Hash
将不知道什么东西映射到一个小范围的数上。相比用map而言,手写Hash往往会做到更高的效率。
Hash的一大用处是储存和查询两个复杂数据的存在情况。这对于判断多个字符串相等往往有很大优势。
在OI中有一种非常重要的Hash函数,它的运转方式如下:
把字符串(s)看成一个(P)进制数,这样就可以给每个数赋上一个正的权值。具体来说,它返回的是一个无符号的长整数(省去了取模操作),大小:
当(P = 131)或(P = 13331)时,冲突的概率极低。
另外,上面这个公式还有递推版本和区间版本:((c)是单个字符)
这样,假设只有(q)个字符串,我们就可以用(O(q|s|))的时间内处理每个字符串前缀的哈希值,并仅用(O(1))判断两个字符串或者它们的子串是否相等了。
单词背诵。我给出了一个长度为(N(N leq 1000))的单词表,希望背下它们。但我打算通过阅读文章来背诵它们。具体来说,我有一篇含单词数为(M(M leq 10^6))的文章,而我会节选其中连续的一段,将其提取,并每天阅读。我希望求出这篇文章中最多涵盖了多少我单词表里的单词,并且在涵盖极大单词的情况下,我最短可以摘选多短的文章。
这里体现了Hash表的经典应用,即快速查询两个字符串是否相等。可以预处理出文章和单词表内所有单词的哈希值,并二分查找文章中单词对应单词表里的单词编号。此时问题变成了“涵盖所有目标元素的极大子段”,先求出最多的单词数(cnt),然后用两个指针线性扫描文章。每扩展一次右边界时,贪心地缩小左边界,然后更新答案。预处理(O(Nlog N + M|s|log N)),而扫描是线性的。如果这道题对哈希值取合适的模数,可以省去排序的步骤,把预处理降到(O(M|s|));但为了防止哈希冲突,这里我们还是采用最稳妥的做法。
inline ull Hash(char *str)
{
int len = strlen(str);
ull ret = 0;
RP(i, 0, len - 1) ret = ret * P + (str[i] - 'a' + 1);
return ret;
}
inline int bs(ull CH){
int l = 1, r = N;
while(l < r){
int mid = (l + r) >> 1;
if(HS[rev[mid]] >= CH)
r = mid;
else
l = mid + 1;
}
if(HS[rev[l]] == CH)
return rev[l];
else
return 0;
}
inline void init(){
RP(i, 1, N) HS[i] = Hash(S[i]), buf[i] = mp(HS[i], i);
sort(buf + 1, buf + N + 1);
RP(i, 1, N) disc[buf[i].second] = i, rev[i] = buf[i].second;
RP(i, 1, M) HT[i] = Hash(T[i]), match[i] = bs(HT[i]);
