为什么要使用数据库:
- 文件保存程序状态简单、易用,但只能保存一些格式简单、数据量不太大的数据。
- 对于有复杂关系的数据,推荐使用数据库进行保存。
- Python 为操作不同的数据库提供了不同的模块,这是Python的魅力所在。
- Python虽然为不同的数据提供了同的模块,这些模块的API设计大同小异,只要掌握一个数据库模块,对于其他数据库模块上手就容易。
- 本节主要掌握Python操作SQLite内置数据库和开源的MySQL数据库。
- Python 3.6 默认内置了操作 SQLite 数据库的模块。操作MySQL数据库的模块需要单独下载。
- 这里不详细学习SQL的DDL、DML、查询语句的语法。
一、Python 数据库 API 介绍
为Python提供的操作不同数据库的模块基本都遵守 Python 制订的 DP API 协议,目前该协议版本是2.0。因此这些数据库模块有些操作是相同的。下面先来了解这些模块的通用内容。
1、全局变量
支持DB API 2.0 的数据库模块都应该提供如下3个全局变量。
- apilevel:显示数据库模块的 API 版本号。对于支持 DB API 2.0版本的数据库模块,该变量值通常是2.0。如果这变量不存在,则该模块可能不支持DB API 2.0。
- threadsafety:指定数据库的线程安全等级,值为 0~3,其中3代表该模块完全是线程安全的;1 表示该模块具有部分线程安全性,线程可以共享该模块,但不能共享连接;0 表示线程完全不能共享该模块。
- paramstyle:指定当 SQL 语句需要参数时,可以使用哪种风格的参数。该变量值有下面几个:
- format:表示在SQL语句中使用Python标准的格式化字符串代表参数。例如使用 %s 参数;
- pyformat:表示在SQL语句中使用扩展的格式代码代表参数。比如使用 %(name),这样即可使用包含key为name的字典为该参数指定参数值。
- qmark:表示在SQL语句中使用问号(?)代表参数。在SQL语句中有几个参数,全用问号代替。
- numeric:表示在SQL语句中使用数字点位符(:N)代表参数。例如 :1 代表一个参数,:2 也表示一个参数,这些数字相当于参数名,因此它们不一定需要连续。
- named:表示在 SQL 语句中使用命名点位符(:name) 代表参数。例如 :name 代表一个参数,:age 也代表一个参数。
2、数据库 API 的核心类
遵守 DB API 2.0 协议的数据库模块通常会提供一个 connect() 函数,该函数用于连接数据库,并返回数据库连接对象。这个对象通常会具有如下方法和属性。
-
cursor(factory=Cursor):打开游标。返回游标对象,游标对象是 Python DB API 的核心对象,主要用于执行这种SQL语句,包括DDL、DML、select查询语句等。执行不同的SQL语句返回不同的数据。
-
commit():提交事务。
-
rollback():回滚事务。
-
close():关闭数据库连接。
-
isolation_level:返回或设置数据库连接中事务的隔离级别。
-
in_transaction:判断当前是否处于事务中。
游标对象(cursor)具有的方法和属性有:
- execute(sql[, parameters]):执行SQL语句。parameters 参数用于为SQL语句中的参数指定值。
- executemany(sql, seq_of_parameters):重复执行SQL语句。可以通过 seq_of_parameters 序列为SQL语句中的参数指定值,该序列有多少个元素,SQL语句被执行多少次。
- executescript(sql_script):这不是 DB API 2.0 的标准方法。该方法可以直接执行包含多条SQL语句的SQL脚本。
- fetchone():获取查询结果集的下一行。如果没有下一行,则返回 None。
- fetchmany(size=cursor.arraysize):返回查询结果集的下 N 行组成的列表。如果没有更多的数据行,则返回空列表。
- fetchall():返回查询结果集的全部行组成的列表。
- close():关闭游标。
- rowcount:该只读属性返回受SQL语句影响的行数。对于 executemany() 方法,该方法所修改的记录条数也可通过该属性获取。
- lastrowid:该只读属性可获取最后修改行的 rowid。
- arraysize:用于设置或获取 fetchmany() 默认获取的记录条数,该属性默认为 1。有些数据库模块没有该属性。
- description:该只读属性可获取最后一次查询返回的所有列的信息。
- connection:该只读属性返回创建游标的数据库连接对象,有些数据库模块没有该属性。
从上介绍可知,Python的DP API 2.0 由一个 connect() 开始,一共涉及数据库连接和游标两个核心API。它们的分工如下:
- 数据库连接:用于获取游标、控制事务。
- 游标:执行各种SQL语句。
3、操作数据库的基本流程
归纳出 Python DB API 2.0 的编程步骤(基本流程)是:
- 调用 connect() 方法打开数据库连接,该方法返回数据库连接对象。
- 通过数据库连接对象打开游标。
- 使用游标执行SQL语句(包括DDL、DML、select查询语句等)。如果执行的是查询语句,则处理查询数据。
- 关闭游标。
- 关闭数据库连接。
使用Python DP API 2.0 操作数据库的基本流程如下图1所示:
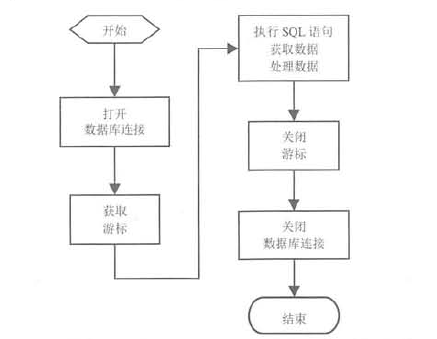
图1 使用Python DP API 2.0 操作数据库基本流程
二、操作 SQLite 数据库
- Python自带的 SQLite数据库核心文件在,安装目录下的 DLLs 子目录中的 sqlite3.dll 文件。
- SQLite 数据库的 API 模块在,安装目录下的 Lib 目录下的 sqlite3 子目录。
- SQLite 是一个嵌入式的数据库引擎,专门适用于在资源有限的设备上(如手机、PDA等)进行适量数据的存取。
- SQLite 支持大部分 SQL 92 语法,允许使用 SQL 语句操作数据库的数据。但是 SQLite 不需要安装、启动服务器进程,SQLite 数据库只是一个文件,它不需要服务器进程。
