方法执行故障检测和即时重路由需求,而不要求控制器的介入。控制器仅需要在启动时,提供交换机的状态表和用不同的转发行为填充流表。没有分布式的协议需求,不同的转发行为都是通过在数据平面对数据包标记不同的特殊标签和带状态原语进行解决。SPIDER的特征是由著名的传统协议比如BFD和MPLS FRR启发。VII中,将讨论关于SPIDER设计和传统技术的细节。
备份路径预先规划。
引入了备份路径的定义,控制器需要提供全局视图,并且根据需求定义主路径和备份路径。每一个可能发生故障的节点,对主路径造成影响的Fi都需要提供备份路径。Fi的备份路径可以使用一些主路径,但是这要求围绕节点i提供绕道的主路径。换句话说,尽管链路故障情况下,使得j不能够到达i,或者是其他到达j的路径可能存在,我们要求Fi的备份路径不使用任何属于i的链路。这样做的原因是为了保证故障转移时间的延迟小于1ms。比如,如果分析是链路故障或者节点故障的话,可能需要控制器的参与或者其他缓慢信号。由于这个原因,SPIDER假设最坏的情况,即节点i损坏,因此应该完全禁止和i节点相关的路径。能够用于计算备份路径的最佳集合的问题公式在[22]中提出。最后,如果所有的备份路径已经提供,SPIDER可以保证对于单一故障节点Fi场景的即时保护,而不需要控制器计算选择性路由或者更新流表。然而,对于两个、多个故障发生的情况需要通过控制器动态介入进行支持。
故障检测
SPIDER使用标签携带任意的首部字段(比如MPLS标签或者VLAN ID)区别不同转发行为,并且执行故障检测和交换机到交换机之间的故障信令。Figure 2描述了SPIDER支持的不同转发情景,当 正常场景时,数据包进入网络用tag=0标记,并且通过主要路径进行路由(Fig. 2a)。为了检测故障,SPIDER不依赖任何交换机相关的特征,比如Fast-failover(快速故障转移),二是基于交换双向“心跳”数据包 提供简单的检测方案。我们假设只要数据包从给出的端口接收,端口就可以可靠的传输其他数据包。当在给出的间隔内,没有收到数据包,这个节点可以请求它的邻居节点发送一个heartbeat。如图2d所示,heartbeat可以通过对任何数据包标记 tag=HB_req进行请求。一个节点收到这样的数据包将会执行两种操作,i)重置 tag=0 ,并且发送这个数据包到下一跳, ii) 创建tag=HB_reply的副本并且将它送回同样的输入端口。这样的方式,请求heartbeat的节点直到它的邻居节点仍然是可达的。heartbeat 仅当接收数据包速率低于指定阈值时发送。如果在超过指定的timeout内,没有数据包(要么数据要么heartbeat)收到,端口将被置为DOWN。端口的状态将在这个端口一收到数据包时变为UP状态。

快速重路由
当一个端口被置为DOWN,意味着面向邻居节点i的本地故障情况,进入的数据包标记为Fi并且发送到一个选择性端口(如图2b)。这可能是属于改道或者相同输入端口接收数据包的第二个端口。最后一个例子,我们引入“bounced” packet。Bounced packets 被SPIDER用于通知远程故障情况。事实上,他们沿着最初的路径往回转发,直到某个节点能够通过备用(detour)路径进行转发。在Fig 2c中,当节点2接收了一个携带tag=F4 的跳跃数据包,它将更新需要去F4的状态(换路径),并且沿着备用路径转发数据包。根据带状态SPIDER的本质,state F4通过node2进行维护,意味着所有将来的携带 tag=0 的数据包会标记上tag = F4 ,并且沿着备用路径直接发送。在例子中,我们将node 2称为在状态F4需要的重路由节点,而在检测到故障的节点和重路由节点之间的路径组成部分我们称之为 “反弹路径(bounce path)”。
路径探测
故障时暂时的,所以SPIDER提供了一种探测机制,当故障一解决时,则建立起源路径转发。状态为Fi的重路由节点按时产生探测数据包,检测节点i的可达性。至于,heartbeat packets,probe packets 不会被交换机或者控制器忘记,他们是通过简单地复制并且标记相同的数据包,交由重路由节点处理。在Fig. 2e中,node 2复制了一个tag=0 的数据包。 一个复制的数据包用于标记tag= 4 发送到备用路径,另一个数据包标记tag= Pi,然后根据原来最初的路径进行转发。如果node i 变成可达,它将反弹探测数据宝到重路由节点。状态为Fi的节点接收到探测数据包之后将会引起状态迁移,这将使得最初的路径重新支持正常的转发。
