前言.........
Actor模型作为Akka中最核心的概念,所以Actor在Akka中的组织结构是至关重要,本文主要介绍Akka中Actor系统。
1.Actor系统
Actor作为一种封装状态和行为的对象,总是需要一个系统去统一的组织和管理它们,在Akka中即为ActorSystem,其实这非常容易理解,好比一个公司,每个员工都可以看成一个Actor,它们有自己的职位和职责,但是我们需要把员工集合起来,统一进行管理和分配任务,所以我们需要一个相应的系统进行管理,好比这里的ActorSystem对Actor进行管理一样。
2.ActorSystem的主要功能
ActorSystem主要有以下三个功能:
- 管理调度服务
- 配置相关参数
- 日志功能
2.1.管理调度服务
ActorSystem的的精髓在于将任务分拆,直到一个任务小到可以被完整处理,然后将其委托给Actor进行处理,所以ActorSystem最核心的一个功能就是管理和调度整个系统的运行,好比一个公司的管理者,他需要制定整个公司的发展计划,还需要将工作分配给相应的工作人员去完成,保障整个公司的正确运转,其实这里也体现了软件设计中的分而治之,Actor中的核心思想也是这样。
ActorSystem模型例子:
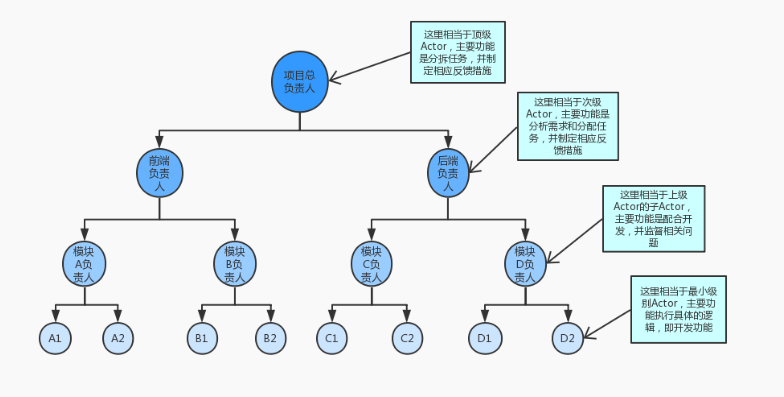
上图是一个简单的开发协作的过程,我觉得这个例子应该可以清晰的表达Akka中Actor的组织结构,当然不仅于此。主要有以下几个特点:
- Akka中Actor的组织是一种树形结构
- 每个Actor都有父级,有可能有子级当然也可能没有
- 父级Actor给其子级Actor分配资源,任务,并管理其的生命状态(监管和监控)
Actor系统往往有成千上万个Actor,使用树形机构来组织管理Actor是非常适合的。
而且Akka天生就是分布式,你可以向一个远程的Actor发送消息,但你需要知道这个Actor的具体位置在哪,这时候你就会发现,树形结构对于确定一个Actor的路径来说是非常有利(比如Linux的文件存储),所以我觉得Actor用树形结构组织可以说是再完美不过了。
2.2.根据配置创建环境
一个完善的ActorSystem必须有相关的配置信息,比如使用的日志管理,不同环境打印的日志级别,拦截器,邮箱等等,Akka使用Typesafe配置库,这是一个非常强大的配置库,后续我也准备写一篇后续文章,大家尽请期待哈。
下面用一个简单的例子来说明一下ActorSystem会根据配置文件内容去生成相应的Actor系统环境:
1.首先我们按照默认配置打印一下系统的日志级别,搭建Akka环境请看我上一篇文章:Akka系列(一):Akka简介与Actor模型
val actorSystem = ActorSystem("robot-system")
println(s"the ActorSystem logLevel is ${actorSystem.settings.LogLevel}")
运行结果:
the ActorSystem logLevel is INFO
可以看出ActorSystem默认的日志输出级别是INFO。
2.现在我们在application.conf里配置日志的输出级别:
akka { # Log level used by the configured loggers (see "loggers") as soon # as they have been started; before that, see "stdout-loglevel" # Options: OFF, ERROR, WARNING, INFO, DEBUG loglevel = "DEBUG" }
运行结果:
[DEBUG] [03/26/2017 12:07:12.434] [main] [EventStream(akka://robot-system)] logger log1-Logging$DefaultLogger started [DEBUG] [03/26/2017 12:07:12.436] [main] [EventStream(akka://robot-system)] Default Loggers started the ActorSystem logLevel is DEBUG
可以发现我们ActorSystem的日志输出级别已经变成了DEBUG。 这里主要是演示ActorSystem可以根据配置文件的内容去加载相应的环境,并应用到整个ActorSystem中,这对于我们配置ActorSystem环境来说是非常方便的。
2.3.日志功能
有很多人可能会疑惑,日志不应该只是记录程序运行状态和排除错误的嘛,怎么在Akka中会变得至关重要,Akka拥有高容错机制,这无疑需要完善的日志记录才能使Actor出错后能及时做出相应的恢复策略,比如Akka中的持久化,具体相应的一些作用我可能会在后续写相应章节的时候提到。
3.Actor引用,路径和地址
有了上面的知识,这里了解Actor引用,路径和地址就容易多了。
3.1.什么时Actor引用?
Actor引用是ActorRef的子类,每个Actor有唯一的ActorRef,Actor引用可以看成是Actor的代理,与Actor打交道都需要通过Actor引用,Actor引用可以帮对应Actor发送消息,也可以接收消息,向Actor发送消息其实是将消息发送到Actor对应的引用上,再由它将消息投寄到具体Actor的信箱中,所以ActorRef在整个Actor系统是一个非常重要的角色。
3.2.如何获得Actor引用?
