小萝卜机器人的例子:

就像这种机器人,它的下面有一组轮子,脑袋上有相机(眼睛),为了让它能够探索一个房间,它需要知道:
1.我在哪——定位
2.周围环境怎么样——建图
定位和建图可以理解成感知的 "内外之分",一方面要明白自身的状态(位置),另一方面要了解周围的环境(地图)。要完成这些工作,我们可以通过在房间铺设导引线,在墙上贴识别二维码,在室外可以给机器人安装定位设备,这些我们都称之为传感器,传感器分为两类:
1.携带于机器人本体上,例如相机,激光传感器等
2.安装于环境中的,例如导引线,识别二维码等。
然而大量利用这些外部传感器很明显是不现实的,抛开成本,光是在环境中铺设这些传感器就很不现实,有些地方不能铺设导轨,有些地方没有信号,相对地, 安装于机器人身上的传感器测到的都是一些间接的物理量,并不能得到直接的位置信息,我们只能通过一些间接的手段,推算出位置。虽然听起来很麻烦,但是它有一个很明显的好处就是对环境条件没有要求,适用于测量未知环境。
SLAM中非常强调未知环境,因此,谈论视觉SLAM时,主要指如何用相机解决定位和构图问题。SLAM中使用的相机是以一定速率拍摄周围的环境,形成一个连续的视频流。普通相机能以每秒钟30张的速度采集图像,按照工作方式不同,可以分为单目相机,双目相机和深度相机。
单目相机:顾名思义,只有一个摄像头,我们通常的照片就是单目摄像机拍摄的图像,以二维的形式反映了三维的世界。显然,这个过程丢掉了深度(距离),比如:

你很难分辨出手掌上的人是真人还是模型。
如果想恢复三维结构,我们必须改变相机的视角,因此必须移动相机,才能估计它的运动,同时估计场景中物体的远近和大小,不妨称之为结构,一方面,我们知道相机往右移动,图像里的东西会向左移动,另一方面,近处的物体移动快,远处的物体运动缓慢。于是,当相机移动时,这些物体在图像上的运动形成了视差。通过视差我们可以判断哪些物体离得远,哪些离得近。
现在我们知道了物体远近,但是它们仍然是相对的值,如果把相机的运动和场景大小同时放大两倍,单目相机看到的图像是一样的。因此,单目SLAM估计的轨迹和地图将与真实的轨迹和地图相差一个因子,也就是尺度。由于单目SLAM无法仅凭图像确定这个真实尺度,所以又称尺度不确定性。
平移之后才可以计算深度,以及无法确定真实尺度,这给单目SLAM的应用带来了很大麻烦。根本原因是通过单张图像无法确定深度。
双目相机:
由两个单目相机组成,这两个单目相机之间的距离(成为基线)是已知的。通过这个基线来估计每个像素的空间位置——和人眼类似。基线的距离越大,能测量到的就越远。双目相机的距离估计是比较左右眼的图像获得的,并不依赖其他传感设备。因此室内外都可以应用。它的缺点是配置与标定均比较复杂,其深度量程和精度受双目的基线与分辨率所限,而且视差的计算非常消耗计算资源,需要使用 GPU 和 FPGA 设备加速后,才能实时输出整张图像的距离信息,因此计算量是双目的主要问题之一。
深度相机:
又称 RGB-D 相机,最大的特点是可以通过红外结构光或 Time-of-Flight(TOF) 原理,像激光传感器那样,通过主动向物体发射光并接收返回的光,测出物体与相机之间的距离。
经典视觉SLAM框架:
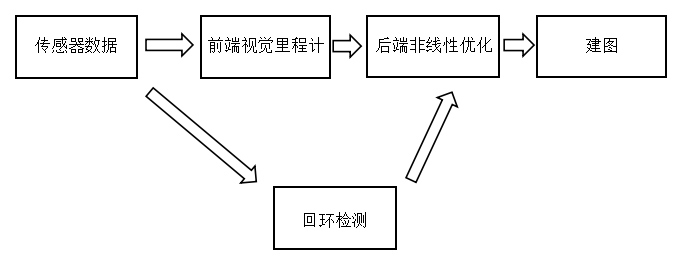
整个视觉SLAM流程包括以下步骤。
1.传感器信息读取。在视觉SLAM中主要为相机图像信息的读取和预处理。如果是在机器人中,还可能有码盘、惯性传感器等信息的读取和同步。
2.视觉里程计(Visual Odometry,VO)。视觉里程计的任务是估算相邻图像间相机的运动,以及局部地图的样子。VO又称为前端。
3.后端优化(Optimization)。后端接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息,对它们进行优化,得到全局一致的轨迹和地图,由于接在VO之后,又称后端。
4.回环检测(Loop Closing)。判断机器人是否到达过先前的位置。如果检测到回环,它会把信息提供给后端进行处理。
5.建图(Mapping)。根据估计的轨迹,建立与任务要求对应的地图。
关于SLAM问题的数学表述,在后续的博文中会提到。
小试牛刀:
1.安装Linux系统,这个不用多说。
2.编写helloSLAm.cpp。首先建一个文件夹。
$mkdir slambook
$cd slambook
$mkdir ch2
然后在ch2下写helloSLAM.cpp。
