介绍
Swarm 在 Docker 1.12 版本之前属于一个独立的项目,在 Docker 1.12 版本发布之后,该项目合并到了 Docker 中,成为 Docker 的一个子命令。目前,Swarm 是 Docker 社区提供的唯一一个原生支持 Docker 集群管理的工具。它可以把多个 Docker 主机组成的系统转换为单一的虚拟 Docker 主机,使得容器可以组成跨主机的子网网络。
Swarm 是目前 Docker 官方唯一指定(绑定)的集群管理工具。Docker 1.12 内嵌了 swarm mode 集群管理模式。
Swarm 关键概念
1)Swarm
集群的管理和编排是使用嵌入到 docker 引擎的 SwarmKit,可以在 docker 初始化时启动 swarm 模式或者加入已存在的 swarm
2)Node
一个节点(node)是已加入到 swarm 的 Docker 引擎的实例 当部署应用到集群,你将会提交服务定义到管理节点,接着 Manager
管理节点调度任务到 worker 节点,manager 节点还执行维护集群的状态的编排和群集管理功能,worker 节点接收并执行来自
manager 节点的任务。通常,manager 节点也可以是 worker 节点,worker 节点会报告当前状态给 manager 节点
3)服务(Service)
服务是要在 worker 节点上要执行任务的定义,它在工作者节点上执行,当你创建服务的时,你需要指定容器镜像
4)任务(Task)
任务是在 docekr 容器中执行的命令,Manager 节点根据指定数量的任务副本分配任务给 worker 节点
docker swarm:集群管理,子命令有 init, join, leave, update。(docker swarm –help 查看帮助)
docker service:服务创建,子命令有 create, inspect, update, remove, tasks。(docker service–help 查看帮助)
docker node:节点管理,子命令有 accept, promote, demote, inspect, update, tasks, ls, rm。(docker node –help 查看帮助)
node 是加入到 swarm 集群中的一个 docker 引擎实体,可以在一台物理机上运行多个 node,node 分为:manager nodes管理节点,worker nodes工作节点。
一、系统环境
1)服务器环境
| 节点名称 | IP | 操作系统 | 内核版本 |
| manager | 172.16.60.95 | CentOs7 | 4.16.1-1.el7.elrepo.x86_64 |
| node-01 | 172.16.60.96 | CentOs7 | 4.16.1-1.el7.elrepo.x86_64 |
| node-02 | 172.16.60.97 | CentOs7 | 4.16.1-1.el7.elrepo.x86_64 |
| node-03 | 172.16.60.98 | CentOs7 | 4.16.1-1.el7.elrepo.x86_64 |
2)前提条件
- Docker版本1.12+
- 集群节点之间保证TCP 2377、TCP/UDP 7946和UDP 4789端口通信
TCP端口2377集群管理端口
TCP与UDP端口7946节点之间通讯端口
TCP与UDP端口4789 overlay网络通讯端口
二、集群部署
1)master创建Swarm(要保存初始化后token,因为在节点加入时要使用token作为通讯的密钥)
|
1
2
3
4
5
6
7
8
|
[root@master ~]# docker swarm init --advertise-addr 172.16.60.95Swarm initialized: current node (kfi2r4dw6895z5yvhlbyzfck6) is now a manager.To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-3fzyz5knfbhw9iqlzxhb6dmzdtr0izno9nr7iqc5wid09uglh8-0mocmawzvm3xge6s37n5a48fw 172.16.60.95:2377To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions. |
注:上面命令执行后,该机器自动加入到swarm集群。这个会创建一个集群token,获取全球唯一的 token,作为集群唯一标识。后续将其他节点加入集群都会用到这个token值。 其中,--advertise-addr参数表示其它swarm中的worker节点使用此ip地址与manager联系。命令的输出包含了其它节点如何加入集群的命令。
使用docker info 或者 docker node ls 查看集群中的相关信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
docker info.......Swarm: active NodeID: kfi2r4dw6895z5yvhlbyzfck6 Is Manager: true ClusterID: y2zgs373cg0y6559t675yexcj Managers: 1 Nodes: 1 Orchestration: Task History Retention Limit: 5....... |
2)添加节点到swarm集群中
所有节点执行
|
1
|
docker swarm join --token SWMTKN-1-3fzyz5knfbhw9iqlzxhb6dmzdtr0izno9nr7iqc5wid09uglh8-0mocmawzvm3xge6s37n5a48fw 172.16.60.95:2377 |
在master上查看集群节点的状态