- 直接创建Actor
- 查找已经存在的Actor
3.2.1.获得ActorRef
看我上一篇文章的同学对这种方式获得Actor引用应该是比较了解,这里我会具体演示一下获得ActorRef的几种方式:
假定现在由这么一个场景:老板嗅到了市场上的一个商机,准备开启一个新项目,他将要求传达给了经理,经理根据相应的需求,来安排适合的的员工进行工作。
这个例子很简单,现在我们来模拟一下这个场景:
1.首先我们来创建一些消息:
trait Message { val content: String } case class Business(content: String) extends Message {} case class Meeting(content: String) extends Message {} case class Confirm(content: String, actorPath: ActorPath) extends Message {} case class DoAction(content: String) extends Message {} case class Done(content: String) extends Message {}
2.我们来创建一家公司,这里就是ActorSystem的化身:
val actorSystem = ActorSystem("company-system") //首先我们创建一家公司
//创建Actor得到ActorRef的一种方式,利用ActorSystem.actorOf
val bossActor = actorSystem.actorOf(Props[BossActor], "boss") //公司有一个Boss
bossActor ! Business("Fitness industry has great prospects") //从市场上观察到健身行业将会有很大的前景
3.这里我们会创建几种角色,比如上面Boss,这里我们还有Manager,Worker,让我们来看看吧:
class BossActor extends Actor { val log = Logging(context.system, this) implicit val askTimeout = Timeout(5 seconds) import context.dispatcher var taskCount = 0 def receive: Receive = { case b: Business => log.info("I must to do some thing,go,go,go!") println(self.path.address) //创建Actor得到ActorRef的另一种方式,利用ActorContext.actorOf val managerActors = (1 to 3).map(i => context.actorOf(Props[ManagerActor], s"manager${i}")) //这里我们召唤3个主管 //告诉他们开会商量大计划 managerActors foreach { _ ? Meeting("Meeting to discuss big plans") map { case c: Confirm => //为什么这里可以知道父级Actor的信息? //熟悉树结构的同学应该知道每个节点有且只有一个父节点(根节点除外) log.info(c.actorPath.parent.toString) //根据Actor路径查找已经存在的Actor获得ActorRef //这里c.actorPath是绝对路径,你也可以根据相对路径得到相应的ActorRef val manager = context.actorSelection(c.actorPath) manager ! DoAction("Do thing") } } case d: Done => { taskCount += 1 if (taskCount == 3) { log.info("the project is done, we will earn much money") context.system.terminate() } } } } class ManagerActor extends Actor { val log = Logging(context.system, this) def receive: Receive = { case m: Meeting => sender() ! Confirm("I have receive command", self.path) case d: DoAction => val workerActor = context.actorOf(Props[WorkerActor], "worker") workerActor forward d } } class WorkerActor extends Actor { val log = Logging(context.system, this) def receive: Receive = { case d: DoAction => log.info("I have receive task") sender() ! Done("I hava done work") } }
光看这段代码可能不那么容易理解,这里我会画一个流程图帮助你理解这段程序:
程序流程图:
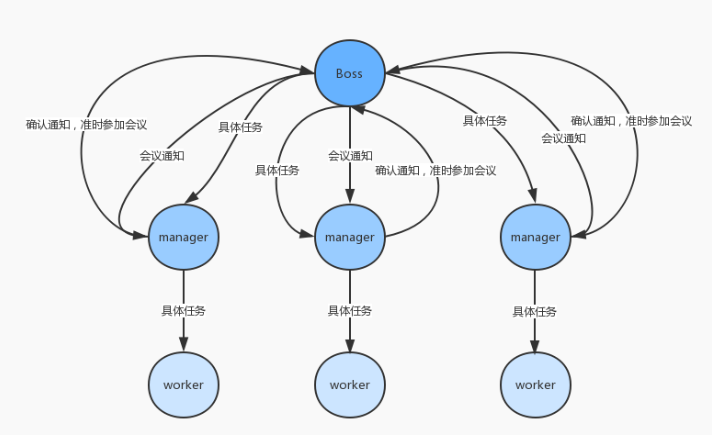
看了上面的流程图对程序应该有所了解了,过多的解释我这里就不讲解了,可以看注释,或者下载源代码自己去跑一跑。源码链接
这里主要是有两个知识点:
- 创建Actor获得ActorRef的两种方式
- 根据Actor路径获得ActorRef
前一个知识点应该比较清晰了,具体来说说第二个。
熟悉类Unix系统的同学应该对路径这个概念很熟悉了。ActorSystem中的路径也很类似,每个ActorSystem都有一个根守护者,用/表示,在根守护者下有一个名user的Actor,它是所有system.actorOf()创建的父Actor,所以我们程序中bossActor的路径为:
/user/boss
地址顾名思义是Actor所在的位置,为什么要有地址这一个概念,这就是Akka强大的理念了,Akka中所有的东西都是被设计为在分布式环境下工作的,所以我们可以向任意位置的Actor发送消息(前提你得知道它在哪),这时候地址的作用就显现出来来,首先我们可以根据地址找到Actor在什么位置,再根据路径找到具体的Actor,比如我们示例程序中bossActor,它的完整位置是
akka://company-system/user/boss
可以发现它的地址是
akka://company-system
其中akka代表纯本地的,Akka中默认远程Actor的位置一般用akka.tcp或者akka.udp开头,当然你也可以使用第三方插件,Akka的远程调用我也会专门写一篇文章。
总的来说这一篇文章主要是讲解了ActorSystem的基础结构,相关配置,以及Actor引用,路径和地址等比较基础的知识点,这其实对理解整个Actor系统是如何运行的是很有帮助的,博主也是写了好久,争取写的通俗容易理解一点,希望能得到大家的支持,下一篇准备写一下Actor的监管和监控以及它的生命周期。