day41
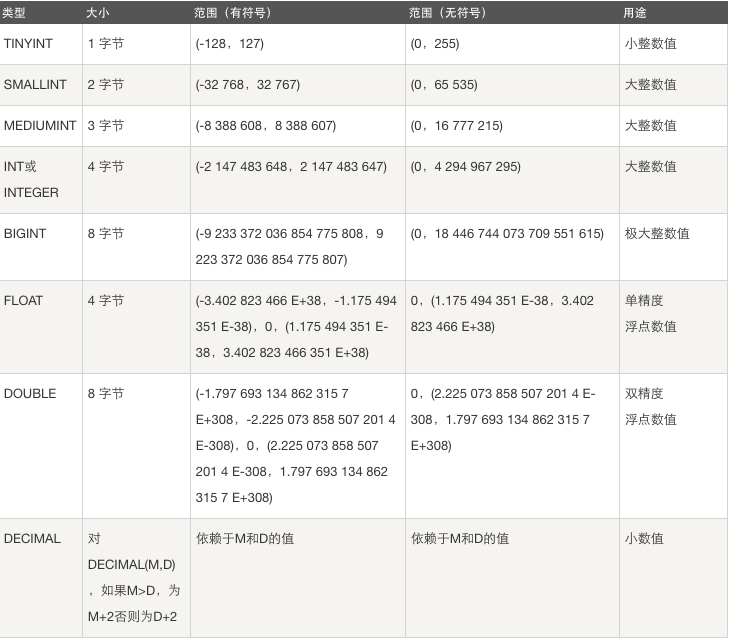
数值类型
整数类型
有符号的设置
mysql> create table t1(id tinyint); # 默认有符号,即数字前有正负号
无符号的设置
mysql> create table t1(id tinyint unsigned);
zerofill用法
如果宽度小于设定的宽度(这里宽度为4),则自动填充0,需要注意的是,这只是最后显示的结果,在MySQL中实际存储的还是1
用zerofill测试整数类型的显示宽度
mysql> create table t7(x int(3) zerofill);
mysql> insert into t7 values
-> (1),
-> (11),
-> (111),
-> (1111);
mysql> select * from t7;
+------+
| x |
+------+
| 001 |
| 011 |
| 111 |
| 1111 | #超过宽度限制仍然可以存
+------+
注意:对于整型来说,数据类型后面的宽度并不是存储长度限制,而是显示限制,假如:int(8),那么显示时不够8位则用0来填充,够8位则正常显示,通过zerofill来测试,存储长度还是int的4个字节长度。默认的显示宽度就是能够存储的最大的数据的长度,比如:int无符号类型,那么默认的显示宽度就是int(10),有符号的就是int(11),因为多了一个符号,所以我们没有必要指定整数类型的数据,没必要指定宽度,因为默认的就能够将你存的原始数据完全显示
int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok
MySQL的mode
查sql_mode
select @@sql_mode
select @@global.sql_mode
sql_mode 常用来解决下面这几类问题
- 通过设置sql mode, 可以完成不同严格程度的数据校验,有效地保障数据准备性。
- 通过设置sql model 为宽松模式,来保证大多数sql符合标准的sql语法,这样应用在不同数据库之间进行迁移时,则不需要对业务sql 进行较大的修改。
- 在不同数据库之间进行数据迁移之前,通过设置SQL Mode 可以使MySQL 上的数据更方便地迁移到目标数据库中。
sql_mode常用值如下
简单介绍详情:https://www.cnblogs.com/clschao/articles/9962347.html
NO_ENGINE_SUBSTITUTION
宽松版——如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常
STRICT_TRANS_TABLES
严格版——在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做限制
NO_ZERO_IN_DATE:
在严格模式下,不允许日期和月份为零
注意:MySQL5.6和MySQL5.7默认的sql_mode模式参数是不一样的
- 5.6的是NO_ENGINE_SUBSTITUTION,其实表示的是一个空值,相当于没有什么模式设置,可以理解为宽松模式
- 5.7的mode是STRICT_TRANS_TABLES,也就是严格模式。
如果设置的是宽松模式,那么我们在插入数据的时候,即便是给了一个错误的数据,也可能会被接受,并且不报错,例如:我在创建一个表时,该表中有一个字段为name,给name设置的字段类型时char(10),如果我在插入数据的时候,其中name这个字段对应的有一条数据的长度超过了10,例如'1234567890abc',超过了设定的字段长度10,那么不会报错,并且取前十个字符存上,也就是说你这个数据被存为了'1234567890',而'abc'就没有了,但是我们知道,我们给的这条数据是错误的,因为超过了字段长度,但是并没有报错,并且mysql自行处理并接受了,这就是宽松模式的效果,其实在开发、测试、生产等环境中,我们应该采用的是严格模式,出现这种错误,应该报错才对,所以MySQL5.7版本就将sql_mode默认值改为了严格模式,并且我们即便是用的MySQL5.6,也应该自行将其改为严格模式,而你记着,MySQL等等的这些数据库,都是想把关于数据的所有操作都自己包揽下来,包括数据的校验,其实好多时候,我们应该在自己开发的项目程序级别将这些校验给做了,虽然写项目的时候麻烦了一些步骤,但是这样做之后,我们在进行数据库迁移或者在项目的迁移时,就会方便很多,这个看你们自行来衡量。