- 创建或打开一个SQLite 数据库时,其实只是打开一个文件准备读写。SQLite 有点像 Microsoft 的 Access,但 SQLite 的实际功能要强大得多。
下面先检查SQLite 模块的全局属性,以及是否遵守 DB API 2.0 规范,以及该模块使用的参数形式。
>>> import sqlite3
>>> sqlite3.apilevel
'2.0'
>>> sqlite3.paramstyle
'qmark'
从输出可知,该模块遵守 DB API 2.0规范,且使用问号(?)作为参数。
1、创建数据表
连接数据库得到游标后,就可以用游标来执行DDL语句,DDL语句负责创建表、修改表或删除表。使用 connect() 方法打开或创建一个数据库的方法是:
conn = sqlite3.connect('myfirst.db')
上面这行代码可用于打开或创建一个 SQLite 数据库。如果 myfirst.db 文件(该文件就是一个数据库)存在,那就打开该数据库;如果不存在,则在当前目录下创建相应的数据库文件。
将数据库名称 myfirst.db 改为特殊名称 :memory: 可以创建内存中的数据库。下面代码示例创建数据表。
import sqlite3
# 第1步:打开或创建数据库
# 也可使用特殊名称 :memory: ,代表创建内存中的数据库
conn = sqlite3.connect('myfirst.db')
# 第2步:获取游标
c = conn.cursor()
# 第3步:执行DDL语句创建数据表
c.execute('''create table user_tb(_id integer primary key autoincrement,
name text,
pass text,
gender text)''')
# 执行DDL语句创建数据表
c.execute('''create table order_tb(
_id integer primary key autoincrement,
item_name text,
item_price real,
item_number real,
user_id inteter,
foreign key(user_id) references user_tb(_id))''')
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
上面代码的第1步到第5步清晰地标出了使用 Python DB API 2.0 执行数据库访问的步骤。其中第3步执行了两次,每次分别执行一条 create 语句,因此该程序执行完成后,将会看到当前数据库中包含两个数据表: user_tb 和 order_tb,且在 order_tb 表中有一个外键列引用 user_tb 表的 _id 主键列。
第3步中使用 execute() 方法执行的就是标准的DDL语句,只要有SQL语法基础,就可使用 Python DB API 模块来执行这些SQL语句。
要注意的是,SQLite 内部只支持 NULL、INTEGER、REAL(浮点数)、TEXT(文本)和BLOB(大二进制对象)这5种数据类型,但实际上 SQLite 完全可以接受 varchar(n)、char(n)、decimal(p, s) 等数据类型,只不过SQLite 会在运算或保存时将它们转换为前面的5种数据类型中相应的类型。
此外,SQLite的另一个特点是,它允许把各种类型的数据保存到任何类型的字段中,开发中可以不用关心声明该字段所使用的数据类型。例如,可以把字符串类型的值存入 INTEGER 类型的字段中,也可以把数值类型的值存入布尔类型的字段中......,但是有一种特殊情况例外,就是被定义为“INTEGER PRIMARY KEY”的字段只能存储64位整数,当使用这种字段保存除整数以外的其他类型的数据时,SQLite会产生错误。
所以,在编写创建数据表的语句时可以省略数据列前面的类型声明。对于SQLite数据库如下SQL语句也是正确的。
create table my_test (
_id integer primary key autoincrement,
name ,
pass ,
gender
);
2、使用 SQLite Expert 工具
前面创建的 myfirst.db 数据库文件中创建了两个数据表,这两个数据表可通过 SQLite Expert 工具进行查看和管理。要使用该工具,需要先下载安装。
下载地址:http://www.sqliteexpert.com/download.html
该工具有免费的个人版和收费的商业版,可下载免费的个版进行安装。安装该工具与安装普通的 windows 软件是一样的。
第1次启动SQLite Expert 工具,可以看到如下图2所示的程序界面。

图2 SQLite Expert 程序界面
在图2所示的界面的左上角点击红框处,可以看3个工具按钮,作用依次是:创建数据库、创建内存中的数据库、打开数据库。
现在用该工具来打开前面创建的 myfirst.db 数据库文件,找到数据库文件的路径进行打开。打开数据库后可以在 SQLite Expert 工具中看到该数据库包含两个数据表。选中一个数据表,就可以在右边看到该数据表的详细信息,包括数据列(Columns)、主键(Primary Key)、索引(Indexs)、外键(Foreign Keys)、唯一约束(Unique Constraints)等。如下图3所示。
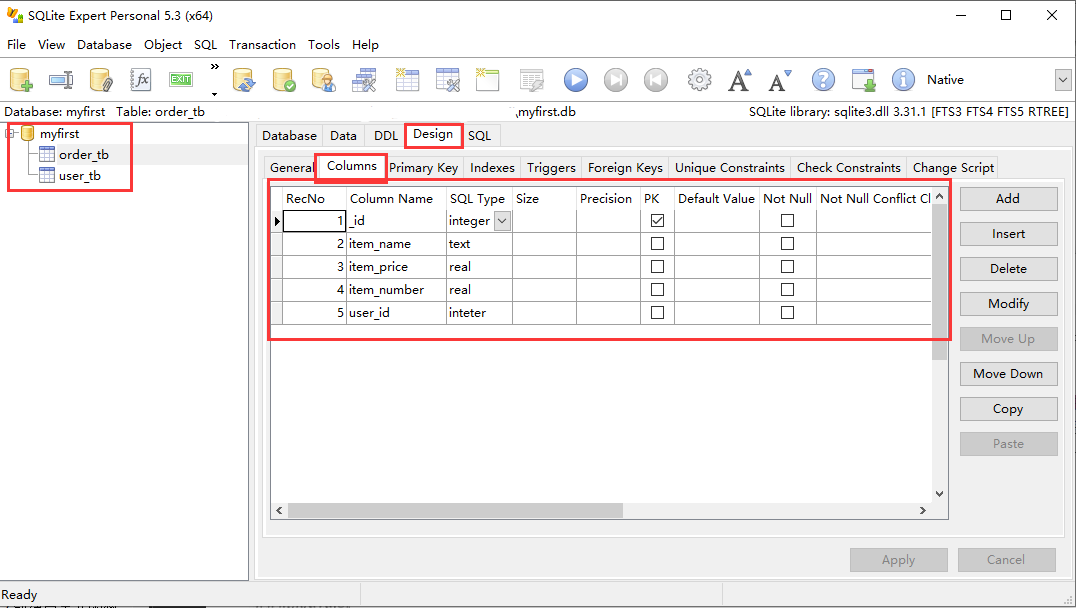
图3 查看数据表设计
如图3的界面所示,这就是一个非常方便的数据库管理界面,可能通过该界面执行创建数据表、删除数据表、添加数据、删除数据等操作。
3、使用序列重复执行DML语句
前面使用游标的 execute() 方法执行DML的 create 语句,除此之外,还可以执行 DML 的 insert、update、delete 语句,这样即可对数据库执行插入、修改、删除操作。下面代码向数据库的两个数据表分别插入一条数据。
import sqlite3
# 第1步:打开或创建数据库,使用名称 :memory: 表示创建内存中的数据库
conn = sqlite3.connect('myfirst.db')
# 第2步:获取游标
c = conn.cursor()
# 第3步:执行 insert 语句插入数据
c.execute('insert into user_tb values(null, ?, ?, ?)',