}
int main(){
N = qr(1);
RP(i, 1, N) scanf("%s", S[i]);
M = qr(1);
RP(i, 1, M) scanf("%s", T[i]);
init();
int l = 1, r = 1;
while(r <= M && cnt < N){
if(match[r] > 0 && buc[match[r]] == 0) ++ cnt;
++ buc[match[r]];
++ r;
}
if(cnt == 0){
puts("0");puts("0");
return 0;
}
r = 1; int tmp = 0; memset(buc, 0, sizeof(buc));
while(r <= M && tmp < cnt){
if(match[r] > 0 && buc[match[r]] == 0) ++ tmp;
++ buc[match[r]];
++ r;
}
-- r;
while(r <= M){
while(l < r){
if(buc[match[l]] == 1)
break;
if(buc[match[l]]) -- buc[match[l]];
++ l;
}
ans = min(ans, r - l + 1);
++ r; ++ buc[match[r]];
}
printf("%d
%d", cnt, ans);
return 0;
}
附:ELFHash
偏工程向,但是还是可以拿来一用。其基本思想是每次载入当前字符的ASCLL码,然后让编码相互杂糅,互相产生影响。具体的原理超出了本文的讨论范围,故这里只粘贴代码:
inline ull Hash(char *str)
{
ull ret = 0, x = 0;
while(*str){
ret = (ret << 4) + *str;
if((x = ret & 0xf000000L) != 0){
ret ^= (x >> 24);
ret &= ~x;
}
++ str;
}
return (ret & 0x7fffffff);
}
顺带一提,最近使用这个ELFhash,结果出现了相当罕见的Hash冲突。只能说酌情使用吧。
KMP
KMP利用一个nxt数组维护了“如果当前不匹配,我应该从哪里开始匹配起”。它一定是针对模式串而言的。具体来说,它保存的是(p(i)=max{j, S_{i - j + 1cdots i} = S_{1cdots j}}),即当前前缀子串中,最长的前缀和后缀相等的长度。可以结合下面这个图理解一下:
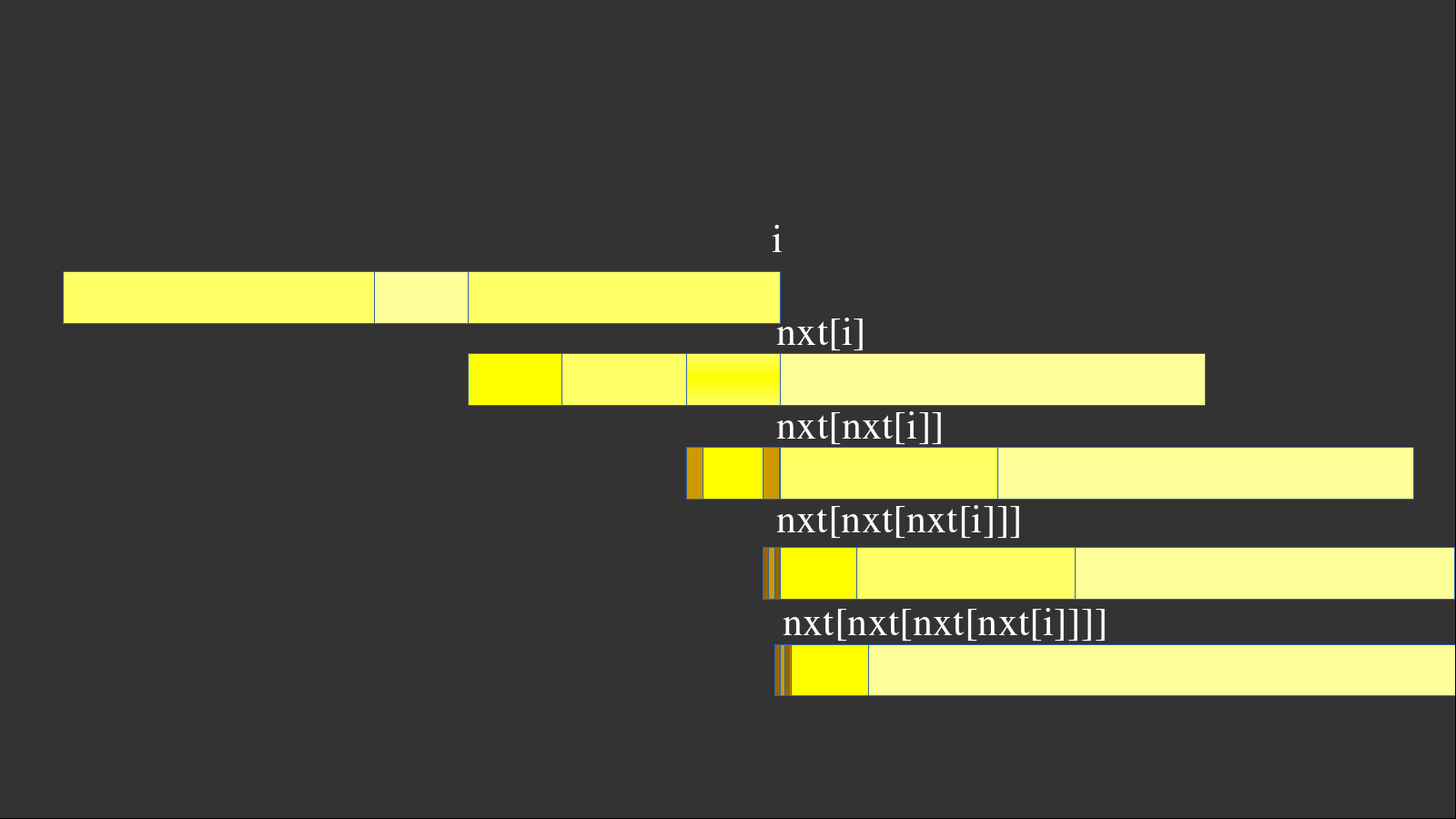
假设模式串(S)在(1cdots i)都匹配,唯独在(i+1)不匹配,我们就要重新匹配。但是,我们不需要从头开始,而是从( ext{nxt}(i))开始。因为(1cdots i)均匹配,(i- ext{nxt}(i)+1cdots i)显然也一定匹配。由于最长性,我们从( ext{nxt}(i))开始匹配一定更优。