flowlet-aware failover(支持Flowlet的故障转移)
SPIDER同样解决了在远程故障转移时数据包重新排序的问题。在Fig. 2c中,尽管新的 tag = 0 数据包到达重路由节点,但是有一个或者更多个更“老”的数据包可能还再bounce path中进行传输。这样的情况可能会在接收端引起数据包传输乱序,结果是导致像传输层协议比如TCP协议 不必要的吞吐量降级。SPIDER实现了“Flowet-aware”转发方案在[23]有所介绍。当SPIDER已经意识到故障,对于属于同一分组的数据包采用相同的转发策略;换句话说,数据包仍然使用首要的路径(primary path)进行转发,直到给出的idle timeout到期。这样的timeout可以通过控制器在启动时进行估计,并且应该在bounce path给出状态Fi的重路由节点设置最大的RTT。在支持重路由之前高效地等待这样的一个时间,最大化没有数据包仍然在bounce path传送的可能性,这样可以最小化接收器上乱序的风险。
V. IMPLEMENTATION
本节提供实现SPIDER的必要的管道设计和流表配置。管道(Fig. 3)基于4个不同的流表。一个进入的数据包首先由table 0 和 table 1进行处理。这两个模块仅执行无状态转发(相当传统OpenFlow),特点在之后描述。然后再由状态表2和3进行处理。这些表分别实现了Remote Failover(RF) FSM和 Local Failover(LF) FSM。数据包通常由表2进行处理,当主路径被远程的故障影响,表2负责重路由数据包。如果在表2中没有远程故障,数据包将提交给表3,表3解决本地故障的情况(比如直接查看本地端口)。表2中的状态更新由bounced packets触发,而表3实现heartbeat-based监测机制,这在第IV中有所介绍。尽管table1是无状态的,由于这个原因而不需要维护任何状态,但是它负责触发在表2和表3上的状态更新。
table0. 在提交数据包给表1之前,执行以下无状态处理。
-
对于从边缘端口接收到的数据包(比如。直接连接一个主机的端口):push an initial MPLS label to store the tag
-
对于从传输端口(比如,连接另一个交换机的端口)接收到的数据包:将输入端口写入元数据区域(metadata field),用于之后从表1触发状态更新。
table1. 处理只需要无状态转发的数据包,比如转发行为不依赖于状态的数据包。
-
在边缘端口接收到数据包,设置tag=0,然后提交到下一个表。
-
从主路径的上一个节点接收到数据包:将MPLS标签移除(pop),然后直接发送到对应的输出端口(目的主机所在)
-
接收到有tag = Fi 的数据包:直接发送到备份(detour)端口(对于每种需求和Fi的值都是唯一的);在重新进入主路径之前,最后一个detour节点设置tag=0。状态Fi中的需求重新路由节点例外,在这种情况下,这些分组的路由决策存储在表2中。
-
Heartbeat request(tag = HB_req):数据包被复制,复制的其中之一设置tag=HB_reply,然后通过进入端口发送,另外一份设置tag=0,然后提交到下一个表。
-
Heartbeat replies(tag=Pi):直接在对应的探测路径输出端口发送数据包(比如主路径上Pi的需求和值都是唯一的,Fig. 2e)。
最后,表1对表2和表3执行以下的状态更新。
- 对所有的数据包:在表3执行状态更新,声明接收到数据包的状态为UP。
- 仅对探测包: 表2只执行状态更新,将流的状态从Fi迁移为Normal。