('范成大[宋]', '123456', 'male'))
c.execute('insert into order_tb values(null, ?, ?, ?, ?)',
('apple', '5.5', '8', 1))
# 提交事务
conn.commit()
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
由于 Python 的 SQLite 数据库 API 默认是开启了事务的,因此必须执行 conn.commit() 来提交事务;否则,在程序中对数据库所做的修改(插入、修改、删除)不会生效。运行上面代码后,就可在 SQLite Expert 工具中看到插入的数据。
如果使用 executemany() 方法,可以多次执行同一条 SQL 语句。示例如下:
import sqlite3
# 第1步:打开或创建数据库
conn = sqlite3.connect('myfirst.db')
# 第2步:获取游标
c = conn.cursor()
# 第3步:调用 executemany() 方法 多次执行同一条 SQL 语句
c.executemany('insert into user_tb values(null, ?, ?, ?)',
(('李白', '123456', 'male'),
('杜甫', '123456', 'male'),
('孟浩然', '123456', 'male'),
('武则天', 'abcdef', 'female'),
('陆游', '123456', 'male')))
# 提交事务
conn.commit()
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
上面代码调用 executemany() 方法执行一条 insert 语句,该方法的第二个参数是一个元组,该元组的每个元素都代表执行该 insert 语句一次,在执行 insert 语句时这些元素负责为该语句中的 “?” 占位符赋值。运行上面的代码,就会向 user_tb 数据表中插入 5 条数据。此时在 SQLite Expert 工具中可以看插入的数据。
还可使用 executemany() 方法重复执行 update语句或delete语句,只要第二个参数是一个序列,序列的每个元素都可对被执行SQL语句的参数赋值即可。下面代码示例了重复执行 update 语句。
import sqlite3
conn = sqlite3.connect('myfirst.db')
c = conn.cursor()
c.executemany('update user_tb set pass=? where _id=?',
(('abc123', 2),
('abc123', 3),
('123abc', 4),
('xyz321', 5),
('klmn', 6)))
# 通过 rowcount 获取被修改的记录条数
print('修改的记录条数:', c.rowcount) # 5
conn.commit()
c.close()
conn.close()
上面这段代码中,executemany() 方法执行的是update 语句,第二个参数仍然是一个元组,元组中每个元素包含两个子元素,用于为 update 语句中两个 “?” 占位符赋值。
上面的代码中还使用了游标的 rowcount 属性来获取 update 语句所修改的记录条数。运行这上面这段代码,可以看到表中 _id 字段值为 2~6 的记录 pass 都被修改。
4、执行查询 select语句
- 执行 select 查询语句的步骤与前面是一样的。select 语句执行完成后可以得到查询结果。
- 可通过游标的 fetchone()、fetchmany(n)、fetchall() 来获取查询结果。
- fetchone() 获取一条查询记录,fetchmany(n) 获取 n 条查询记录,fetchall() 获取全部查询记录。
import sqlite3
conn = sqlite3.connect('myfirst.db')
c = conn.cursor()
c.execute('select * from user_tb where _id > ?', (2,))
print('查询结果的记录数:', c.rowcount)
# 通过游标的 description 属性获取列信息
for col in c.description:
print(col[0], end = ' ')
print('
---------------------------------------------')
while True:
# 获取一条记录,每行数据都是一个元组
row = c.fetchone()
# 如果获取到的row 为 None,则退出循环
if not row:
break
print(row)
print(row[1] + '-->' + row[2])
c.close()
conn.close()
上面代码使用 execute() 方法执行一条 select 语句,查询条件是所有 _id 大于 2 的记录。在返回的查询结果中,有列字段信息,可通过游标的 description 属性得到查询的列信息,每一列的第1个元素就是列字段名称。另外,在获取查询结果时使用的是游标的 fetchone() 方法,一次获取一条查询记录,每一条查询记录都是一个元组。运行这段代码,输出结果如下所示:
查询结果的记录数: -1
_id name pass gender
---------------------------------------------
(3, '杜甫', 'abc123', 'male')
杜甫-->abc123
(4, '孟浩然', '123abc', 'male')
孟浩然-->123abc
(5, '武则天', 'xyz321', 'female')
武则天-->xyz321
(6, '陆游', 'klmn', 'male')
陆游-->klmn
从输出结果可以看到,此时游标的 rowcount 属性值是 -1。上面只执行了一次 select 语句查询,就能返回满足条件的多个查询结果,因此不能使用 executemany() 执行查询语句。如果要一次获取查询结果的多条记录,可以使用游标的 fetchmany(n) 或 fetchall() 方法,这两个方法获取的结果都是列表,列表的每个元素又是元组。通常如果返回的查询记录数量太多,不建议使用这两个方法,因为这可能导致内存开销过大和系统崩溃。