问题就在于,如何求( ext{nxt}(i))?朴素的做法会达到(O(|S|^2))。可以考虑这样的思路:
假设我从(i)扩展到(i+1),如果恰好(S_{ ext{nxt}(i)+1} = S_{i+1}),那显然是最好的。
可大部分情况下不能直接扩展。我们需要在( ext{nxt}(i))之前找到一个位置(j),使得(S_{j+1} = S_{i+1}),并令( ext{nxt}(i+1) = j+1)。这个过程正是一个KMP匹配的过程,因此可以把(S)本身当成一个文本串,用自己匹配自己。
不过很抱歉的是,目前我也不能太理解这个精妙的算法,因此只能先张贴代码:
const int MAXL = 1e6 + 2;
char T[MAXL], S[MAXL]; int lT, lS;
int nxt[MAXL];
inline void init(){
nxt[1] = 0;
int r = 0;
RP(i, 2, lS){
while(r > 0 && S[r + 1] != S[i])
r = nxt[r];
if(S[r + 1] == S[i])
++ r;
nxt[i] = r;
}
}
inline void KMP(){
int r = 0;
RP(i, 1, lT){
while(r > 0 && S[r + 1] != T[i])
r = nxt[r];
if(S[r + 1] == T[i])
++ r;
if(r == lS)
printf("%d
", i - lS + 1), r = nxt[r];
}
}
int main(){
scanf("%s", T + 1);
scanf("%s", S + 1);
lT = strlen(T + 1), lS = strlen(S + 1);
init();
KMP();
RP(i, 1, lS) printf("%d ", nxt[i]);
return 0;
}
只能说这个算法和树状数组一样,写起来和记起来都不算难,但如何理解却有相当大的难度。
manacher
回文串的定义:若一个字符串的每一个字符(S_i)都满足(S_i = S_{|S|+1-i}),则(S)是一个回文串。当然,一个串(S)本身可能不是回文串,但它一定存在至少(|S|)个回文子串。(单个字符也要考虑!)一个回文子串的直径就是它的长度。现在请你求出一个字符串(S)的所有回文子串中最长的回文直径。
回文串的判定比较复杂,分为奇回文串(形如(ABA))和偶回文串(形如(BB))。为了方便判定,我们在相邻的字符之间加入'#'号,从而将任意回文串的判定改为“奇回文串的判定”。这等价于插入(S_{0.5},S_{1.5},cdots)等字符。
上面我所提到的“回文直径”可以直接无视,因为比它更重要的是回文半径:对于一个长度为(d)的奇回文串,它的回文半径(r = frac{1}{2}(d-1))。考虑对于每一个字符,用暴力拓展回文半径的算法,可以做到(O(N^2))。有没有更快的呢?
