首先,下载Twisted。cp后数字为python版本,例如cp36为python3.6;amd则表示系统位数,例如amd64为64位。下载对应版本即可。点击打开链接
在cmd中输入pip install Twisted的路径,例如下载路径为F:Twisted-17.9.0-cp36-cp36m-win_amd64.whl,则输入pip install F: Twisted-17.9.0-cp36-cp36m-win_amd64.whl
1、新建爬虫项目
1.1、切换到项目文件下面
1.2、在Terminal使用srcapy startproject 爬虫项目名称。如:
scrapy startproject Python32000
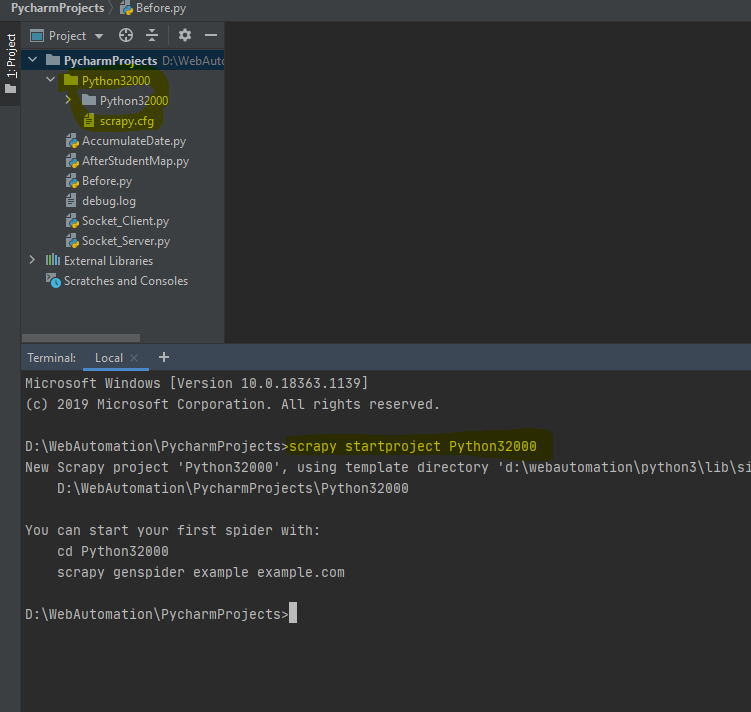
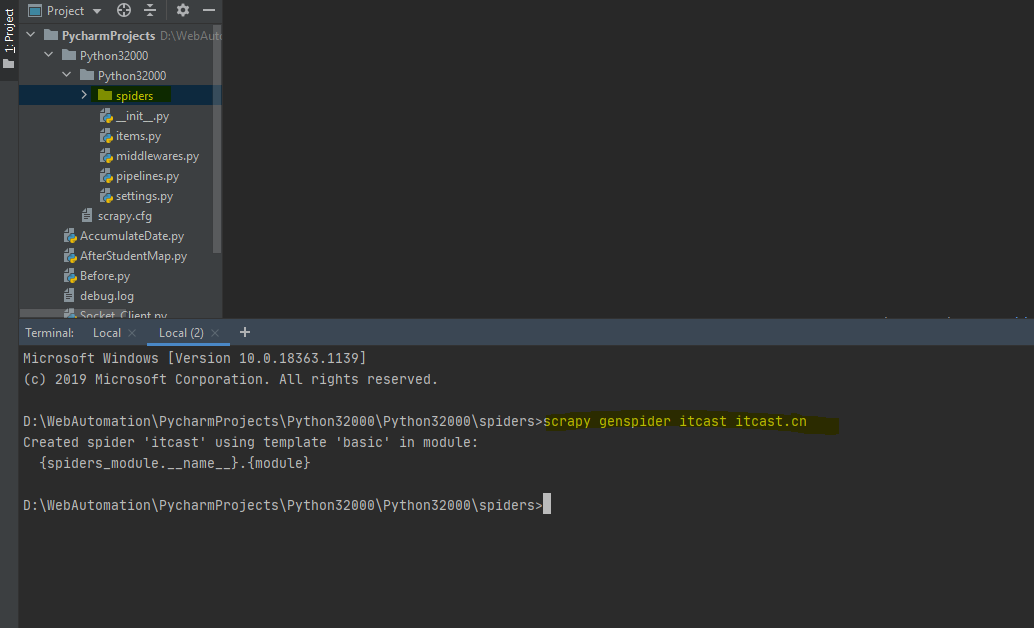
1.3、在项目中spiders新建爬虫区,scrapy genspider 爬虫名称 爬虫区域。如:scrapy genspider itcast itcast.cn
1.4、配置,先确定我们需要爬虫爬的数据参数,在items.py下面配置你需要的参数。items。
class Day2Item(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
到spiders文件下面的itcast,实现具体爬虫代码。items。
import scrapy
from ..items import *
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = Day2Item()
# extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
# xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items
1.6、运行爬虫scrapy crawl 爬虫名称。如:scrapy crawl itcast。