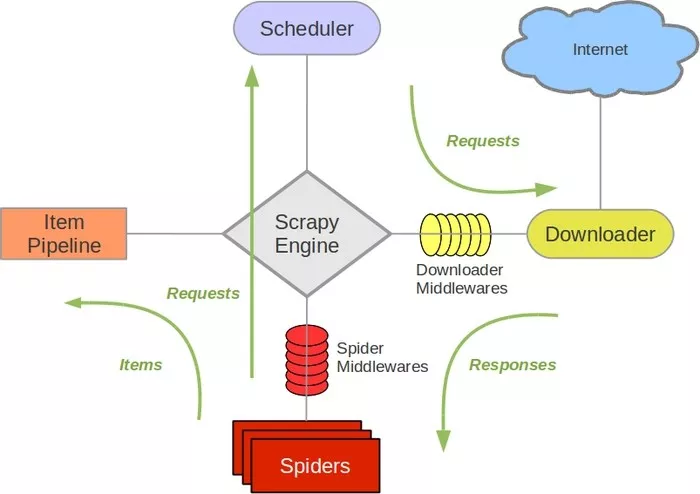
- Downloader Middleware:下载中间件,它处于Scrapy的Request和Response之间的处理模块
- 在Schedule调度出队列中的Request发送给Downloader下载之前,对Request进行修改
- 在下载后生成的Response发送给Spider之前,可以对其进行解析
- Scrapy内置提供的下载中间件
- DOWNLOADER_MIDDLEWARES_BASE:是框架提供的,禁止修改
- DOWNLOADER_MIDDLEWARES:可以添加自定义下载中间件可以在中进行修改
1 # 字典格式数据,数值越小越优先被调用 2 DOWNLOADER_MIDDLEWARES_BASE 3 { 4 'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100, 5 'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300, 6 'scrapy.contrib.downloadermiddleware.downloadtimeout.DownloadTimeoutMiddleware': 350, 7 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400, 8 'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500, 9 'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550, 10 'scrapy.contrib.downloadermiddleware.redirect.MetaRefreshMiddleware': 580, 11 'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 590, 12 'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600, 13 'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700, 14 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750, 15 'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830, 16 'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850, 17 'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900, 18 }
- Downloader Middleware的核心方法
- process_request(self, request, spider):该方法在Request被Scrapy引擎调度给Downloader之前调用,对request进行处理
- request:Request对象,即将被处理的Request
- spider:Spider对象,该Request所对应的Spider
- 返回值为None:更低优先级的Downloader的process_request()方法将会继续被调用对Request进行修改,直到返回Response为止
- 返回值为Response对象:更低优先级的Downloader的process_request()方法和process_exception()将不会被继续调用,每个Downloader的process_response()方法转而依次被调用,调用结束后,直接将Response对象发送给Spider处理
- 返回值为Request对象:更低优先级的Downloader的process_request()会停止执行,而这个Request会被重新放入调度队列,等待新一轮的调用
- IgnoreRequest异常抛出:所有Downloader的process_exception()方法会被依次调用,如果没有方法处理该异常,则Request的errorback()方法就会回调
- process_response(self, request, response, spider):在Scrapy引擎将得到的Response发生到Spider进行解析之前,调用process_response()进行处理
- request:Request对象,即该Response对应的Request
- response:Response对象,即将被处理的Response
- spider:Spider对象,该Response所对应的Spider
- 返回Request对象:更低优先级的Downloader的process_response()方法不会继续被调用,该Request对象会被重新放在调度队列中等待被调用
- 返回Response对象:更低优先级的Downloader的process_response()方法会被继续调用,继续对该Response对象进行处理
- IgnoreRequest异常抛出:Request的errorback()方法会回调,如果该异常没有被处理,那么它便会被忽略
- process_exception(self, request, exception, spider):当Downloader抛出异常时被调用
- request:Request对象,即产生异常的Request
- exception:Exception对象,即抛出的异常
- spider:Spider对象,该Request对应的Spider
- 返回值为None:更低优先级的Downloader的process_exception()会被继续依次调用,直到所有的方法都被调度完毕
- 返回Response对象:更低优先级的Downloader的process_exception()不会再被调用,每个Downloader的process_response()方法会被依次调用
- 返回Request对象:更低优先级的Downloader的process_exception()不会再被调用,该Request对象会被放在调度队列中等待被process_request()方法调用
- 新建scrapy项目
1 # 命令行操作 2 scrapy startproject Scrapy_DL # 新建项目Scrapy_DL 3 scrapy genspider httpbin httpbin.org # 进入项目,新建一个爬虫httpbin 4 scrapy crawl httpbin # 运行该爬虫
- 新建httpbin.py爬虫的编写
1 # httpbin.py 2 import scrapy 3 class HttpbinSpider(scrapy.Spider): 4 name = 'httpbin' 5 allowed_domains = ['httpbin.org'] 6 start_urls = ['http://httpbin.org/'] 7 8 def parse(self, response): 9 self.logger.debug(response.text) 10 self.logger.debug('Status Code:' + str(response.status))
- 自定义Downloader Middleware中间件的编写
1 # middlewares.py 2 # -*- coding: utf-8 -*- 3 import random 4 class RandomUserAgentMiddleware(): 5 "自定义的随机UserAgent中间件" 6 def __init__(self): 7 self.user_agents = [ 8 'Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)', 9 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2', 10 'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1' 11 ] 12 13 def process_request(self, request, spider): 14 request.headers['User-Agent'] = random.choice(self.user_agents) 15 16 def process_response(self, request, response, spider): 17 response.status = 201 18 return response
- 配置文件对自定义Downloader Middleware进行配置
1 # settings.py 2 DOWNLOADER_MIDDLEWARES = { 3 'Scrapy_DL.middlewares.RandomUserAgentMiddleware': 543, 4 }