Table2(Remote Failover FSM). Figure 4 显示了一个简化的FSM版本。通过交换机对不同的流量需求进行维护状态。正如lookup scope和update scope概述。这种情况下,通过以太网源和目的地址元组识别源-目的地址请求,编程人员可能配置不同字段的聚合来描述这个请求(比如IP source/destination元组或者4-元组传输层协议)。仅支持单一故障的场景情况,不允许在宏状态之间转换Fi(状态在迁移到另外一个Fi之前必须先设置为Normal)。Figure 5描述了具有宏状态Fi爆炸的Remote Failover FSM详细版本。在启动时,每个请求的状态都被置为默认的Normal。在接收到一个携带Fi的bounced 数据包之后,之后的相同流数据包通过detour路径转发,并且将源路径状态设置为Fault signaled。之前介绍的小流量感知路由方案,在这里通过状态超时实现。当在Fault signaled状态时,数据包携带tag=0的数据包到来(比如来自源节点 ),仍然通过primary path路径进行转发。这个行为将持续直到idle timeout δ1到期,即,在δ1间隔没有收到该需求的数据包后,这应该被设置为等于在bounce path 测量的RTT值。为了防止请求仍然锁定在状态Fault signaled,设置hard timeout δ2 > δ1,因此,在最多δ2间隔后总是达到下一个状态Detour ready。当处于Detour enabled状态时,数据包被设置tag=Fi,并且直接发送到备用路径(detour)。在这种状态下,hard timeout δ5确保按时的在primary path发送探测数据包。当处于状态Need probe时,将复制匹配的第一个数据包:一份发送到detour path,向目的地址发送,另外一份携带tag=Pi,并且通过原始的主路径(primary path)发送给节点i。如果节点i再次变成可达,它将通过bouncing the packet 响应探测的节点。在表1重路由节点探测包的匹配将处罚Remote Failure FSM 重置状态为Fault resolved。当处于Fault Resolved,状态Fault signaled相同的流量感知路由方案将被应用。这种情况下,为了保留选择性路由,设置了idle timeout 和 hard timeout,直到当前突发包结束。这种情况下,δ3必须设置为最大的延迟区别于primary path和backup path。在δ3和δ4到期后,状态设置回Normal,因此在detour上的发送将停止,数据包将发送给表3再发送到primary port。
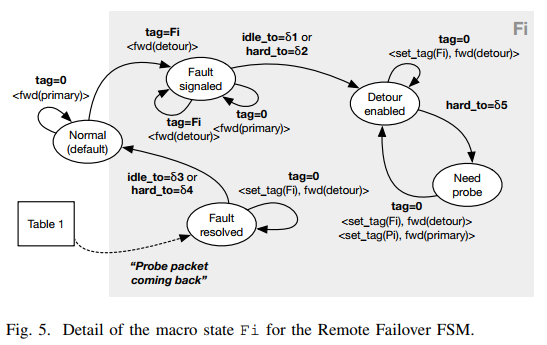
Table3(Local Failover FSM)。Figure6描述了通过这个表实现的FSM。流在每一个输出端口聚集(在metadata 区域编码),意味着所有相同目的的数据包都有一样的状态。FSM有两个宏状态,即UP和DOWN。当在DOWN状态时,数据包转发到任意的端口(属于一个detour或者bounced packets的输入端口,依据之前计划的备份策略)。在启动时,所有流默认为UP状态:need heartbeat,即指一个heartbeat packets必须产生并且收到回复,因此端口持续保持为UP。实际上,这个状态下第一个匹配到的数据包将会携带tag=HB_req进行发送,并且状态更新为UP:heartbeat requested。在这个状态下,数据包将会在primary ouput port发送,直到硬超时δ7到期,这种情况下,端口将被声明为DOWN。超时时间δ7代表了产生heartbeat request和对应的接收回复之间的最大间隔。table 1每次接收到数据包(数据包或者探测包或者heartbeat),端口的状态重置为UP:wait.The Local Failover FSM 将会处在这个状态δ6的时间(硬超时),在这之后,状态将被设置为UP:need heartbeat。因此,δ6代表了某一个给出端口防止heartbeat数据包产生,要求接收的数据包最小数据速率的倒数。如果δ7到期,端口将再次声明为DOWN。再次,数据包将以Fi进行标记(i节点直接通过端口相连接)并且在其他的某个端口进行转发。类似于Remote Failover FSM,硬超时δ5确保数据包产生,甚至在端口为DOWN的状态下。