5、事务控制
事务是由一步或几步数据库操作序列组成的逻辑执行单元,这一系列操作要么全部执行,要么全部放弃执行。程序和事务是两个不同的概念。一般而言,在一段程序中可能包含多个事务。
事务具备4种特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持续性(Durability)。这4种特性简称为 ACID。
- 原子性:事务是应用中最小的执行单位,就像原子是最小颗粒一样不可再分,事务是应用中不可再分的最小逻辑执行体。
- 一致性:事务执行的结果,必须使数据库从一种一致性状态变到另一种一致性状态。当数据库只包含事务成功提交的结果时,数据库处于一致性状态。如果系统运行发生中断,某个事务尚未完成而被迫中断,而该未完成的事务对数据库所做的修改已被写入数据库中,此时数据库就处于一种不正确的状态。一致性是通过原子性来保证的。
- 隔离性:各个事务的执行互不干扰,任意一个事务的内部操作对其他并发的事务都是隔离的。也就是说,并发执行的事务之间不能看到对方的中间状态,它们不能互相影响。
- 持续性:也称为持久性(Persistence),指事务一旦提交,对数据所做的任何改变都要记录到永久存储器,通常就是保存到物理数据库中。
当事务所包含的任意一个数据库操作执行失败后,应该回滚(rollback)事务,使在事务中所做的修改全部失效。事务回滚有两种方式:显式回滚和自动回滚。
- 显式回滚:调用数据库连接对象的 rollback。
- 自动回滚:系统错误,或者强行退出。
在前面代码中执行的创建、更新语句,如果没有执行 commit() 方法,则不会提交事务,程序所做的修改不会被提交到底层数据库。
6、执行SQL脚本 executescript() 方法
对于 SQLite 数据库模块的游标对象有一个 executescript() 方法,这不是一个标准的 API 方法。在其他数据库 API 模块中可能没有这个方法。这个方法可以执行一段 SQL 脚本。示例如下:
import sqlite3
conn = sqlite3.connect('myfirst.db')
c = conn.cursor()
c.executescript('''
insert into user_tb values(null, '大郎', '111111', 'male');
insert into user_tb values(null, '金莲', '888888', 'female');
create table item_tb(_id integer primary key autoincrement,
name,
price);
''')
conn.commit()
c.close()
conn.close()
上面这段代码中调用了 executescript() 方法执行一段复杂的 SQL 脚本,这段SQL脚本有两条 insert 语句,该语句负责向 user_tb 表中插入记录,还使用 create 语句创建一个数据表。运行这段代码,可以 在 SQLite Expert 工具中看到结果。
为了简化编程,SQLite 数据库模块还为数据连接对象(注意不是游标对象)提供下面3个方法:
- execute(sql[, parameters]):执行一条SQL语句。
- executemany(sql[, parameters]):根据序列重复执行SQL语句。
- executescript(sql_script):执行SQL脚本。
这3个方法与游标对象包含的3个方法完全相同。数据库连接对象的这3个方法都不是 DB API 2.0 的标准方法,是游标对象的3个方法的快捷方式,因此在用法上与游标对象的3个方法完全相同。
7、创建自定义函数
数据库连接对象提供的 **create_function(name, num_params, func) **方法用于注册一个自定义函数,接下来就可以在 SQL 语句中使用该自定义函数。这个方法的3个参数说明如下:
- name 参数:指定注册的自定义函数的名字(为自定义函数取的名字)。
- num_params:指定自定义函数所需参数的个数。
- func:指定自定义函数对应的函数。
代码示例如下:
import sqlite3
# 先定义一个普通函数,准备注册为 SQL 语句中的自定义函数
def reverse_ext(st):
# 对字符串反转,前后添加方括号
return '[' + st[::-1] + ']'
conn = sqlite3.connect('myfirst.db')
# 调用数据库连接对象的 create_function 方法注册自定义函数:enc
# 注册定义函数常用于密码加密,密码加密算法可用 MD5 等
conn.create_function('enc', 1, reverse_ext)
c = conn.cursor()
# 在 SQL 语句中使用 enc 自定义函数
c.execute('insert into user_tb values(null, ?, enc(?), ?)',
('李世民', '123456', 'male'))
conn.commit()
c.close()
conn.close()
8、创建聚集函数
标准的SQL语句提供了如下5个标准的聚集函数:
- sum():统计总和。
- avg():统计平均值。
- count():统计记录条数。
- max():统计最大值。
- min():统计最小值。
如果要使用与其他业务相关的聚集函数,可使用数据库连接对象提供的 create_aggregate(name, num_params, aggregate_class) 方法注册一个自定义的聚集函数。参数说明如下:
- name:指定自定义聚集函数的名字。
- num_params:指定聚集函数所需的参数个数。
- aggregate_class:指定聚集函数的实现类。该类必须实现 step(self,params...) 和 finalize(self) 方法,其中 step() 方法对于查询所返回的每条记录各执行一次;finalize(self) 方法只在最后执行一次,该方法的返回值将作为聚集函数最后的返回值。
下面代码示例了,使用自定义聚集函数获取 user_tb 表中长度最短的密码。
import sqlite3