mysql除了数据校验之外,你慢慢的学习过程中会发现,它能够做的事情还有很多很多,将你程序中做的好多事情都包揽了。
改为严格模式后可能会存在的问题
若设置模式中包含了NO_ZERO_DATE,那么MySQL数据库不允许插入零日期,插入零日期会抛出错误而不是警告。例如表中含字段TIMESTAMP列(如果未声明为NULL或显示DEFAULT子句)将自动分配DEFAULT '0000-00-00 00:00:00'(零时间戳),也或者是本测试的表day列默认允许插入零日期 '0000-00-00' COMMENT '日期';这些显然是不满足sql_mode中的NO_ZERO_DATE而报错。
模式设置和修改方法
-
方法一
先执行select @@sql_mode,复制查询出来的值并将其中的NO_ZERO_IN_DATE,NO_ZERO_DATE删除,然后执行set sql_mode = '修改后的值'或者set session sql_mode='修改后的值';,例如:set session sql_mode='STRICT_TRANS_TABLES';改为严格模式 此方法只在当前会话中生效,关闭当前会话就不生效了。 -
方法二
先执行select @@global.sql_mode,复制查询出来的值并将其中的NO_ZERO_IN_DATE,NO_ZERO_DATE删除,然后执行set global sql_mode = '修改后的值'。 此方法在当前服务中生效,重新启动MySQL服务后失效 -
方法三
在mysql的安装目录下,或my.cnf文件(windows系统是my.ini文件),新增 sql_mode = ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION, 添加my.cnf如下: [mysqld] sql_mode=ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER 然后重启mysql。 此方法永久生效.当然生产环境上是禁止重启MySQL服务的,所以采用方式二加方式三来解决线上的问题,那么即便是有一天真的重启了MySQL服务,也会永久生效了。
浮点型
注意:float只能精准8位,从整数开始从左往右
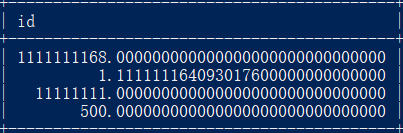
测试
mysql> create table t3(id float(60,30));
Query OK, 0 rows affected (1.70 sec)
mysql> create table t4(id double(60,30));
Query OK, 0 rows affected (0.88 sec)
mysql> create table t5(id decimal(60,30));
Query OK, 0 rows affected (0.96 sec)
mysql> insert into t3 values(1.1111111111111111111111);
Query OK, 1 row affected (0.13 sec)
mysql> insert into t4 values(1.1111111111111111111111);
Query OK, 1 row affected (0.22 sec)