总之,Table I 总结了SPIDER使用的不同timeout。
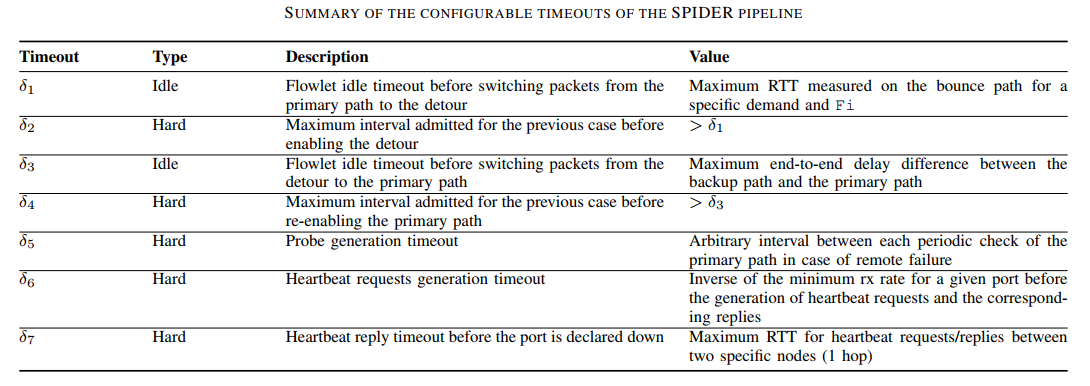
我们强调的是如何调整这些值,程序员可以控制并且利用
- i) 对于给定端口(δ6+δ7)检测出精确的延迟
- ii)给定需求的探测数据宝引起的流量过载级别(δ5和δ6),远程故障转移数据包重排序的风险(δ1,δ2,δ3,δ4)。以下实验结果基于这些参数进行提出。

OpenState-based prototype
我们使用一个修改的OpenFlow Ryu控制器以支持OpenState,实现了SPIDER。SPIDER源码在[25]中可以获取。对于实验性能评估,我们使用携带CPqD OpenFlow 1.3版本的软件交换机[27] Mininet[26]进行。
P4-based prototype
为了证明SPIDER管道设计的可行性,我们同样提供P4实现的SPIDER。这个实现可以在[28]中找到,并且这是基于openstate.p4,它是一个类库,可以被其他P4项目简单的重用,实现带状态数据包处理, 它利用等同于OpenState的表概念。换句话说openstate.p4允许基于每个流的状态表达转发行为,每个流的状态可以通过数据包匹配事件或者超时进行更新。我们使用P4软件交换机BMv2测试基于P4实现的SPIDER。以下,我们讨论SPIDER的可行性和在基于P4的可编程目标openstate.p4的一些担忧:
-
State table: 根据给定的查找范围或更新范围,依赖执行的访问类型(读取或写入),根据从每个数据包中提取的流密钥索引,进行维护流量的状态。我们使用P4的存储数组实现state table。我们使用hash功能高效地映射flow keys到有限的内存空间。显然地,当使用hash功能时,主要的问题是关于碰撞,多个表共享相同的内存空间时就结束。在SPIDER例子中,碰撞应该适当的解决,防止流根据另一个流设置的故障状态进行转发。这个问题可以通过P4定义碰撞处理机制或者对一个“extern” object实现类似的功能进行解决。后者是一种机制,在P4语言最近的版本中有所介绍,它允许程序员参考target-specific结构,比如键-值存储唯一的对流的键和状态进行映射,显然的解决了碰撞问题。然而,openstate.p4对于不重要的碰撞处理方案提供了原生的(native)支持,它通过实现一个带链的哈希表,允许固定数量的键-值 couples共享相同的索引。我们不提供任何关于方法性能的insight(观点),相反,我们使用它来为P4 target证明SPIDER的可行性。
-
State timeouts: SPIDER侦测故障的能力依赖于估计timeout events的能力(比如,在给出端口δ7时间内未接收到数据包)。openstate.p4 的State timeouts是通过将进入数据包的时间戳与存在状态表的idletimeout 和hard timeout值对比。然而,数据包的时间戳并非P4配置支持的特征。在我们的时间中,我们依赖BMv2 target的能力增加timestamp 元数据(metadata)到进入的数据包。而且,故障检测延迟依赖于时间戳间隔尺度(granularity),比如一个target提供 几秒 间隔尺度将不能够检测到故障,除非低于1秒。
VI PERFORMANCE EVALUATION
A. Flow entries analysis
当保证了检测和恢复时间以及拓扑独立,对于解决方法的适用性潜在性故障是关于大量流的,这些流可以被交换机内存限制,并且依赖于网络拓扑。我们在此根据流表项和流状态需要的内存,评估用交换机实现SPIDER所需要的资源。我们开始定义D为交换机需要提供的最大值,F为能够影响请求的故障数量的最大值(即最长主路径的长度),以及P,最大交换机端口数量。我们可以通过Big-O 概念为O(D × F)模拟流表需要的数量。实际上,对于table 0来说,需要的流表数量等于P;对于table 1,最坏的情况是,我们对于每一个请求的每一个fault(D × F)有一个表项;对于table 2,我们总是精确为7 × D × F,对于table 3精确为P×(3+2 × D)。总之,我们有大量的表项顺序为P+D×F+D×F×Pand then of D×F+ D × P。假设F>>P,我们可以推断出表项的数量为O(D×F)。