$cd ch2
$vim helloSLAM.cpp
将如下代码写入。
#include <iostream> using namespace std; int main(int argc,char** argv) { cout<<"Hello SLAM"<<endl; return 0; }
先使用g++编译。
$g++ helloSLAM.cpp
确保你的机器里有g++。如果没有,请使用以下命令安装。
$sudo apt-get install g++
编译成功后,输入:
$./a.out
即可运行。
我们可以发现,g++默认把源文件编译成 a.out 。
3.使用cmake
在刚才的目录下新建一个 CMakeLists.txt 文件,输入:
#声明要求的 cmake 最低版本 cmake_minimum_required( VERSION 2.8 ) #声明一个cmake工程 project( HelloSLAM ) #添加一个可执行程序 #语法:add_executable(程序名 源代码文件) add_executable( helloSLAM helloSLAM.cpp )
在当前目录下(slambook/ch2),调用 cmake 对该工程分析:
用 make 对工程进行编译:
$make
然后运行:
$./helloSLAM
cmake 和 g++都可以对C++文件进行编译,那么它们之间的区别是什么?
通常一个小型C++项目可能含有十几个类,各类之间还存在着复杂的依赖关系。其中一部分要编译成可执行文件,另一部分要编译成库文件。如果仅靠g++命令,需要输入大量的编译指令,整个编译过程会非常繁琐。因此对于C++项目,使用一些工程管理工具会更加高效。也就是cmake。
4.使用库
创建如下文件(slambook/ch2/libHelloSLAM.cpp):
#include <iostream> using namespace std; void printHello() { cout<<"Hello SLAM"<<endl; }
这个库提供了一个printHello()函数,调用此函数将打印出一条信息,但是没有main()函数,意味着这个库中没有可执行文件,我们在CMakeLists.txt里加上如下内容:
add_library( hello libHelloSLAM.cpp)
这条命令告诉cmake,我们想把这个文件编译成一个叫做“hello”的库,然后和上面一样,编译整个工程:
$cd build
$cmake ..
$make
这时,在build文件夹中就会生成一个libhello.a文件,这就是得到的库,
Linux中,库分为静态库和共享库,静态库以.a作为后缀名,共享库以.so结尾,所有库都是一些函数打包后的集合,差别在于静态库每次被调用都会生成一个副本,而共享库只有一个副本,更省空间。如果想生成共享库,那么只需要:
add_library( hello_shared SHARED libHelloSLAM.cpp)
此时得到的就是libhello_shared.so了。
为了让别人使用这个库,我们需要提供一个头文件,说明这些库里面都有些什么,因此,对于库的使用者,只要拿到了头文件和库文件,就可以调用这个库了,下面编写libhello的头文件。
slambook/ch2/libHelloSLAM.h
#ifndef LIBHELLOSLAM_H_ #define LIBHELLOSLAM_H_ void printHello(); #endif
根据这个文件和我们刚才编译得到的库文件,就可以使用printHello()函数了,下面写一个可执行程序来调用这个简单的函数:
slambook/ch2/useHello.cpp
#include "libHelloSLAM.h" int main(int argc,char** argv) { printHello(); return 0; }
然后,在CMakeLists.txt中添加一个可执行程序的生成命令,链接到刚才使用的库上:
add_executable( useHello useHello.cpp )
target_link_libraries( useHello hello_shared)
5.使用IDE
关于kdevelop的安装教程请看:
http://blog.csdn.net/p942005405/article/details/75715288