mysql> insert into t5 values(1.1111111111111111111111);
Query OK, 1 row affected (0.09 sec)
mysql> select * from t3;
mysql> select * from t4;
mysql> select * from t5;
位类型
可以存储二进制数或者十六进制数
详情请看:https://www.cnblogs.com/clschao/articles/9959559.html
日期类型
- year
YYYY(范围:1901~2155) ——2018
- date
YYYY-MM-DD (范围:1000-01-01~9999-12-31) ——2018-01-01
- time
HH:MM:SS ——12:09:32
- datetime
YYYY-MM-DD HH:MM:SS(范围:1000-01-01 00:00:00~9999-12-31 23:59:59 )——2018-01-01 12:09:32
测试
mysql> create table t6(d1 year ,d2 date,d3 datetime);
Query OK, 0 rows affected (1.75 sec)
mysql> insert into t6 values(now(),now(),now());
Query OK, 1 row affected, 1 warning (0.12 sec)
mysql> select * from t6;
字符串类型
详情:https://www.cnblogs.com/clschao/articles/9959559.html
针对char类型,mysql在存储的时候会将不足规定长度的数据使用后面(右边补全)补充空格的形式进行补全,然后存放到硬盘中,但是在读取或者使用的时候会自动去掉它给你补全的空格内容,因为这些空格并不是我们自己存储的数据,所以对我们使用者来说是无用的。
char和varchar性能对比
以char(5)和varchar(5)来比较,加入我要存三个人名:sb,ssb1,ssbb2
char:
优点:简单粗暴,不管你是多长的数据,我就按照规定的长度来存,5个5个的存,三个人名就会类似这种存储:sb ssb1 ssbb2,中间是空格补全,取数据的时候5个5个的取,简单粗暴速度快
缺点:貌似浪费空间,并且我们将来存储的数据的长度可能会参差不齐
varchar:
varchar类型不定长存储数据,更为精简和节省空间
例如存上面三个人名的时候类似于是这样的:sbssb1ssbb2,连着的,如果这样存,请问这三个人名你还怎么取出来,你知道取多长能取出第一个吗?(超哥,我能看出来啊,那我只想说:滚犊子!)
不知道从哪开始从哪结束,遇到这样的问题,你会想到怎么解决呢?还记的吗?想想?socket?tcp?struct?把数据长度作为消息头。
所以,varchar在存数据的时候,会在每个数据前面加上一个头,这个头是1-2个bytes的数据,这个数据指的是后面跟着的这个数据的长度,1bytes能表示2**8=256,两个bytes表示2**16=65536,能表示0-65535的数字,所以varchar在存储的时候是这样的:1bytes+sb+1bytes+ssb1+1bytes+ssbb2,所以存的时候会比较麻烦,导致效率比char慢,取的时候也慢,先拿长度,再取数据。
优点:节省了一些硬盘空间,一个acsii码的字符用一个bytes长度就能表示,但是也并不一定比char省,看一下官网给出的一个表格对比数据,当你存的数据正好是你规定的字段长度的时候,varchar反而占用的空间比char要多。
Value CHAR(4) Storage Required VARCHAR(4) Storage Required
'' ' ' 4 bytes '' 1 byte
'ab' 'ab ' 4 bytes 'ab' 3 bytes
'abcd' 'abcd' 4 bytes 'abcd' 5 bytes
