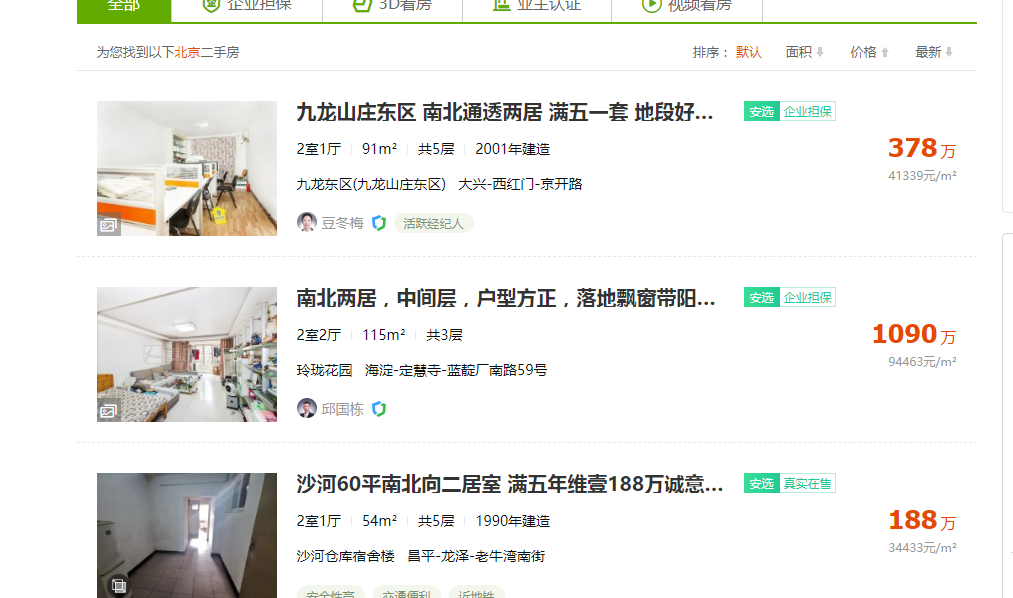
爬取的目标网站:
code
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests from lxml import etree class Main: def __init__(self): self.headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } self.url = "https://beijing.anjuke.com/sale/?pi=baidu-cpc-bj-tyong1&kwid=2341817153&utm_term=%e6%89%be%e6%88%bf&bd_vid=9128294385511928514" def lord(self): response = requests.get(url=self.url, headers=self.headers).text tree = etree.HTML(response) # 将页面源码数据中的房子的名称和价格进行爬取 li_list = tree.xpath('//ul[@class="houselist-mod houselist-mod-new"]/li') # 将li标签表示的局部页面内容指定数据进行解析 for li in li_list: title = li.xpath('./div[2]/div[1]/a/text()')[0].strip() describe = li.xpath('./div[2]/div[2]/span/text()') site = li.xpath('./div[2]/div[3]/span/text()')[0].split()[1] price = li.xpath('./div[3]/span[1]/strong/text()') print('标题:{} 描述:{} 地点:{} 价格{}万 '.format(title, describe, site, price)) with open('date.txt','a+',encoding='utf-8') as f1: f1.write('标题:{} 描述:{} 地点:{} 价格{}万 '.format(title, describe, site, price)) f1.close() if __name__ == '__main__': obj = Main() obj.lord()
输出结果