如果我们想更具网络的数量评估复杂性,我们可以观察最坏的情况F=N=E=+C,N是节点的数量,E为边缘节点数量,C为核心节点数量。假设,使用相交的路径的保护方案,这是规则方面最苛刻的,因为所有的Fi都通过入口边缘节点进行管理,并且具有全流量矩阵,我们得到D= E(E-1) 约等于 E2。在最坏的情况下,我们用一个单一节点管理所有的请求的所有故障,每个请求的主路径是最可能的,因此F=N。这种情况下,表项的数量将会是O(E2×N )。
在Table II,我们报告了网格网络n*n的值,在这,边缘节点是网格的外部节点,并且对于每一对边缘节点都有流量需求。另外,O(E^2 × N)的值,我们在表中包含每个节点的值(min,maxx,average),为端到端保护的情况进行计算,其中主路径是最小的(number of hops),并且备份路径是与主路径不相交 最短的节点路径。规则的数量要依据SPIDER在V中描述的实现,在[25]中也有可能。我们可以观察到,尽管最大值总是比复杂分析估计的值要小很多,我们可以有把握地说,这些是服务提供商的运营商级路由器的合理数字,远低于数据中心交换机的能力。显然,对于更高效的保护方案是基于分布式处理状态Fi(比如segment protection),我们希望在每个节点规则数量更低。
只要和状态相关,table2对于节点n需要Dn表项,n是重路由节点,Dn是请求的数量。对于表的宽度,我们需要考虑总共可能的状态为1+4Fn,Fn是管理的远程故障数量。相似地,对于stage 3,我们仅有5个可能的状态并且表项的数量等于P。
B. Detection mechanism
为了评估基于heartbeat的SPIDER检测机制的效率,我们考虑了一个简单的两个节点一条链路的实验场景,仅在一个方向上以1000pkt/sec进行发送。Fig 7,我们展示了在链路故障时,相比δ6 (heartbeat interval)和 δ7( heartbeat timeout) 数据包损失的数量。正如期望那样,数据包损失的数量随着heartbeat interval和timeout降低而下降。通常,丢弃的数据包的数量取决于故障发生的确切时刻 δ6和δ7。所报告的曲线是在随机时刻再现失败的10次不同尝试的结果的平均值。

C. Overhead
显然,为少量丢包付出的代价是由于heartbeat packets带来的开销。然而,SPIDER为了故障检测,利用在相反方向的流量,并且这减少了heartbeat packets的数量。在前一节提到的相同的两个节点场景 ,我们已经评估了在生成200到0 pkt/sec的递减流量分布时引起的开销。如Fig8 所示。我们可以看到,只要相反的流量速率比heartbeat request速率(1/δ6)高,能观察到0或者比较低的信令开销。当流量速率下降,由于heartbeat引起的开销趋向于弥补失去的数据包直到阈值。

D. Comparsion with a reactive OpenFlow approach
我们对基于SPIDER实现的案例对应到一个重反应OpenFlow(OF)应用,这个应用仅当检测到故障并且通知控制器才能够对流进行修改。网络如Fig. 9a所示。对于主路径和备路径,链路故障同样也在图中标明,我们考虑了一个逐渐增加的请求数量,每个请求的数据包速率为100pkt/sec。对于OF例子,我们借助CPqD软件交换机,使用Fast-failover(FF) group type的检测机制实现,另外在交换机上使用不同的RTTs检测故障和控制器。对于SPIDER,我们使用一个2ms heartbeat间隔(δ6)以及1ms的timeout(δ7)。对于所有考虑的流,没有可用的本地备份路径: 在SPIDER例子中,网络能够自动的通过bounceing packets从故障恢复到主路径,而在OF例子中,控制器的介入需要恢复连接性。
获取的结果如Fig. 9b所示。我们可以看到SPIDER数据包损失总是要比OF低。需要注意的是,即使使用的heartbeat间隔很小,对于网络来说这实际上不是一个问题,因为在存在反向流量的情况下,开销按比例减少,因此它永远不会影响链路可用容量。timeout的值依赖于heartbeat 回复传送的最大延迟,它在高速链路上主要依赖于传播并且可以通过给heartbeat replies赋值最大属性,将其设置为很小的值。而在OF例子中,损失数据包的数量随着交换机-控制器的RTT增加而增加。显然,数据包损失的数量会随着请求增加而上升,因为在控制器安装新的规则之前接收总的数据包的数量也会增加。

VII. Discussion
A.Comparision with BFD
BFD[7]是一个广泛使用的协议,用于提供快速回复机制,它不依赖于底层的媒介和协议。当使用BFD,有两个实体,即转发实体,建立一个会话,在这里,控制数据包交换来检验会话本身的活性。在通常情况下,要监视的会话表示双向链路,但它也可以是多跳路径。在BFD中检测故障的模型称之为Asynchronous Mode,会话终端节点以固定的速率发送BFD。如果在给定的检测timeout内,一个系统停止接收这些数据包,路径被认为是故障的。数据包发送速率和检测timeout可以通过网络管理员执行产生短的有保证的检测延迟。可选的,一个端点可以用所谓的Demand Mode明确地请求另外一个节点 active/deactive(触发/使无效)控制包传输。在两个模式下,一方检测故障的能力取决于设备本地控制平面跟踪接收到的控制数据包之间经过的时间的能力,从而跟踪控制平面本身的活跃程度。由于这个原因,有三种操作方式,即定义Echo Function用来测试设备的转发平面。当使用这个功能,特殊的Echo 数据包通过两方之一的控制平面,在任意的间隔进行发送,期望这些数据包通过转发平面的另一端点进行环回。
在SDN的背景下,设备的控制器是分离的并且逻辑集中在地理位置偏远的地方。现在SDN平台[30],[31]已经提供了检测故障的方法,类似于BFD的Asynchonous Mode,这个方法,请求远程控制器在特别的设备端口(通过OpenFlow Packetout)发送特殊组成的数据包,并且期待在给定的timeout内从临近节点(通过OpenFlow PacketIn)进行接收。然而,由于SDN控制器控制channel的延迟和开销,很难保证和BFD一样短的检测延迟。
SPIDER通过提供不依靠于慢控制channel 检测故障的方法改进了SDN。实际上,在SPIDER,基于heartbeat的操作模型类似于BFD的Echo Function,检测延迟可以通过设置合适的δ6和δ7,进行解决,对于给定的交换机和端口来说,这是独一无二的。我们 相信SPIDER代表了在BFD之上的改进。实际上,SPIDER操作仅仅执行在fast-path,比如,在TCAM速度,不同于BFD基于缓慢的、本地设备控制平面实现。因此,实现SPIDER的目标的最小检测延迟在很大程度上取决于目标提供的时间戳粒度和两个设备之间的传播延迟。另外一个SPIDER超越BFD的优势是它不需要定义分开的控制协议,相反,相同的数据包重复利用,通过使用任意的首部区域进行携带heartbeats(原型实现的MPLS标签)。
SPIDER相对于BFD的缺陷:
-
Security:BFD定义了一种验证会话的方法,可以防止攻击者与系统交互获取会话状态。而SPIDER没有使用任何机制来验证数据包携带标签的合法性。由于这个原因,SPIDER标签应该在相同的验证域内使用,丢弃在边缘携带不合法的首部进入的数据包,并且控制对网络物理访问防止攻击者的指令。
-
False positives()
在会话结束前,通过设置连续丢包的最小值,BFD能够防止 false positives(即,错误地宣布会话失败)。事实上,存在传输错误,一些控制数据包可能无法识别并且echo packets不能够环回。相反,在SPIDER,端口的状态错误在第一个heartbeat请求丢失时触发,损坏的heartbeat请求将会引起端口状态错误,因此导致主路径和备份路径之间不必要的波动。由于这个原因,SPIDER应该首选可信的通信channels(比如有线媒体而不是无线)。虽然,heartbeat数据包仅当输入流量很低时智能地请求,因此我们希望,对于大多数时间,链路上两个方向流动的是流量,heartbeat数据包本身丢失时很少的事件。 -