'abcdefgh' 'abcd' 4 bytes 'abcd' 5 bytes
缺点:存取速度都慢
总结:
所以需要根据业务需求来选择用哪种类型来存
其实在多数的用户量少的工作场景中char和varchar效率差别不是很大,最起码给用户的感知不是很大,并且其实软件级别的慢远比不上硬件级别的慢,所以你们公司的运维发现项目慢的时候会加内存、换nb的硬盘,项目的效率提升的会很多,但是我们作为专业人士,我们应该提出来这样的技术点来提高效率。
但是对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列性能要好。因而,主要的性能因素是数据行使用的存储总量。由于CHAR平均占用的空间多于VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。
所以啊,两个选哪个都可以,如果是大型并发项目,追求高性能的时候,需要结合你们服务器的硬件环境来进行测试,看一下char和varchar哪个更好,这也能算一个优化的点吧~~~~
枚举类型与集合类型
测试:
枚举类型(enum)
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small');
集合类型(set) 不能为数字,可以变为字符串
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
完整性约束
详情请看:https://www.cnblogs.com/clschao/articles/9968396.html
not null 不为空
create table t1(name char(10) not null);
default 默认值
create table t1(name char(10) not null default 'xx');
unique 唯一,字段数据不能重复
create table t1(name char(10) unique);
primary key 主键,约束效果:不为空且唯一
create table t1(id int primary key);
auto_increment 自增
create table t1(id int primary key auto_increment); 前面必须是个key
foreign key 外键,建立表关系使用的约束条件
- 多对一(一对多)
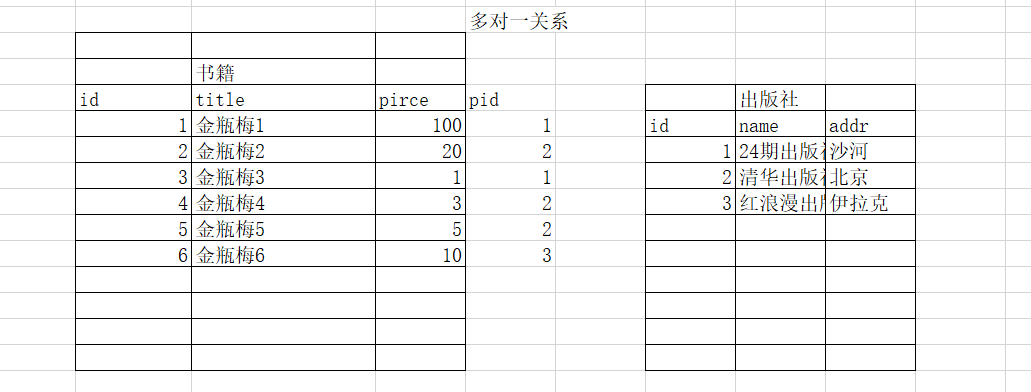
在多的表里面添加一个字段,并给这个字段加foreign key,比如:
出版社对于书籍是多对一的关系
1、先创建出版社表 publish表
2、创建书籍表,外键写法:
create table book(
id int primary key,
name char(10),
pid int,
foreign key(pid) references publish(id)
);
3、先给出版社插入数据
- 一对一关系

学生表(student)和客户表(customer)
在数据少的表添加字段,如果一样多随便哪个表都行
create table student(
id int primary key,
name char(10),
cid int unique,
foreign key(cid) references customer(id)
);
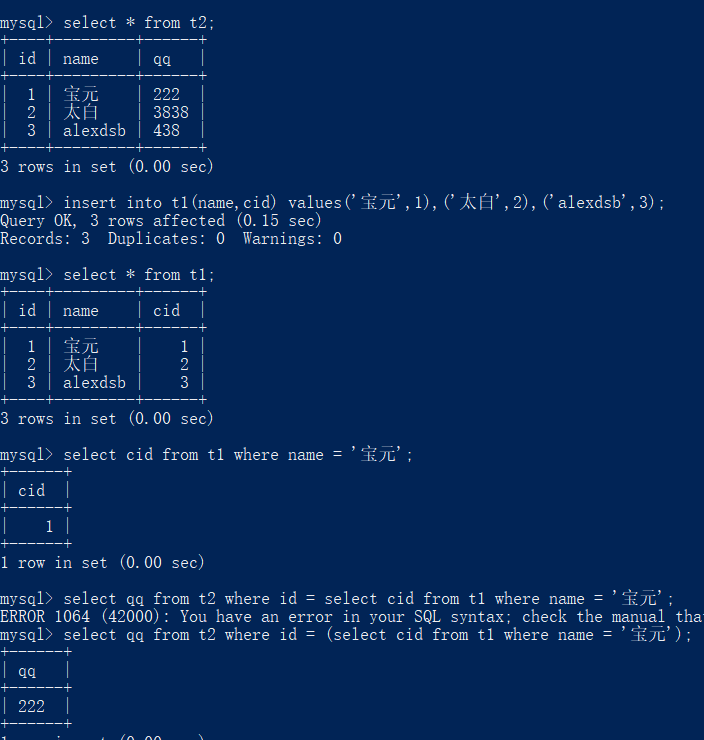
在学生表获取到qq
- 多对多关系

作者表和书籍表
需要借助第三张表来完整两者的关系记录
第三张表最后创建
create table authortobook(
id int primary key,
aurhor_id int,
book_id int,
foreign key(author_id) references author1(id),
foreign key(book_id) references book1(id)
)
查找代码:
