Weakly Supervised Open-set Domain Adaptation by Dual-domain Collaboration笔记
方法概述
在现实世界中,经常存在这样的应用场景:两个领域都只有部分已标注的样本,而且这两个领域之间并非共享所有的类别。因此,在开放集的设定下,让部分已标注的领域相互学习,并进行每个领域中所有未标注样本的分类是有实际意义的。
Shuhan Tan等人于2019年将上述应用场景中的设定引入开集域适应,提出弱监督开集域适应问题。为了解决这一问题,作者又提出了协作分布对齐方法(Collaborative Distribution Alignment ,CDA)并取得了显著成效。
解决弱监督开放集域适应问题的一个关键挑战是当两个域中都只存在少量已标注的样本时要如何进行域适应。为了应对这一挑战,协作分布对齐开集域适应使用了一种新的双重映射方法来学习每个域特定的特征变换,进而迭代地将两个域的特征空间映射到一个共享的潜在空间。为了减轻目标域私有标签空间中样本的影响,在双重映射的优化过程中,该方法最大化共享标签空间和私有标签空间中样本的边界,同时最小化特征分布差异和类内变化。此外,为了提高对属于私有标签空间的样本的分辨能力,该方法对未标注的样本进行伪标签预测来扩大标签集,这些样本由信息熵进一步选择并用于双重映射的优化。最后当两个域在共享潜在空间中对齐后,再使用两个域中的已标注样本学习一个分类器。
该方法的主要贡献在于:
1.提出弱监督开放集域适应的设定,它允许只存在部分已标注样本的两个域之间通过相互学习对未标注的样本进行标注。此设定将域适应的限制扩展到缺少理想源域的情况。
2.提出协作分布对齐的方法来解决所提出的问题,该方法能够较好地处理由弱监督和开放集设定而引入的挑战。
方法流程
协作分布对齐的方法假设有源域(D_s)和目标域(D_t),它们都只有部分已标注的样本,而且源域中未标注样本所对应的类别可能并不在源域的标签空间中而是在目标域的标签空间中,所以该方法将源域与目标域的标签集(C_s,C_T)汇总为(C_L),将源域与目标域中的未标注样本一起进行标注。
该方法流程如图5-2-2-6所示,在(a)中,已标注的样本用实心图形表示,未标注的样本用空心图形表示。不同类别的样本分别由圆形、三角形、矩形和菱形来表示,其中圆形表示私有标签空间的样本。
在(b)中,为一些未标注的样本分配伪标签,同时分离属于私有标签空间的样本。其中分配的伪标签由图中空心图形中的实心图形表示。
在(c)中,学习一组特定于两个域的映射,这些映射将样本变换到一个潜在的领域中,减少了域间差异,聚集属于同一类别的样本,从而形成共享标签空间样本和私有标签空间样本间的边界。然后,使用变换后的特征来更新(b)中的伪标签,并在(b)和(c)之间迭代,直到收敛。
最后,在(d)所示的潜在空间中,使用分类器来标注所有未标注的样本。

