虽然Python中的标准库urllib模块已经可以满足我们的大多数需求,但是它的API使用起来让人感觉不是很好,而requests宣传是
HTTP for Humans,说明使用更简洁方便。
1.安装和文档地址
- 安装
pip install requests
- 文档地址
中文文档:https://cn.python-requests.org/zh_CN/latest/
开源地址:https://github.com/kennethreitz/requests
2.发送get请求
2.1 发送最简单的get请求
import requests
resp = requests.get("https://www.sohu.com/")
print(resp.content.decode('utf-8'))
2.2 添加headers和查询参数
如果想要添加headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用params参数。
实例代码:
import requests
params = {
'q': 'Python'
}
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
# params接受一个字典或者字符串查询参数,字典类型自动转换为url编码
response = requests.get('https://www.so.com/s', params = params, headers = headers)
# 查看完整的url地址
print(response.url)
# 查看响应内容,response.text返回的是Unicode格式的数据
print(response.text)
# 查看响应内容,response.content返回的字节流数据
print(response.content.decode('utf-8'))
# 查看响应头的字符编码
print(response.encoding)
# 查看响应码
print(response.status_code)
response.text和response.content的区别
-
response.text
类型:str
解码类型: 根据HTTP头部对响应的编码作出有根据的推测,推测的文本编码
如何修改编码方式:response.encoding="GBK" -
response.content
类型:bytes
解码类型: 没有指定
如何修改编码方式:response.content.deocde("utf-8")
推荐使用response.content.deocde()的方式获取响应的html页面
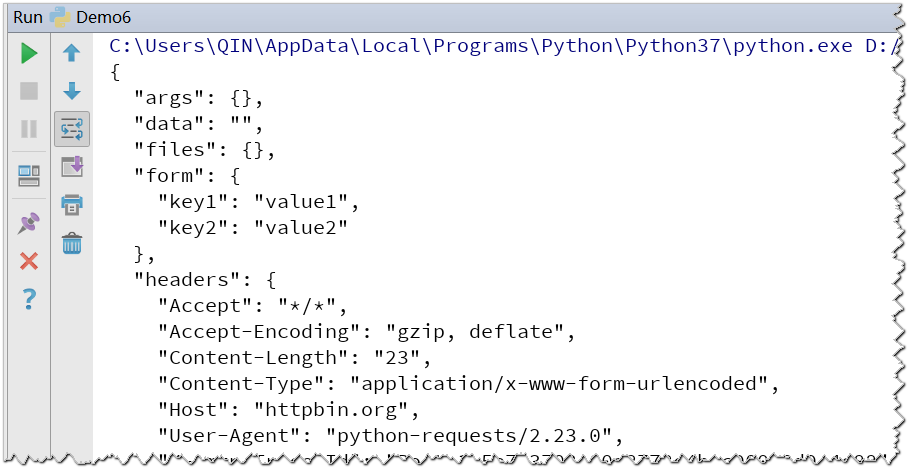
3.发送post请求
import requests
url = 'http://httpbin.org/post'
d = {'key1': 'value1', 'key2': 'value2'}
r = requests.post(url, data=d)
print(r.text)
输出结果:
4.设置代理
用法:requests.get("http://www.baidu.com", proxies = proxies)
proxies的形式:字典
proxies = {
"http": "http://12.34.56.79:9527",
"https": "https://12.34.56.79:9527",
}
实际案例:
import requests
proxies = {
"https": "https://117.114.149.66:53281"
}
response = requests.get('http://httpbin.org/ip', proxies = proxies )
print(response.text)
使用代理注意事项:
(1) 准备一堆的ip地址,组成ip池,随机选择一个ip来使用
(2) 如何随机选择代理ip,让使用次数较少的ip地址有更大的可能性被用到
{"":ip,"times":0}
[{},{},{},{},{},{}],对这个ip的列表进行排序,按照使用次数进行排序
选择使用次数较少的10个ip,从中随机选择一个
(3) 检查ip可用性
使用requests设置超时参数,判断ip地址的质量
在线代理ip质量检测的网站
5.爬虫的cookie和session
5.1 cookie和session的区别
-
cookie数据存放在客户的浏览器上,session数据放在服务器上。
-
cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗。
-
session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能。
-
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
利弊分析: -
带上cookie、session的好处:
能够请求到登录之后的页面 -
带上cookie、session的弊端:
一套cookie和session往往和一个用户对应
请求太快,请求次数太多,容易被服务器识别为爬虫
不需要cookie的时候尽量不去使用cookie
但是为了获取登录之后的页面,我们必须发送带有cookies的请求
5.2 处理cookies、session请求
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持
-
使用方法:
实例化一个session对象
让session发送get或者post请求session = requests.session()
response = session.get(url,headers)
5.3 实战演练:登录人人网
实现思路:
- 1.先实例化session
- 2.先使用session发送请求,登录到网站,把cookie保存到session中
- 3.再使用session请求登录之后才能访问的网站,session能够自动携带登录成功时保存在其中的cookie,进行请求。
5.3.1 第一种登录方法
# Author:Logan
import requests
# 实例化session
session = requests.session()
post_url = "http://www.renren.com/PLogin.do"
post_data = {"email":"1829xxxxxx", "password":"xxxxxx"}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
# 使用session发送post请求,将cookie保存在其中
session.post(post_url, data=post_data, headers=headers)
# 使用session进行请求登录之后才能访问的地址
r = session.get("http://www.renren.com/422522252", headers=headers)
# 保存抓取到的网页
with open("登录主页.html","w",encoding="utf-8") as f:
f.write(r.content.decode())
5.3.2 第二种方法:直接使用cookie
实现思路:
- cookie过期时间很长的网站
- 在cookie过期之前能够拿到所有的数据,比较麻烦、