算法中一个非常重要的优化手段就是利用已知信息,用空间换时间。我们考虑若干个回文半径之间的关系,发现了一个重要的关系:当先前某个点的回文半径足够大,足以覆盖当前带扩展点时,我们可以直接继承先前的答案。什么意思呢?请看下图:
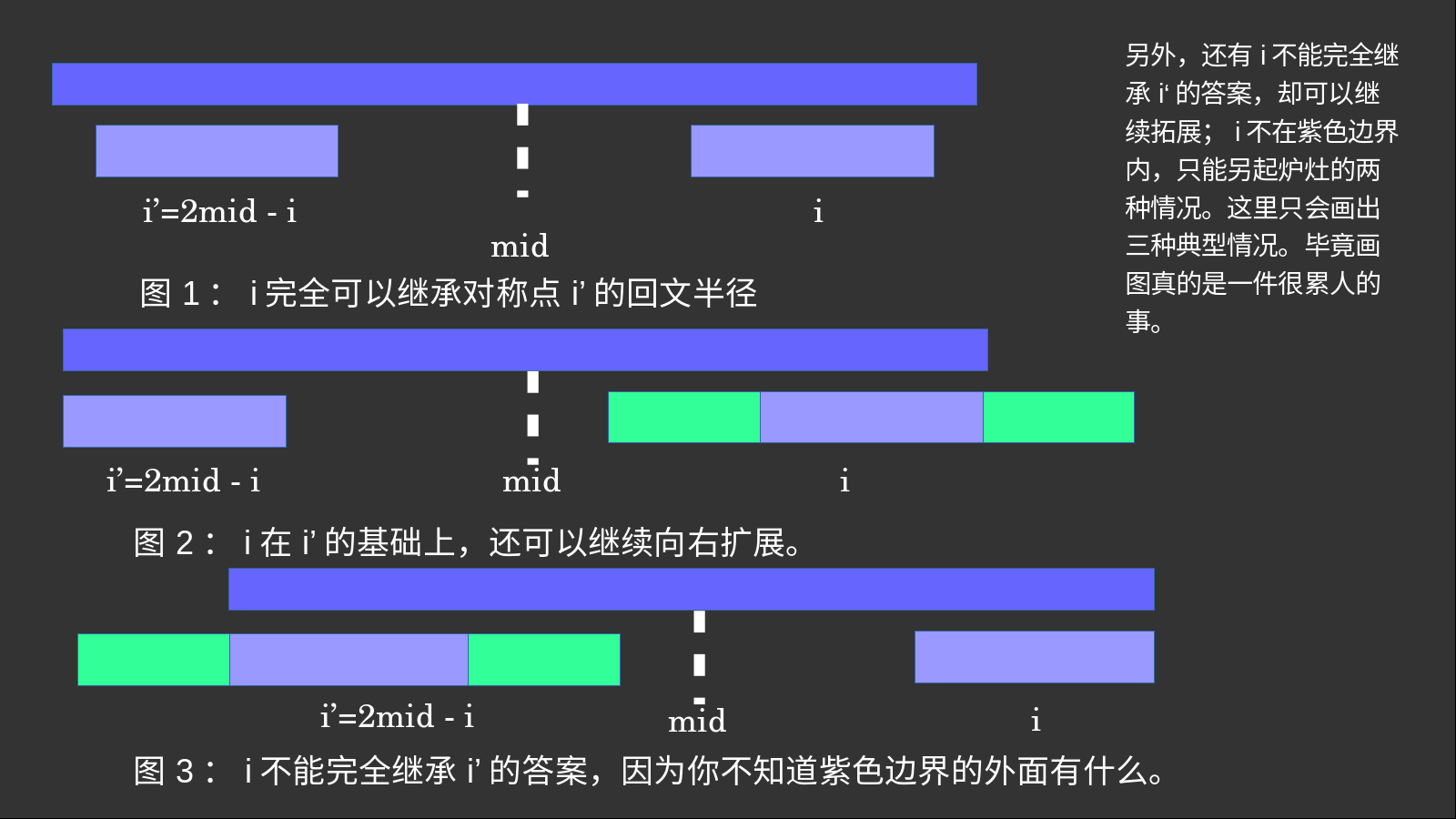
如果当前待求的回文中心(i)在一个足够长的回文串内,且(i)形成的回文串足够小,那么一定存在一个(i')与(i)关于(mid)对称,且这两个回文串的长度是完全相同的。因此,(i')的答案可以直接传给(i)。
当然,还有两种特殊情况:
- (i)可以扩展到青色的部分,而(i')做不到。这种情况下直接在(i')的回文半径的基础上,继续向右扩展即可。
- (i')可以扩展到青色的部分,而(i)做不到。此时(i)最多只能继承(R-i)大小的半径(即扩展的边界不能超过紫色边界)
情况很多,但是可以直接令当前回文半径(r(i) = min(r(i'), R - i)),然后再尝试向右扩展(r(i) = r(i) + delta r)就可以了。这个做法可以解决一切问题。
每次维护当前回文串的最右边界(R),就可以尽可能多地覆盖到小回文串。由于回文串可以(O(1))继承在当前“大回文串”内的所有答案,这个算法可以做到(O(N))。
顺便注意一下,为了防止扩展越界,我们会在整个字符串(S)的最前面和最后面加上一个特殊字符表示边界,比如$ * @等。当然,你也可以直接用if特判。
最后一定要注意,上述操作都是对于加入#的字符串而言。原串的最长回文子串长度,应该等于当前串中的(rmid_{max} - 1)。
int main(){
scanf("%s", buf);//buf是一个临时输入数组
int len = strlen(buf);
S[1] = '#';
RP(i, 0, len - 1){
S[(i + 1) << 1] = buf[i];
S[((i + 1) << 1) + 1] = '#';
}
len = (len << 1) + 1;