伪标签分配
为了扩大标签集,该方法通过迭代优化的方法在(C_L)上训练分类器来生成源域与目标域中未标注样本集(U_s)与(U_t)的伪标签。首先为(U_s,U_t)中的样本分配伪标签,之后使用估计的伪标签和已标注的样本来优化更新伪标签,再使用更新后的标签开始新的迭代,直到最后收敛。但是由于域间差异的存在,其中的一些伪标签是不准确的,这将导致最终的预测错误。为了避免错误的迭代传播,在优化伪标签的过程中需要判断标签的准确性,以消除不正确的标签。
由于之前在(C_L)上训练的分类器已经获得了每个样本的概率分布估计,该方法提出利用信息熵H来估计每个样本预测的准确性。H较高,表示样本预测为各个类别的概率相差不大,说明这个预测更有可能是错误的。(x_i)为第i个样本,C为类别总数,(Y_{ij})表示(x_i)属于类别j的概率,则信息熵的定义为 。当(H(x_i)ge gamma)时,该样本就会被认为属于私有标签空间而不再参加双重映射,(gamma)是一个自适应阈值,它的取值是所有样本信息熵的均值。
。当(H(x_i)ge gamma)时,该样本就会被认为属于私有标签空间而不再参加双重映射,(gamma)是一个自适应阈值,它的取值是所有样本信息熵的均值。
双重映射
双重映射,即通过分别学习源域和目标域的变换矩阵(W_s)与(W_t)来更好地利用这两个领域的特定信息,将(D_s)和(D_t)映射到共享的潜在空间中。由于这两个领域在该问题中扮演的角色是平等的,所以使用双重映射来学习领域间的特定变换对于解决弱监督开集域适应问题来说更加灵活。
开集的设置下的主要任务是检测和分离属于私有标签空间的样本。如果共享标签空间的样本和私有标签空间的样本之间没有很好地分离,那么二者的重叠可能会导致共享标签空间的样本被错误地分类到私有标签空间中,或者私有标签空间中的样本被分类到共享标签空间中。这将显著降低总体性能。为了使得二者更好的分离,该方法要求:与任何私有标签空间中的样本相比,每个共享标签空间中的样本要尽量接近其所属的类别中心。
对于每个共享标签空间中的样本,定义距离该样本x最近的属于私有标签空间中样本(x_u)的距离为: 其中D表示该样本x所在的域(源域或者目标域),(D')表示(x_u)所属的领域,W表示所在域的映射;定义该样本x距离它所属类别中心(overline{x}^c_D)的距离为:
其中D表示该样本x所在的域(源域或者目标域),(D')表示(x_u)所属的领域,W表示所在域的映射;定义该样本x距离它所属类别中心(overline{x}^c_D)的距离为:
将(C_K)作为共享标签空间中的类别集合,(x^c_D)作为D域中属于类别C的样本,则定义属于私有标签空间的样本从共享标签空间中分离的损失(U_D)为:

则源域与目标域的总损失为:

在最小化损失U,将属于私有标签空间的样本成功分离之后,还要将所有共享标签空间中的样本分布进行对齐,以获得更好的分类性能。为此,该方法计算变换后两区域边缘分布间的距离为
其中 表示D域共享标签空间中的样本特征的均值,(n^k_D)表示这些样本的个数。
表示D域共享标签空间中的样本特征的均值,(n^k_D)表示这些样本的个数。
同样,两区域条件分布间的距离Distc可以用两个域共享标签空间中对应类别的中心间距离之和来度量。它被定义为 其中
其中 表示D域中的类别c中的样本特征的均值,(x^{c,i}_D)表示D域中类别c的第i个参数。
表示D域中的类别c中的样本特征的均值,(x^{c,i}_D)表示D域中类别c的第i个参数。
该方法通过最小化Distm与Distc来减小两个域的共享标签空间中的样本在边缘分布和条件分布的差异,完成共享标签空间中样本分布的对齐。
为了便于进行私有标签空间样本的分离和共享标签空间中样本分布的对齐,该方法还通过定义损失(G_D)来将所有样本集合到它们各自所属的类别中心:
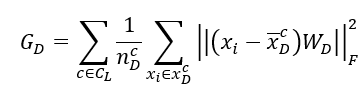
则两个域的总损失为:
通过最小化损失G,属于同一个类别的样本最终被聚集到一起。
结合上面讨论的所有部分,便可以给出总的目标函数。为了平衡方法中的各个部分,目标函数中还分别引入了针对私有标签空间样本分离、共享标签空间样本分布对齐和类别中心聚集的平衡参数(lambda_U,lambda_M,lambda_G),方法总损失函数定义为
方法总的目标函数为
性能分析
协作分布对齐开集域适应方法中,作者在Office-31数据集中随机选取15个类别作为共享类别,剩余的16类做为两个域的私有类别。源域与目标域分别随机选取10个类别作为私有类别的已标注数据,但二者共享其中的 5个类别。除了也使用之前的方法一与方法二作为实验的基线,该方法还使用了TCA[26]、GFK[27]、CORAL[28]等方法作为对比。由于该方法使用的是双向预测,对于基线中那些只需要进行单个领域标注工作的方法,为了公平起见,要使用不同来源的数据正反进行两次来与该方法进行对比。实验的结果如图5-2-3-11所示,可见该方法的识别精度较方法一、方法二又有了进一步的提升。

此外,在该方法的消融实验中,作者还探究了模型的各个部分对方法的影响,结果如图5-2-3-12所示。