# 先定义一个普通类,准备注册为 SQL 中的自定义聚集函数
class MinLen:
def __init__(self):
self.min_len = None
# step() 方法会对每条查询记录执行一次
def step(self, value):
# 如果 self.min_len 还未赋值,则直接将当前 value 赋值给 self.min_lin
if self.min_len is None:
self.min_len = value
# 找到一个长度更短的 value,用 value 代替 self.min_len
if len(self.min_len) > len(value):
self.min_len = value
# finalize() 只执行一次,它的返回值就是聚集函数的返回值
def finalize(self):
return self.min_len
conn = sqlite3.connect('myfirst.db')
# 第1步:注册自定义函数,调用数据库连接对象的 create_aggretate() 注册自定义聚集函数:min_len
conn.create_aggregate('min_len', 1, MinLen)
c = conn.cursor()
# 第2步:使用自定义函数,在 SQL 语句中使用 min_len 自定义聚集函数,查询到的结果都会在自定义聚集 min_len 中执行一次
c.execute('select min_len(pass) from user_tb')
print(c.fetchone()[0])
conn.commit()
c.close()
conn.close()
9、创建比较函数
标准的SQL语句提供有 order by 子句,可用于对查询结果进行排序,这种排序按照默认的排序规则进行。如果需要按照相关的业务规则进行排序,则需要创建自定义的比较函数。
数据库连接对象的 create_collation(name, callable) 方法可用于注册一个自定义的比较函数。这个方法的两个参数说明如下:
- name:指定自定义比较函数的名字。
- callable:指定自定义比较函数对应的函数。这个函数有两个参数,并对这两个参数进行大小比较,如果该方法返回正整数,则第一个参数更大;如果返回负整数,则第二个参数更大;如果返回0,则两个参数相等。
注意:callable 函数的参数以 bytes 字节串的形式传入,因此系统默认会以 UTF-8 字符集将字符串编码成字节串后传入 callable 函数。
现在要求对 user_tb 表中的 pass 进行排序,但 pass 列部分记录使用了加密:第一个字符和最后一个字符都是方括号,因此需要去掉 pass 列前后两个方括号之后再进行排序。所以,需要自定义比较函数,首先将字符串的第一个字符和最后一个字符去掉后再比较大小。代码示例如下:
import sqlite3
# 第1步:创建比较函数 my_collate()
# 去掉字符串的第一个字符"["和最后一个字符"]"后再比较大小
def my_collate(str1, str2):
if str1.startswith('[') and str1.endswith(']'):
str1 = str1[1:-1]
if str2.startswith('[') and str2.endswith(']'):
str2 = str2[1:-1]
if str1 == str2:
return 0
elif str1 > str2:
return 1
else:
return -1
conn = sqlite3.connect('myfirst.db')
# 第2步:调用数据库连接对象的 create_collation() 方法注册自定义比较函数:sub_cmp
conn.create_collation('sub_cmp', my_collate)
c = conn.cursor()
# 第3步:在 SQL 语句中使用 sub_cmp 自定义比较函数
c.execute('select * from user_tb order by pass collate sub_cmp')
# 采用 for 循环遍历游标
for row in c:
print(row)
conn.commit()
c.close()
conn.close()
上面这段代码中,使用自定义的大小比较函数分为3步,分别是:创建比较函数、注册比较函数、使用比较函数。运行这段代码,可以看到查询结果是按 pass 列去掉前后“[]"之后进行排序的。此外,上面代码还用到游标的一个特点:游标本身是可迭代对象,因此不需要使用 fetchone() 来逐行获取查询结果,而是直接使用 for 循环遍历游标获取查询结果集。输出结果如下:
(7, '大郎', '111111', 'male')
(1, '范成大[宋]', '123456', 'male')
(4, '孟浩然', '123abc', 'male')
(9, '李世民', '[654321]', 'male')
(8, '金莲', '888888', 'female')
(2, '李白', 'abc123', 'male')
(3, '杜甫', 'abc123', 'male')
(6, '陆游', 'klmn', 'male')
(5, '武则天', 'xyz321', 'female')
三、操作 MySQL 数据库
使用 Python 的 DB API 2.0 来操作 MySQL数据库与操作 SQLite 数据库差别不大,因为 MySQL 数据库模块也遵循相同的 DB API 2.0 规范。下面先来安装 MySQL 数据库。
1、下载和安装 MySQL 数据库
安装 MySQL 与安装普通软件基本相同,关键是在配置 MySQL 数据库时需要注意选择支持中文的编码集。
第1步:在 http://dev.mysql.com/downloads/mysql/ 站点下载 MySQL 数据库社区版(Community)的最新版本,下载适用当前 Windows 平台的 MSI Installer 安装文件。
详细安装过程省略!
2、使用 pip 工具管理模块
Python 自带的 pip 工具可用来查看、管理所安装的各种模块。
查看已安装的模块,使用下面命令:
pip show packagename
比如要查看操作 MySQL 的 mysql-connector-python 模块有没有安装,在命令行中输入下面的命令:
pip show mysql-connector-python
mysql-connector-python 是模块名字,如果已经安装,在输出结果可以看到该模块的基本信息,比如该模块的版本号、官方网址、安装路径等。
卸载已安装的模块,命令如下:
pip uninstall packagename
比如要卸载 mysql-connector-python 模块,使用命令如下:
pip uninstall mysql-connector-python
在卸载模块的时候,会进行二次询问,输入 y 后会就会删除相应的模块及目录。
查看已安装的所有模块,可使用下面的命令:
**pip list **
安装模块:命令如下
pip install packagename
比如要安装 mysql-connector-python 模块,可使用命令:
pip install mysql-connector-python
这样默认会安装最新的版本。成功安装模块后会出现 Successfully 信息。
还可以在安装模块的时候指定版本号,也就是安装指定的版本,例如:
pip install mysql-connector-python ==1.0.4
除使用 MySQL 官方提供的 Python 模块来连接 MySQL外,还有一个使用广泛的连接 MySQL 数据库的模块 MySQL-python,其官方站点是 https://pypi.org/project/MySQL-python/。
使用 pip 方式安装模块时,因为默认安装源都在国外,有些模块安装费力还可能安装不成功,可以在 pip 安装命令后面添加 ”-i“ 参数来指定临时使用国内源。常用的国内pip镜像有:
阿里云 http://mirrors.aliyun.com/pypi/simple
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple
豆瓣(douban) http://pypi.douban.com/simple
例如使用清华大学国内源安装 mysql-connector-python 模块,命令如下:
pip install mysql-connector-python -i https://pypi.tuna.tsinghua.edu.cn/simple
3、执行 DDL 语句,create 语句
安装好 mysql-connector-python 模块后,先检查一下该模块的全局属性。示例如下:
>>> import mysql.connector
>>> mysql.connector.apilevel
'2.0'
>>> mysql.connector.paramstyle
'pyformat'
>>>
从上面的输出可知,mysql-connector-python 数据库模块遵守 DB API 2.0 规范,且该模块允许在 SQL 语句中使用扩展的格式代码(pyformat)来代表参数。
MySQL 数据库有服务器进程,默认通过 3306 端口对外提供服务。因此,在使用 Python 连接 MySQL 数据库需要指定远程服务器 IP 地址和端口,如果不指定服务器 IP 地址和端口,则使用默认的服务器 IP 地址 localhost 和默认的端口 3306。
下面代码示例如何连接 MySQL 数据库,并通过 DDL 语句来创建两个数据表。
import mysql.connector
# 第1步:连接 MySQL 数据库,需要提供服务器IP地址、数据库端口号、数据库用户名和密码,以及数据库名称
conn = mysql.connector.connect(user='michael', password='michael123', host='192.168.64.50', port='3508', database='python', use_unicode=True)
# 第2步:获取游标
c = conn.cursor()
# 第3步:执行 DDL 语句创建数据表 user_tb
c.execute('''create table user_tb(user_id int primary key auto_increment,
name varchar(255),
pass varchar(255),
gender varchar(255))''')
# 继续创建数据表 order_tb
c.execute('''create table order_tb(order_id integer primary key auto_increment,
item_name varchar(255),
item_price double,
item_number double,
user_id int,
foreign key(user_id) references user_tb(user_id))''')
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
与连接 SQLite 数据库相比,连接 MySQL 数据库最大的区别在于:要指定服务器主机的IP地址及MySQL的端口号,还要在服务器中先创建好数据库 python。创建数据库python的命令是:
create database python;
执行上面这段代码,会在远程服务器上的MySQL数据库的 python 数据中创建两个表 user_tb 和 order_tb。在 order_tb 表中有一个外键列引用了 user_tb 表的 user_id 主键列。成功执行上面的代码后,可以在服务器上执行下面的命令查看表的基本信息:
desc user_tb;
desc order_tb;
如果遇到使用 Python 程序不能连接远程服务器的MySQL数据,可在远程服务器中关闭防火墙,命令是:
iptables -F
4、执行 DML 语句,insert、update、delete语句
MySQL 数据库同样可以使用游标的 execute() 方法执行 DML 的 insert、update、delete 语句,对数据进行插入、修改和删除数据操作。下面代码分别向两个数据表中插入一条数据。
import mysql.connector
# 第1步:连接 MySQL 数据库,需要提供服务器IP地址、数据库端口号、数据库用户名和密码,以及数据库名称
conn = mysql.connector.connect(user='michael', password='michael123', host='192.168.64.50', port='3508', database='python', use_unicode=True)