S[0] = '$', S[len + 1] = '@';//起始符和终止符,防止越界。另外,这两个字符一定要不同,不然会误判“整个字符串都是回文串”的情况。
RP(i, 1, len){
if(i <= R)
r[i] = min(r[(mid << 1) - i], R - i);
else
r[i] = 1;
while(S[i - r[i]] == S[i + r[i]]) ++ r[i];
if(i + r[i] > R){
R = i + r[i];
mid = i;
}
}
int ans = 0;
RP(i, 1, len)
ans = max(ans, r[i]);
printf("%d", ans - 1);
return 0;
}
Z-algorithm
又称扩展KMP。可以快速处理出串(S)与其所有后缀的最长公共前缀。可以用KMP类似的方法求一个( ext{nxt})数组,但是更简单的方法还是利用manacher的思想。
转载一下原作者的博客链接:cosmicAC。
和manacher一样,设(r(i))表示从(i)开始的后缀和原串的最长公共前缀长度。和回文串一样,当某一个lcp足够大,足以覆盖当前扩展点时,我们可以直接从前面继承答案。设这个lcp的后缀起点为(t),和manacher类似,我们可以令(r(i) = min(r(l-t+1), t + r(t) - i)),然后暴力扩展剩余未知的部分,直到找到第一个(S_{r(i)}
eq S_{i+r(i)})的(r(i)),然后更新(t)。似乎这个(r(i))数组又称“(z)数组”,这个算法才得名Z-algorithm。
如何求文本串(S)与模式串(T)的各后缀的lcp?只需要把(T)与一个分隔符(Lambda)与文本串(S)按顺序连接成(T + Lambda + S),再求(T + Lambda + S)的(r(i))数组即可。答案为从分隔符后开始的(r(i))。
另外,扫描要注意直接从(1)而不是(0)开始,原理应该和KMP在自匹配的过程一样。
