查找:
静态查找:集合中记录是固定的
没有插入和删除操作,只有查找
动态查找:集合中记录是动态变化的
除查找,还可能发生插入和删除
方法1:顺序查找
typedef struct LNode *List; struct LNode{ ElementType Element[MAXSIZE]; int Length; }; int SequentianlSerach(List Tb1,ElementType K) { //在Element[1]~Element[n]中查找关键字为K的数据元素 int i; Tb1->Element[0] = k; //建立哨兵 for(i = Tb1->Length;Tb1->Element[i]!=K;i--); return i; //查找成功返回所在单元小标;不成功返回0 }
方法二:二分查找。
from unittest.mock import right int BinarySearch(List Tbl ,ElementType K) { //在表Tbl中查找关键字为K的数据元素 int left ,right,mid,NoFound=-1; left = 1; //初始化左边界 right = Tbl->Length; //初始化右边界 whlie(left <= right) { mid = (left+right)/2; //计算中间元素坐标 if( K < Tbl->Element[mid]) right = mid-1; //调整右边界 else if(K > Tbl->Element[mid]) left = mid+1; //调整左边界 else return mid; //查找成功,返回数据元素的下标 } return NotFound; //查找不成功,返回-1 }
二分查找判定树:
- 判定树上每个结点需要的查找次数刚好为该结点所在层数;
- 查找成功时查找次数不会超过判定树的深度
- n个结点的判定树的深度为[log2 n]+1
树的定义、
树(tree):n(n>20)个结点构成的有限集合。
当n=0时 称为空树;
对于任一非空树(n>0),它具备以下性质:
- 树中有一个称为“根(Root)”的特殊结点,用r表示;