到此Swarm集群就创建好了
3)docker node 命令

[root@master ~]# docker node --help
Usage: docker node COMMAND
Manage Swarm nodes
Options:
Commands:
demote Demote one or more nodes from manager in the swarm
inspect Display detailed information on one or more nodes
ls List nodes in the swarm
promote Promote one or more nodes to manager in the swarm
ps List tasks running on one or more nodes, defaults to current node
rm Remove one or more nodes from the swarm
update Update a node
# demote
将管理节点降级为普通节点
# inspect
查看节点的详细信息
# ls
列出节点
# promote
将普通节点升级为管理节点
# ps
查看运行的任务
# rm
从swarm集群中删除节点
# update
改变集群节点状态
[root@master ~]# docker node update --help
Usage: docker node update [OPTIONS] NODE
Update a node
Options:
--availability string Availability of the node ("active"|"pause"|"drain")
--label-add list Add or update a node label (key=value)
--label-rm list Remove a node label if exists
--role string Role of the node ("worker"|"manager")
# 主要使用availability string
# active
节点状态正常
# pause
节点挂起、暂停
# drain
排除节点,比如将master节点排除,不分配任务,只作为管理节点
三、在Swarm中部署服务
1)创建服务
[root@master ~]# docker service --help Usage: docker service COMMAND Manage services Options: Commands: create Create a new service inspect Display detailed information on one or more services logs Fetch the logs of a service or task ls List services ps List the tasks of one or more services rm Remove one or more services rollback Revert changes to a service's configuration scale Scale one or multiple replicated service
|
1
2
3
4
5
|
[root@master ~]# docker service create --replicas 1 --name hello busybox# --replicas : 副本集个数# --name:服务名称 |
2)查看服务信息
|
1
2
3
|
[root@master ~]# docker service lsID NAME MODE REPLICAS IMAGE PORTSkosznwn4ombx hello replicated 0/1 busybox:latest |
从REPLICAS中能看出这个 hello服务并没有启动起来,0/1 表示 1计划启动的副本数,0实际启动的数量。所以启动失败

3)添加参数
在hello服务中busybox只是一个基础镜像,并没有一个持续运行的任务,所以manager会不断重启hello这个服务,所以有好多shutdown的记录。但是可以为其添加一个任务。
|
1
2
3
4
5
6
7
8
9
10
|
[root@master ~]# docker service update --args "ping www.baidu.com" hellohellooverall progress: 1 out of 1 tasks1/1: running [==================================================>]verify: Service converged# update:更新状态# --args:增加参数 |
再次查看状态:
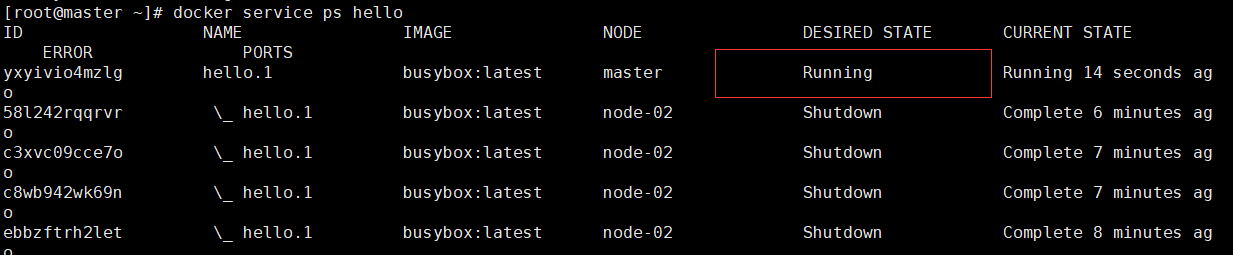
过滤不正常的状态:
|
1
2
3
4
5
6
|
[root@master ~]# docker service ps -f "desired-state=running" helloID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTSyxyivio4mzlg hello.1 busybox:latest master Running Running 4 minutes ago # -f "desired-state=running" : 状态为runngin的服务 |
4)为服务扩容(缩融)scale
刚才设置的replicas=1,可以增加副本数量
|
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@master ~]# docker service scale hello=4hello scaled to 4overall progress: 4 out of 4 tasks1/4: running 2/4: running 3/4: running 4/4: running verify: Service converged# scale : 指定服务的数量 |

5)工作节点排除manager,manager只作为管理节点
上图中manager也运行了一个服务,将manager排除在外
|
1
2
3
4
5
6
7
8
9
|
[root@manager ~]# docker node update --availability drain manager# node update : 更改节点状态# --availability : 三种状态 active: 正常 pause:挂起 drain:排除 |
排除manager后,其上面运行的服务会转移到其他节点