- 配合其他程序一起使用,其他程序专门获取cookie,当前程序专门请求页面
# Author:Logan
import requests
# 实例化session
session = requests.session()
# cookie需要从浏览器的开发者工具中获取
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"Cookie": " depovince=GW; _r01_=1; JSESSIONID=abcSUGlZJI35n-eGRWaax; ick_login=14b370e8-ddda-4454-92bd-1ee4e7e43cff; taihe_bi_sdk_uid=e010145001347915db9751467f2cd0ea; taihe_bi_sdk_session=8d5708e58efbff67d0c898d0cfb65190; ick=a6cd9b11-1041-4369-9c2e-988a1145e2db; __utma=151146938.1477590665.1580561077.1580561077.1580561077.1; __utmc=151146938; __utmz=151146938.1580561077.1.1.utmcsr=renren.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmb=151146938.4.10.1580561077; first_login_flag=1; ln_uact=18298377941; ln_hurl=http://hdn.xnimg.cn/photos/hdn221/20130527/1710/h_main_kCBe_44640000035d111a.jpg; springskin=set; jebe_key=03183a84-908b-4464-a274-effbad2465bd%7C328749f653f1c822a5c17f3cffb81c7e%7C1580561163632%7C1%7C1580561167311; jebe_key=03183a84-908b-4464-a274-effbad2465bd%7C328749f653f1c822a5c17f3cffb81c7e%7C1580561163632%7C1%7C1580561167317; vip=1; wp=1; _ga=GA1.2.1477590665.1580561077; _gid=GA1.2.949337216.1580561260; wp_fold=0; jebecookies=232a41e5-1d06-4b42-997e-b882808e2f33|||||; _de=02B2EB92B8F71ACD92522705638FE3D8; p=95ac9bbe0e38f6f505d6b802289e32ae2; t=df3627f5cb62cc5c01424ea6f48bb1e42; societyguester=df3627f5cb62cc5c01424ea6f48bb1e42; id=422522252; xnsid=ff1c185f; ver=7.0; loginfrom=null"
}
# 使用session进行请求登录之后才能访问的地址
r = session.get("http://www.renren.com/422522252", headers=headers)
# 保存抓取到的网页
with open("登录主页2.html","w",encoding="utf-8") as f:
f.write(r.content.decode())
5.3.3 第三种方法:字典推导式、列表推导式实现
# Author:Logan
import requests
# 实例化session
session = requests.session()
cookie = " depovince=GW; _r01_=1; JSESSIONID=abcSUGlZJI35n-eGRWaax; ick_login=14b370e8-ddda-4454-92bd-1ee4e7e43cff; taihe_bi_sdk_uid=e010145001347915db9751467f2cd0ea; taihe_bi_sdk_session=8d5708e58efbff67d0c898d0cfb65190; ick=a6cd9b11-1041-4369-9c2e-988a1145e2db; __utma=151146938.1477590665.1580561077.1580561077.1580561077.1; __utmc=151146938; __utmz=151146938.1580561077.1.1.utmcsr=renren.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmb=151146938.4.10.1580561077; first_login_flag=1; ln_uact=18298377941; ln_hurl=http://hdn.xnimg.cn/photos/hdn221/20130527/1710/h_main_kCBe_44640000035d111a.jpg; springskin=set; jebe_key=03183a84-908b-4464-a274-effbad2465bd%7C328749f653f1c822a5c17f3cffb81c7e%7C1580561163632%7C1%7C1580561167311; jebe_key=03183a84-908b-4464-a274-effbad2465bd%7C328749f653f1c822a5c17f3cffb81c7e%7C1580561163632%7C1%7C1580561167317; vip=1; wp=1; _ga=GA1.2.1477590665.1580561077; _gid=GA1.2.949337216.1580561260; wp_fold=0; jebecookies=232a41e5-1d06-4b42-997e-b882808e2f33|||||; _de=02B2EB92B8F71ACD92522705638FE3D8; p=95ac9bbe0e38f6f505d6b802289e32ae2; t=df3627f5cb62cc5c01424ea6f48bb1e42; societyguester=df3627f5cb62cc5c01424ea6f48bb1e42; id=422522252; xnsid=ff1c185f; ver=7.0; loginfrom=null"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
cookies = {i.split("=")[0]:i.split("=")[1] for i in cookie.split(";")}
print(cookies)
# 使用session进行请求登录之后才能访问的地址
r = session.get("http://www.renren.com/422522252", headers=headers, cookies=cookies)
# 保存抓取到的网页
with open("登录主页3.html","w",encoding="utf-8") as f:
f.write(r.content.decode())