目录
一.函数的概述
- 函数的理解与定义
- 函数的使用及调用过程
- 函数的参数传递
- 函数的返回值
- 局部变量和全局变量
- lambda函
二.函数的理解与定义
天天向上
代码:
def dayUp(df):
dayup = 1
for i in range(365):
if i % 7 in [6, 0]:
dayup = dayup * (1 - 0.01)
else:
dayup = dayup * (1 + df)
return dayup
dayfactor = 0.01
while dayUp(dayfactor) < 37.78:
dayfactor += 0.001
print("工作日的努力参数是:{:.3f} ".format(dayfactor))
效果:

2.1 函数的定义
函数是一段代码的表示
- 函数是一段具有特定功能的、可重用的语句组
- 函数是一种功能的抽象,一般函数表达特定功能
- 两个作用:降低编程难度 和 代码复用
def <函数名>(<参数(0个或多个)>) :
<函数体>
return <返回值>
y = f(x)
- 函数定义时,所指定的参数是一种占位符
- 函数定义后,如果不经过调用,不会被执行
- 函数定义时,参数是输入、函数体是处理、结果是输出 (IPO)
三. 函数的调用及使用过程
3.1函数的调用
调用是运行函数代码的方式
def fact(n): # 函数的定义
s = 1
for i in range(1,n+1):
s *= i
return s
fact(10) # 函数的调用
- 调用时要给出实际参数
- 实际参数替换定义中的参数
- 函数调用后得到返回值
3.2 函数的调用过程

函数可以有参数,也可以没有,但必须保留括号
def <函数名>(<非可选参数>,<可选参数>) :
<函数体>
return <返回值>
- 实例一(普通调用):
代码:
def get_pi(num):
import random
count = 0
for i in range(num):
x, y = random.random(), random.random()
dist = pow((x - 0) ** 2 + (y - 0) ** 2, 0.5)
if dist < 1:
count += 1
print(4 * count / num)
get_pi(10)
get_pi(100)
get_pi(1000)
get_pi(10000)
get_pi(100000)
效果: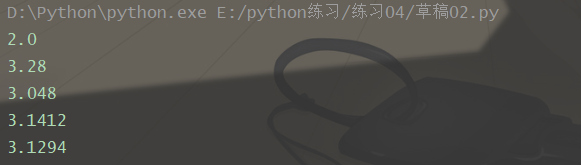
- 实例二(带返回值):
代码:
def add_sum(num):
count = 0
for i in range(1, num):
count += i
return count
res1= add_sum(101)
print('res1:',res1)
res2 = add_sum(1001)
print('res2:',res2)
res3 = add_sum(10001)
print('res3:',res3)
效果:

四.集合类型
4.1 去重
代码:
# 大括号内用逗号隔开多个元素,集合(哈希表)是无序的,去重
s1 = {'nick', 'handsome', 'wuhao', 'dsb', 1231, 1.0, 1.0, 1.0, 'dsb', 'dsb'}
print(s1)
效果:

4.2 将序列装换成为集合
s2 = set('nick')
s3 = set(['1', 2, 3])
print(s2)
print(s3)
效果:

4.3 集合的内置方法
代码:
s1 = {'luowenxiang', 'handsome', 'hanye', 'beautiful'}
s2 = {'luowenxiang', 'handsome', 'hanye', 'beautiful','0.0','haha'}
s3 = {'520','1314'}
s1.add('5201314')
s2.remove('0.0')
print(s1)
print(s2)
s2.discard('haha')
print(s2)
s3.clear()
print(s3)
s4 = s1.copy()
print(s4)
效果:
五.序列
5.1 序列的类型及定义
序列是具有先后关系的一组元素
- 序列是一维元素向量,元素类型可以不同
- 类似数学元素序列:0,1,2,3,4,5,6,7,8,9
- 元素间由序号引导,通过下标访问序列的特定元素0,1,2,3,......
5.2序列处理函数及方法
代码:
name = 'luowenxiang'
#0123456789...
name2 = name[6:] #切片 从第七个元素开始输出到最后一个元素
name3 = name[0] #索引 输出第一个元素
name4 = name2 + name3 #s + t 连接两个序列s和t
name5 = name*5 # sn 或 ns 将序列s复制n次
print('len(name):',len(name)) # 长度
print('l' in name) # x in s 如果x是序列s的元素,返回True,否则返回False
print('l' not in name) # x not in s 如果x是序列s的元素,返回False,否则返回True
print(name2)
print(name3)
print(name4)
print(name5)
效果:

六.基本统计值计算
6.1 问题分析
基本统计值
- 需求:给出一组数,对它们有个概要理解
- 该怎么做呢?
总个数、求和、平均值、方差、中位数…
- 总个数:len()
- 求和:for … in
- 平均值:求和/总个数
- 方差:各数据与平均数差的平方的和的平均数
- 中位数:排序,然后…
- 奇数找中间1个,偶数找中间2个取平均
6.2 实例讲解
通过用户输入一组数据(用户一个一个输入),然后计算数据的中位数/平均值/方差/求和
代码:
# 通过用户输入一组数据(用户一个一个输入),然后计算数据的中位数/平均值/方差/求和
#输入数据
nums = []
while True:
num1 = input('请输入你需要输入的数字(输入 q 退出):')
if num1 == 'q':
break
nums.append(int(num1))
#定义中位数
def get_median(nums):
nums.sort()
nums_len = len(nums)
if nums_len % 2 == 0:
print((nums[int(nums_len / 2 - 1)] + nums[int(nums_len / 2)]) / 2)
else:
print(nums[nums_len // 2])
median = get_median(nums) #输出中间数
#定义求和
def get_sum(nums): # ['123', '123', '213', '234', '98234']
count = 0
for i in nums:
count += int(i)
return count
count = get_sum(nums)
print('count:',count) #输出求和数据
#定义平均数
def get_average(nums):
count = get_sum(nums)
average_count = count/len(nums)
return average_count
average_count = get_average(nums)
print('average_count:',average_count) #输出平均数
#定义方差
def get_variance(nums):
average_count = get_average(nums)
variance_count = 0
for i in nums:
variance_count += pow(i-average_count,2)
return variance_count
variance_count = get_variance(nums)
print('variance_count:',variance_count) #输出方差
效果:

七.字典
7.1字典的创建与输出
代码:
dic1 = {'name':'lwx','lover':'hanye','time':'forever'}
#'键' :'值' #创建一个字典
print(dic1) #输出字典
print(dic1['name']) #输出键:name中的值
print(dic1['lover']) #输出键:lover中的值
print(dic1.get('time')) #输出键:time中的值
效果:

7.2其他操作
代码:
dic1 = {'name':'lwx','lover':'hanye','time':'forever'}
for i in dic1: #输出键
print(i)
for i in dic1.values(): #输出值
print(i)
for i in dic1.items(): #输出键和值
print(i)
dic1.pop('time') #删除操作
print(dic1)
dic1.setdefault('long','1314') #增加数据操作
print(dic1)
效果:

八.jieba库
代码:
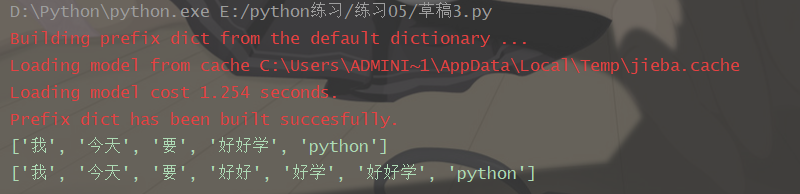
import jieba
a= jieba.lcut('我今天要好好学python')
print(a)
b = jieba.lcut_for_search('我今天要好好学python')
print(b)
效果:
作者:罗文祥
来源:祥SHAO
原文:https://www.cnblogs.com/LWX-YEER/p/11209387.html
版权声明:本文为博主原创文章,转载请附上博文链接!