int main(){
scanf("%s", S); int Sl = strlen(S);
scanf("%s", T); int Tl = strlen(T);
strcat(C, T), strcat(C, "$"), strcat(C, S);
len = strlen(C);
T[len + 1] = '@';
RP(i, 1, len - 1){
if(i <= r[t] + t)
r[i] = min(r[i - t], r[t] + t - i);
else
r[i] = 0;
while(C[i + r[i]] == C[r[i]])
++ r[i];
if(i + r[i] > t + r[t])
t = i;
}
RP(i, 0, Tl - 1) printf("%d ", i == 0 ? Tl : r[i]);
putchar('
');
RP(i, Tl + 1, len - 1) printf("%d ", r[i]);
return 0;
}
另外,补充一下这个算法和普通KMP的转换关系:
if(i + r[i] > t + r[t]){
RP(j, t + r[t], i + r[i] - 1) nxt[j] = j - i + 1;
t = i;
}
Trie
一种特殊的数据结构,用于维护若干个单词。
Trie有一种类似自动机的结构,可以通过字符指针(p(q, c) = qprime)转移到不同的状态,并可以标记终态以标识这个单词的结尾。
注意一下,Trie的空间复杂度为(O(|Sigma|N|S|)),其中(N)为单词数,(|Sigma|)为字符集大小,(|S|)为单词平均长度。如果没有算好空间,Trie树很有可能会MLE。
单次插入单词和查询单词存在性的时间复杂度都是(O(|S|))的。