# 第2步:获取游标
c = conn.cursor()
# 第3步:调用游标的 execute() 方法执行 insert 语句插入数据
c.execute('insert into user_tb values(null, %s, %s, %s)',
('杜甫', '123456', 'male'))
c.execute('insert into order_tb values(null, %s, %s, %s, %s)',
('显示器', '1699', '2', 3))
# 需要提交事务后,才能在数据库中查询到
conn.commit()
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
注意上面两条插入数据语句的代码,这里的SQL语句中的占位符是 %s,这正是 mysql.connector.paramsytle 属性所标识的 pyformat,它指定在 SQL 语句中使用扩展的格式代码来作为占位符。运行上面这段代码后,在数据库中可使用下面命令查看插入的结果:
select * from user_tb;
select * from order_tb;
MySQL 数据库也支持使用 executemany() 方法重复执行一条 SQL 语句,示例如下:
import mysql.connector
# 第1步:连接 MySQL 数据库,需要提供服务器IP地址、数据库端口号、数据库用户名和密码,以及数据库名称
conn = mysql.connector.connect(user='michael', password='michael123', host='192.168.64.50', port='3508', database='python', use_unicode=True)
# 第2步:获取游标
c = conn.cursor()
# 第3步:调用游标的 executemany() 方法多次执行同一条 insert 语句插入数据
c.executemany('insert into user_tb values(null, %s, %s, %s)',
(('李白', '123456', 'male'),
('孟浩然', '123456', 'male'),
('陶渊明', '123455', 'male'),
('王 维', '123456', 'male'),
('辛弃疾', '123456', 'female')))
conn.commit()
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
使用游标的 executemany() 方法还可以执行 update、delete 语句,下面代码示例了使用 update 语句。
import mysql.connector
# 第1步:连接 MySQL 数据库,需要提供服务器IP地址、数据库端口号、数据库用户名和密码,以及数据库名称
conn = mysql.connector.connect(user='michael', password='michael123', host='192.168.64.50', port='3508', database='python', use_unicode=True)
# 第2步:获取游标
c = conn.cursor()
# 第3步:调用游标的 executemany() 方法多次执行同一条 insert 语句插入数据
c.executemany('update user_tb set pass=%s where name=%s',
(('1a2b3c','李白'),
('11ab22','孟浩然'),
('haha','陶渊明'),
('xyz','王 维'),
('9Af86','辛弃疾')))
conn.commit()
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
下面代码示例了使用 delete 语句,需要注意的是,这里使用 delete 语句删除 user_tb 表中的记录,由于该表中的部分记录的 id 字段关联了 order_tb 表中的记录,如果要删除这种有关联的记录,需要同步删除 order_tb 中的记录才行。
import mysql.connector
# 第1步:连接 MySQL 数据库,需要提供服务器IP地址、数据库端口号、数据库用户名和密码,以及数据库名称
conn = mysql.connector.connect(user='michael', password='michael123', host='192.168.64.50', port='3508', database='python', use_unicode=True)
# 第2步:获取游标
c = conn.cursor()
# 第3步:调用游标的 executemany() 方法多次执行同一条 insert 语句插入数据
c.executemany('delete from user_tb where name=%s',
(('李白',),
('孟浩然',)))
conn.commit()
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
此外,MySQL 数据库模块的连接对象有一个 autocommit 属性,如果将该属性设为 True,则意味着关闭该连接的事务支持,在每次执行 DML 语句后都会自动提交,这样无须调用连接对象的 commit() 方法来提交事务。示例如下:
import mysql.connector
# 第1步:连接 MySQL 数据库,需要提供服务器IP地址、数据库端口号、数据库用户名和密码,以及数据库名称
conn = mysql.connector.connect(user='michael', password='michael123', host='192.168.64.50', port='3508', database='python', use_unicode=True)
# 将 autocommit 设为 True
conn.autocommit = True
# 下面执行的 DML 语句会自动提交
...