Adminstrative down:(没看明白)
BFD允许网络运营商以管理方式将链路通知为关闭,例如 用于维护,从而触发设备的快速反应。而在另外一方面,SPIDER提出允许down状态仅当故障检测时发生。但是,可以很容易地扩展实现,以接受LF和RF FSM中的附加状态,以声明流量或端口受故障影响而不触发周期性链路探测过程。在这种情况下,控制器应该能顾直接添加或者替换状态表中的一个表项。 -
Down state synchronization:
在一些例子中,仅有链路中两个方向中的一个方向会被破坏,这在光纤中是常见的事。当使用SPIDER,在配置检测timeout后,数据包进入方向的一方将会检测到第一个故障,因此停止这个端口上流量的发送,接着,另一端在检测timeout后也将把状态设置为down,导致两倍的故障转移时间。BFD相反,应用会话状态同步机制,因此,第一个端点检测到故障时,它会以down event告知另一方,这种情况下,另一端可以快速停止触发故障转移程序。这种例子,LS FSM 可以快速扩张来发送一个额外的信令消息并且在接收到这样一个数据包后强制触发一个down state。
B. Comparison with MPLS Fast Reroute
Fast Reroute (FRR)[8]是在MPLS网络中使用的一个技术,用于提供大约10s毫秒的标签交换路径(LSP)保护。类似于SPIDER,备份LSPs依据每一个预料的故障场景主动建立,当一个路由器在它的本地端口检测到故障时,它在MPLS栈顶与备份LSP 交换标签,在可供选择的端口中选择一个进行转发。。数据包在备份路径转发直到到达一个与主路径合并的节点,在这里,标签将swap(交换)回原来的主路径LSP。RSVP-TE信令用于分布模式下建立路由器之间的备份LSPs。
不同于FRR,SPIDER不需要一个分开的复杂信令协议(在FRR RFC 30页有描述)建立备份路径。相反,计算和提供主备路径主要通过远程控制器进行操作,因为远程控制器有SDN逻辑集中的优势。。这样的访问全局拓扑图以及集中API在交换机上提供转发规则。在提出的SPIDER实现原型中,MPS标签仅用于携带故障标签Fi,并且一定不要混淆在LSPs中的角色(在路由转发功能仅作为参数)。实际上,SPIDER转发功能时数据协议无关的,并且可以基于任意的首部区域。比如,正如我们的实现,每个数据包的输出端口是通过查找Ethernet source address,Ethernet destination addresss and failure tag组成的三元组进行决定的。
当在检测到故障的节点上无法找到路径,SPIDER可以在主路径上将数据包bounce back,直到一个之前定义的重路由节点,能够支持备份路径。。
C. Data plane reconciliation(数据平面协调)
带状态数据平面似乎不遵循SDN和OpenFlow的架构原则,所有的状态都是在逻辑集中的控制平面处理,因此,设备不需要实现复杂的软件解决状态distribution。事实上,当解决传统的分布式协议(比如 OSPF),一个重要的担忧是关于解决状态协调,比如在设备重置或者故障,这时的状态可能与其他设备的状态不一致,导致循环或者黑洞。
VIII CONCLUSION
本文提出SPIDER,一种在SDN中新的故障恢复方法,为应用开发者提供了关于重路由策略定义和故障检测机制的管理完全可编程概念。带状态数据平面的使用能够直接在交换机的fast-path执行程序故障恢复行为,最小化恢复延迟并且甚至在控制器不可达时保证故障转移。
SPIDER已经使用OpenState和P4进行实现,实现原型已经用于验证提出的方案并且在一些例子场景中实验性评估基本的性能。结果显示SPIDER对于集中应用的潜在优势,在这些应用程序中,控制器会收到故障事件通知,并且需要修改所有受影响的转发规则