Trie还有一些神奇的应用。举个例子:给定一个数集(A_i),求从中选出两个数,使得两个数的异或和最大。最暴力的做法是直接(O(N^2))比较,而通过Trie树可以做到(O(N log A_{max}))。通过贪心,对于一个数(x),我们每次尝试转移到它的相反位;如果不能转移,就妥协走另一边。比如这道题:最长异或路径。
AC自动机
本质上是在Trie树上建立KMP自动机。但怎么建?这是一个大问题。
仔细回忆一下KMP的实现方法:当遇到一个失配位置时,我们需要不断迭代( ext{nxt})指针,在保证前几位匹配时,找到尽可能大的( ext{nxt})位置。
回忆一下,KMP( ext{nxt}(i))数组的含义是“当前子串里,前缀和后缀的最长公共子串”。此时从(S_1)走到(S_{ ext{nxt}(i)})这个过程,和(S_{i- ext{nxt}(i)+1})走到(S_{i})完全等效。这个性质保证了我每次可以尽可能小地往回跳。
AC自动机同理。(fail)指针使得“从某个状态转移到(q)状态”,和“从根节点转移到(fail(q))状态”完全等效。这使得我们失配之后有依可循。你可以把(fail)指针看成一条(varepsilon)转移边,因为它的转移不需要消耗任何字符。
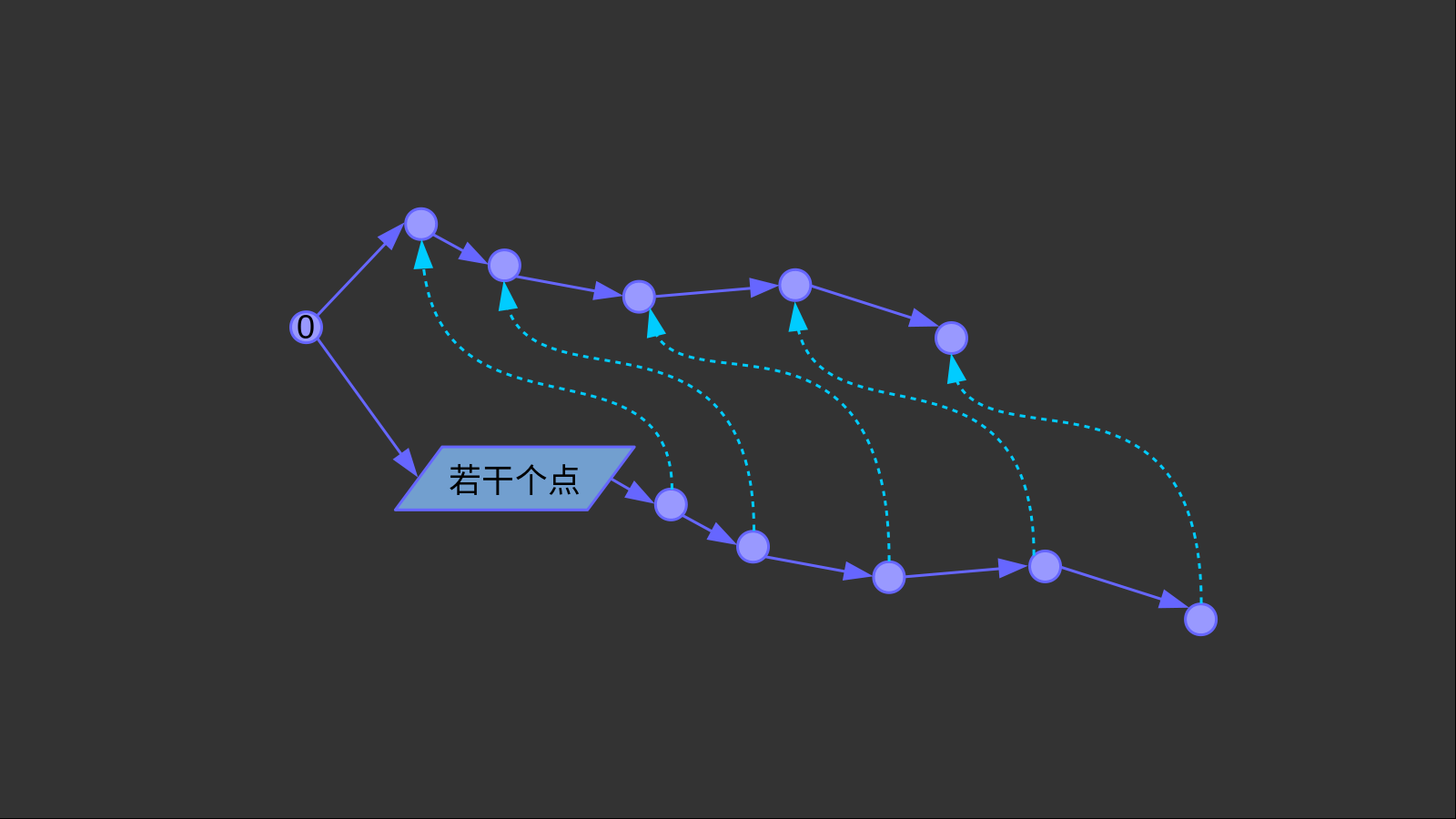
如上图所示。这两条紫色的链条完全相同,但其中一个直接接在根节点上,而一个接在若干个点前。此时我们就可以用若干个(fail)指针连接两条链。这样,当当前指针失配时,我们可以随时跳转到另一条链上。
如何连(fail)边?假设整个trie树的根节点为(0),那么对于任意一个(p(0,c)),它的失配指针只能指向(0)。这和KMP算法的初始化是一样的。
接下来,我们分层进行。对于一个节点(u),如果后继状态(p(u,c))存在,那我们从后继状态连一条“平行”的(fail)边指向另一条链,即令(fail(p(u,c)) = p(fail(u),c))。这样就可以形成向上图那样的分层网格的形状了。
如果(p(u,c))不存在,那么我们直接把这个转移边和(fail(u))的转移边合并,即令(p(u,c) = p(fail(u),c))。这样做的好处是可以形成一个(trie)图,从而得以查询任意长的字符串。