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
5、执行查询语句:select
使用 MySQL 数据库模块的查询语句时,要注意 SQL 语句中的占位符,占位符是 %s。下面的代码中调用了 execute() 方法执行 select 语句查询数据,与 SQLite 数据库模块的差别就只在占位符上。
import mysql.connector
# 第1步:连接 MySQL 数据库,需要提供服务器IP地址、数据库端口号、数据库用户名和密码,以及数据库名称
conn = mysql.connector.connect(user='michael', password='michael123', host='192.168.64.50',
port='3508', database='python', use_unicode=True)
conn.autocommit = True
# 第2步:获取游标
c = conn.cursor()
# 第3步:调用游标的 execute() 方法执行 select 查询语句
c.execute('select * from user_tb where user_id > %s', (4,))
# 通过游标的 description 属性获取列字段信息
for col in (c.description):
print(col[0], end=' ')
print('
-------------------------------')
# 直接使用 for 循环遍历游标中的结果集
for row in c:
print(row)
print(row[1] + '-->' + row[2])
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
运行上面这段代码,输出结果如下:
user_id name pass gender
-------------------------------
(6, '陶渊明', 'haha', 'male')
陶渊明-->haha
(7, '王 维', 'xyz', 'male')
王 维-->xyz
(8, '辛弃疾', '9Af86', 'female')
辛弃疾-->9Af86
上面代码中对MySQL连接对象的游标对象使用了 for 循环,除此之外,游标对象同样支持 fetchone()、fetchmany()、fetchall()方法,这3个方法的使用方法参考前面 SQLite 模块的用法。
6、调用存储过程
MySQL 数据库模块为游标对象提供了一个非标准的 callproc(self, procname, args=()) 方法,该方法用于调用数据库存储过程。其中 procname 参数代表存储过程的名字,args 参数用于为存储过程传入参数。
下面的 SQL 脚本在 MySQL 数据库中创建一个简单的存储过程。登录 MySQL 数据库,连接 python 数据库后,输入如下 SQL 脚本来创建存储过程。
MySQL [python]> delimiter //
MySQL [python]> create procedure add_pro(a int, b int, out sum int)
-> begin
-> set sum = a + b;
-> end;
-> //
下面的代码使用 MySQL 数据库模块来调用存储过程。
import mysql.connector
# 第1步:连接 MySQL 数据库,需要提供服务器IP地址、数据库端口号、数据库用户名和密码,以及数据库名称
conn = mysql.connector.connect(user='michael', password='michael123', host='192.168.64.50', port='3508', database='python', use_unicode=True)
conn.autocommit = True
# 第2步:获取游标
c = conn.cursor()
# 第3步:调用 callproc() 方法执行存储过程
# 虽然 add_pro 存储过程需要 3 个参数,但最后一个参数是传出参数
# 存储过程的值无须使用,因此这里用一个 0 来占位置
result_args = c.callproc('add_pro', (8, 4, 0))
# 返回的 result_args 既包含传入参数的值,也包含传出参数的值
print(result_args) # (8, 4, 12)
# 如果只需要访问传出参数的值,可直接访问 result_args 的第3个元素即可
print(result_args[2]) # 12
# 第4步:关闭游标
c.close()
# 第5步:关闭连接
conn.close()
上面代码中的 c.callproc('add_pro', (8, 4, 0)) 调用了存储过程,存储过程的名字是 add_pro,这个名字是在 MySQL 数据库中的 python 数据库中创建的,在创建存储过程时指定了3个参数,所以这里调用存储过程时,就传入了包含 3 个元素的元组为存储过程传入参数;对于存储过程的传入参数,该参数对应的元组元素负责为传入参数传值;对于存储过程的传出参数,该参数对应的元组元素随便定义即可。运行上面代码,输出结果如下所示:
(8, 4, 12)
12
从输出可知,调用存储过程后,会返回传入参数和传出参数组成的元组。如果只需要获取传出参数的值可通过返回的结果元组取出对应的值即可。
四、小结
- 本节使用 SQLite 模块操作 SQLite 数据库,使用 MySQL 数据库模块操作 MySQL 数据库;
- 对比这两个数据库的操作,有很多相似的地方,这是因为都属于 Python DB API 2.0 规范;
- 无论哪种数据库模块,只要遵守 Python DB API 2.0 规范,其编程步骤和编程方法与本节的编程步骤和编程方法类似。
- 通过这两个数据库的编程方法,学习掌握使用 Python 操作所有数据库的方法。
- 掌握 Python DB API 2.0 规范,并掌握 Python 操作数据库的主要流程,包括连接数据库的方法,以及使用 execute()、executemany() 执行不同的 SQL 语句,并通过游标获取查询结果。
- 不同的数据库模块游标对象提供的方法略有差异,比如,SQLite 模块的游标提供了 executescript() 方法来执行 SQL 脚本,MySQL 数据库模块的游标提供了 callproc() 方法来调用存储过程。