- 其余结点可分为m(m>0)个互不相交的有限集T1,T2,...,Tm,其中每个集合本身又是一棵树,称为原来树的“子树(SubTree)”
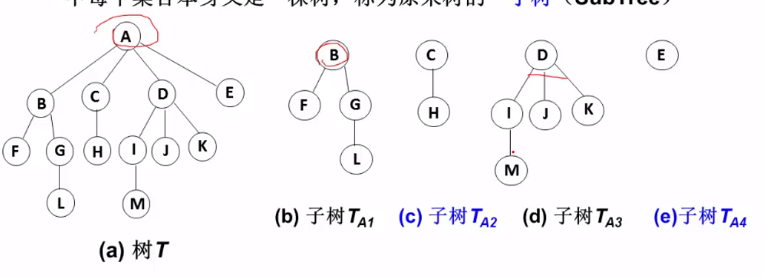
树与非树?
- 子树是不相交的;
- 除了根结点外,每个结点有且仅有一个父结点;
- 一棵树N个结点的树有N-1条边。
- 有一个m棵树的集合(也叫森林)共有k条边,则这m棵树共有k+m个结点
树的一些基本术语:
- 结点的度(Degree):结点的子树个数
- 树的度:树的所有结点中最大的度数
- 叶结点(Leaf):度为0的结点
- 父结点(Parent):有子树的结点是其子树的根结点的父结点
- 子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点/
- 兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点。
- 路径和路径长度:从结点n1到nk 的路径为一个结点序列n1,n2,...nk ,ni是ni+1 的父结点。路径所包含边的个数为路径的长度
- 祖先结点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点
- 子孙节点(Descendant):某一结点的子树中的所有结点是这个结点的子孙。
- 结点的层次(Level):规定根结点在1层,其它任一结点的层数是其父结点的层数加1.((
- 树的深度(Depth):树中所有结点中的最大层次是这颗树的深度。
树的表示:
儿子—兄弟表示法:

二叉树的定义
二叉树T:一个有穷的结点集合。
这个集合可以为空。
若不为空,则它是由根结点和称为其左子树TL 和右子树TR的两个不相交的二叉树组成。
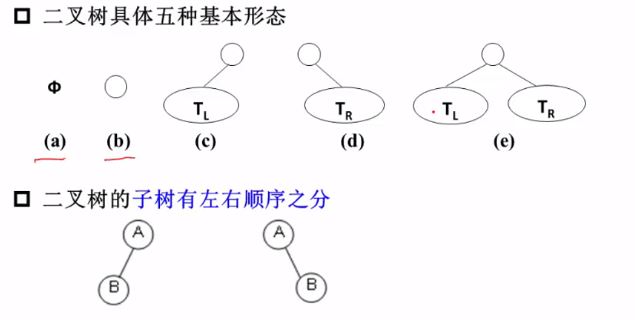

两个儿子的结点数+叶结点数=一个儿子的结点数+1;
二叉树的抽象数据类型定义
类型名称:二叉树
数据对象集:一个有穷的结点集合。
若不为空,则由根结点和其左、右二叉子树组成。
操作集:BT € BinTree,Item € ElementType,重要操作有:
- Boolean IsEmpty(BinTree BT):判别BT是否为空;
- void Traversal(BinTree BT):遍历,按某顺序访问每个结点;
- BinTree CreatBinTree():创建一个二叉树。
常用的遍历方法有:
- void PreOrderTraversal(Bintree BT):先序---根、左子树、右子树;
- void lnOrderTraversal(Bintree BT):中序---左子树、根、右子树;
- void PostOrderTraversal(Bintree BT):后序---左子树、右子树、根;
- void LevelOrderTraversal(Bintree BT):层次遍历,从上到下、从左到右
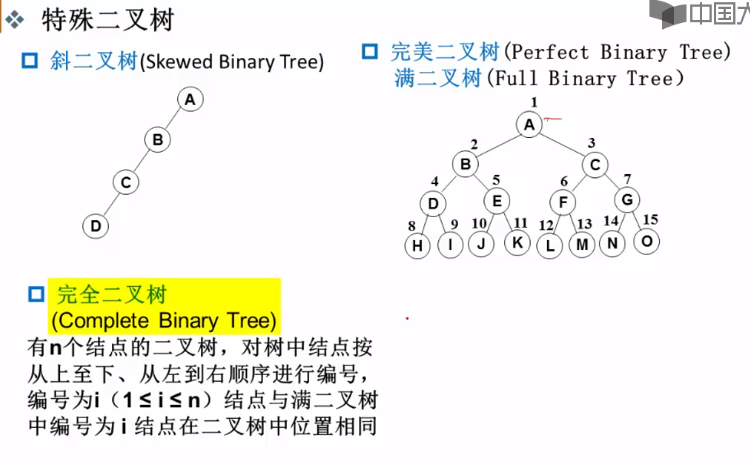
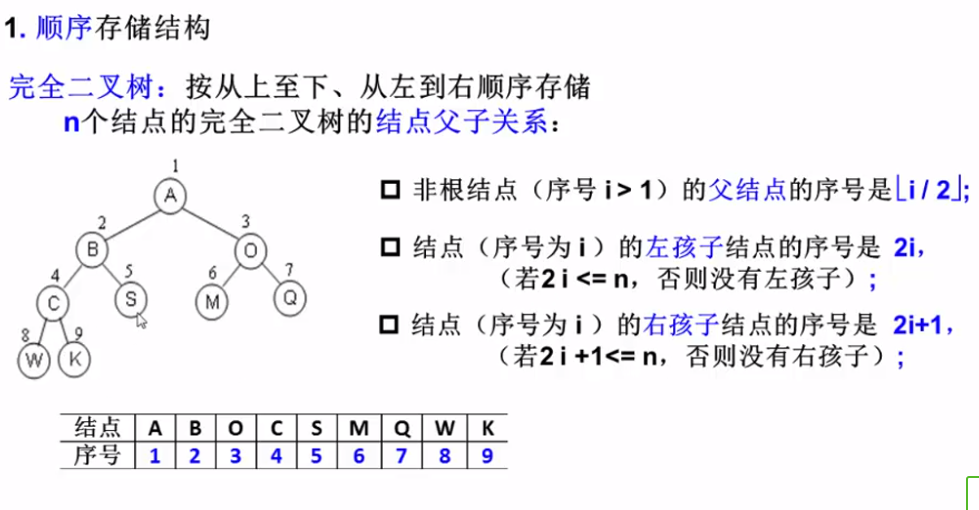
二叉树的存储结构
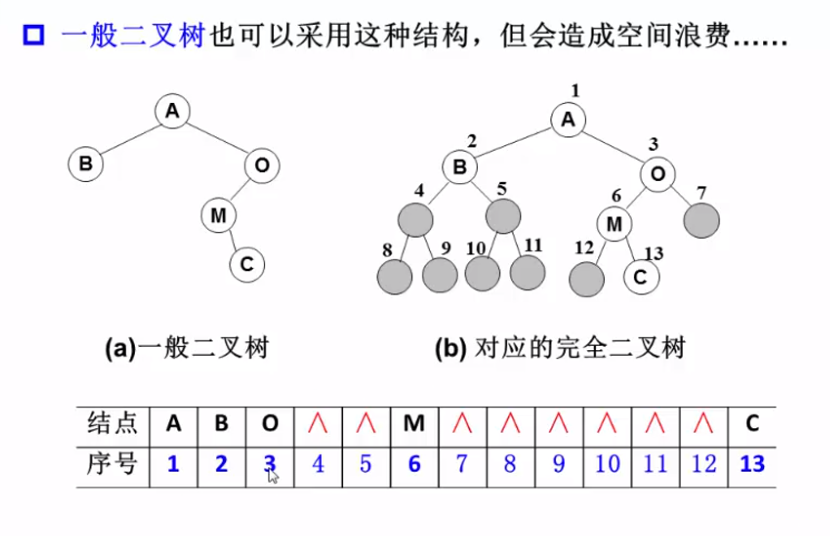
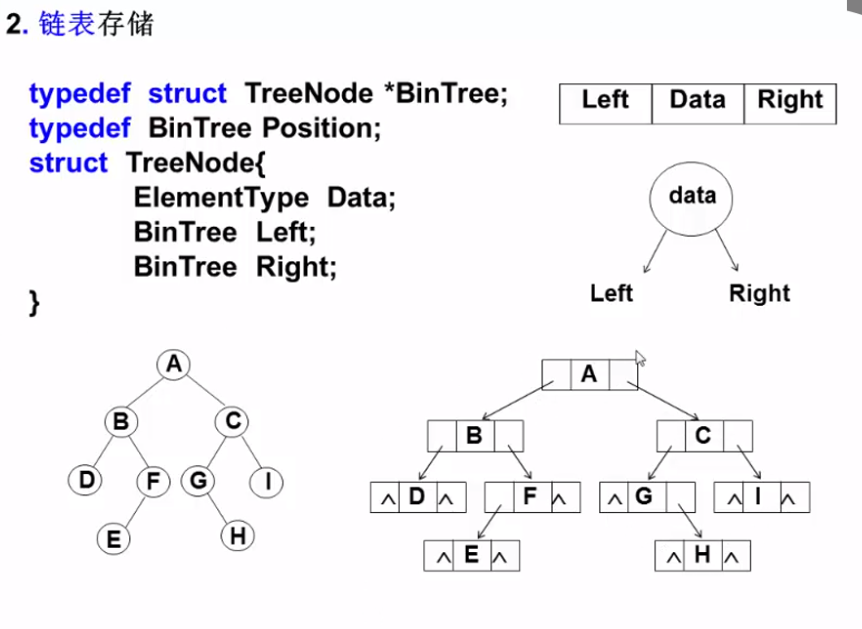
二叉树的遍历
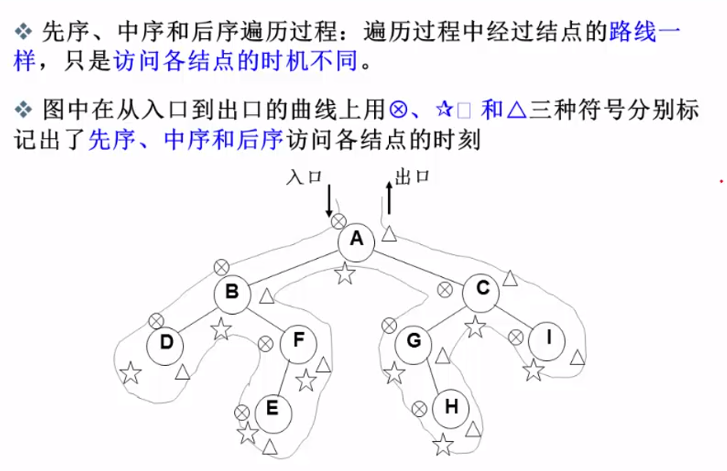
(1)先序遍历
遍历过程为:
- 访问根结点;
- 先序遍历其左子树;
- 先序遍历其右子树。
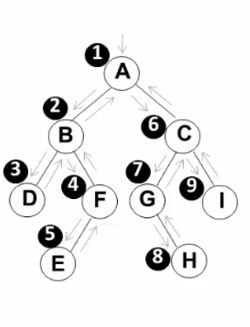
顺序:A B D F E
void PreOrderTraversal(BinTree BT) { if(BT){ printf("%d",BT->Data); PreOrderTraversal( BT->Left ); PreOrderTraversal( BT->Right ); } }
(2)中序遍历
遍历过程为:
- 中序遍历其左子树;
- 访问根结点;
- 中序遍历其右子树。
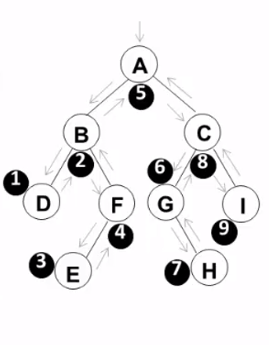
顺序:D B E F A G H C I
void InOrderTraversal( BinTree BT ) { if( BT ) { InOrderTraversal( BT->Left ); printf("%d", BT->Data); InOrderTraversal( BT->Right ); } }