但是,一个trie图的结构过于复杂。举个例子,单词组(mathcal{hat},mathcal{cat},mathcal{cup})的trie图如下:
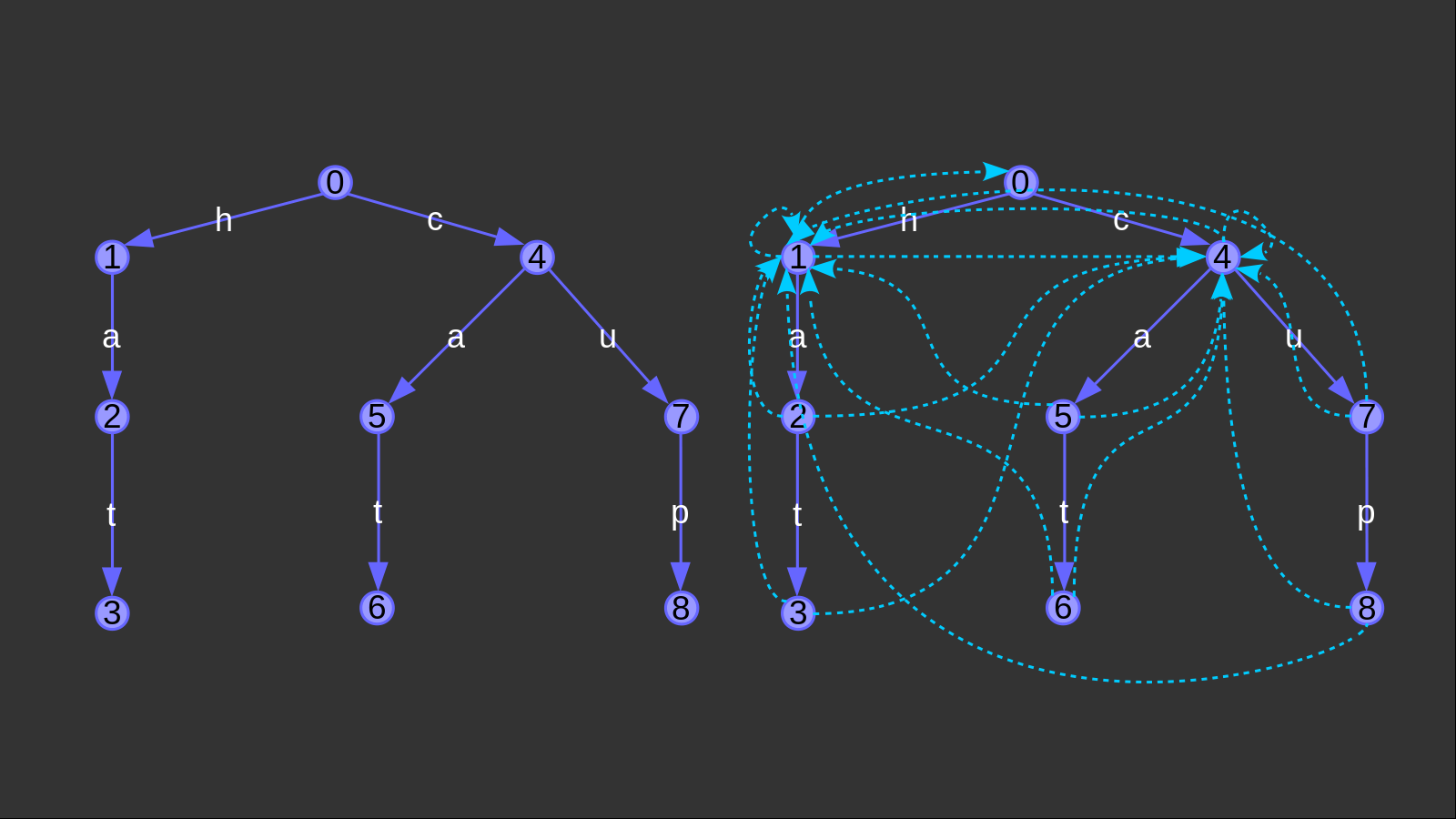
事实上,从每个节点出发都有(26)条边可走。青色的边不是(fail)边(在上例中,(fail)是全部指向(0)节点的),而是通过构造(fail)边衍生出来的新的转移边。上图省略了连向(0)的点,并且满足青边的转移字符和转移到这个状态的紫边的转移字符一致。
int p[maxn][26],leaf[maxn],tot,fail[maxn];
void ins(char *str)
{
int u=0;
int len=strlen(str);
RP(i,0,len-1)
{
int c=str[i]-'a';
if(!p[u][c])
p[u][c]=++tot;
u=p[u][c];
}
++leaf[u];
}
void prefail()
{
RP(i,0,25)
if(p[0][i])
fail[p[0][i]]=0,q.push(p[0][i]);
while(!q.empty())
{
int u=q.front();q.pop();
RP(i,0,25)
{
if(p[u][i])
fail[p[u][i]]=p[fail[u]][i],q.push(p[u][i]);
else
p[u][i]=p[fail[u]][i];
}
}
}
int query(char *str)
{
int len=strlen(str);
int r=0,ans=0;
RP(i,0,len-1)
{
int c=str[i]-'a';
r=p[r][c];
for(register int t=r;t&&~leaf[t];t=fail[t])
ans+=leaf[t],leaf[t]=-1;
}
return ans;
}