(3)后序遍历
遍历过程为:
- 后序遍历其左子树;
- 后序遍历其右子树;
- 访问根结点。
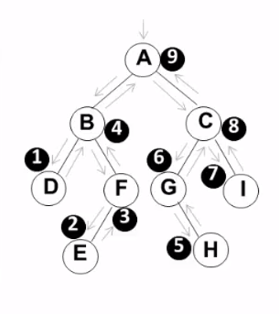
后序遍历:D E F B H G I C A
void PostOrderTraversal(BinTree BT) { if( BT ){ PostOrderTraversal( BT->Left ); PostOrderTraversal( BT->Right ); printf("%d",BT-Data); } }
中序遍历非递归遍历算法
- 遇到一个结点,就把它压栈,并去遍历它的左子树;
- 当左子树遍历结束后,从栈顶弹出这个结点并访问它;
- 然后按其右指针再去中序遍历该结点的右子树。
void InOrderTraversal( BinTree BT ) { BinTree T = BT; stack S = CreatStack( MaxSize ); /*创建并初始化堆栈S*/ while( T || !IsEmpty(S) ){ while(T){ /*一直向左并将沿途结点压入堆栈*/ Push(S,T); T = T->Left; } if(!IsEmpty(S)){ T = Pop(S); /*结点弹出堆栈*/ printf("%5d",T->Data); /*(访问)打印结点*/ T = T->Right; /*转向右子树*/ } } }
先序遍历的非递归遍历算法:
void InOrderTraversal( BinTree BT ) { BinTree T = BT; stack S = CreatStack( MaxSize ); /*创建并初始化堆栈S*/ while( T || !IsEmpty(S) ){ while(T){ /*一直向左并将沿途结点压入堆栈*/ Push(S,T); printf("%5d",T->Data); /*(访问)打印结点*/ T = T->Left; } if(!IsEmpty(S)){ T = Pop(S); /*结点弹出堆栈*/ T = T->Right; /*转向右子树*/ } } }