四、滚动更新服务
例如升级服务的镜像版本
|
1
2
3
4
5
6
7
8
9
10
|
[root@manager ~]# docker service create > --replicas 3 > --name redis > --update-delay 10s > redis:3.0.6# 启动3个副本集的redis# update-delay 10s :每个容器依次更新,间隔10s |
滚动更新:
|
1
2
3
|
docker service update --image redis:3.0.7 redis# --image : 指定版本 |
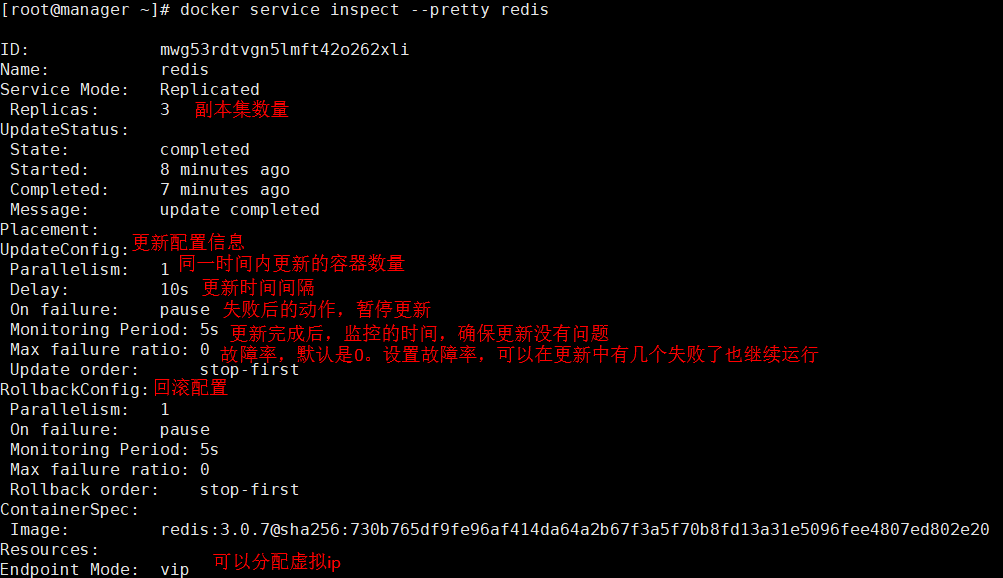
更新完成后新版本和历史记录都能查看

查看配置信息:
五、服务更新和回滚策略
1)设置策略
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
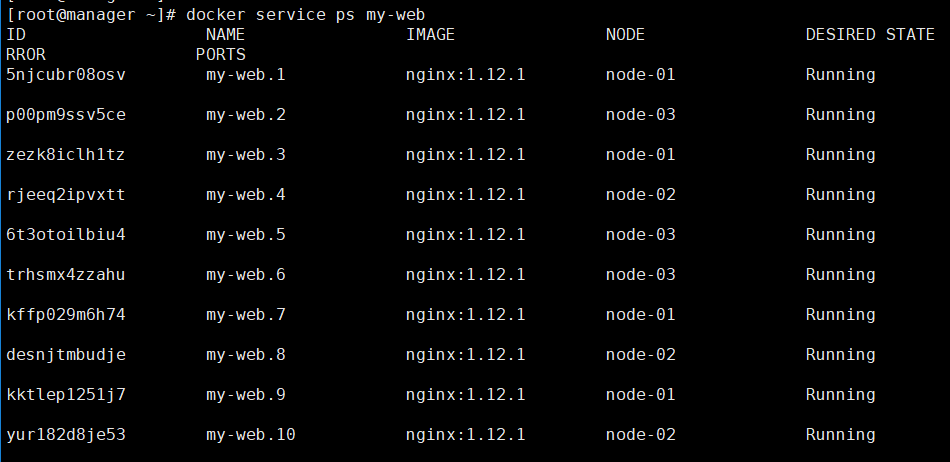
[root@manager ~]# docker service create --name my-web --replicas 10 --update-delay 10s --update-parallelism 2 --update-failure-action continue --rollback-parallelism 2 --rollback-monitor 20s --rollback-max-failure-ratio 0.2 nginx:1.12.1# --update-parallelism 2 : 每次允许两个服务一起更新#--update-failure-action continue : 更新失败后的动作是继续# --rollback-parallelism 2 : 回滚时允许两个一起# --rollback-monitor 20s :回滚监控时间20s# --rollback-max-failure-ratio 0.2 : 回滚失败率20% |
如果执行后查看状态不是设置的,可以在update一下,将服务状态设置为自己想要的
|
1
2
3
4
5
|
docker service update --rollback-monitor 20s my-webdocker service update --rollback-max-failure-ratio 0.2 my-web# 有两个地方设置数值没有成功,手动设置 |
查看状态:

2)服务更新
|
1
|
[root@manager ~]# docker service update --image nginx:1.13.5 my-web |
和上述策略一致,两两更新

更新完成:
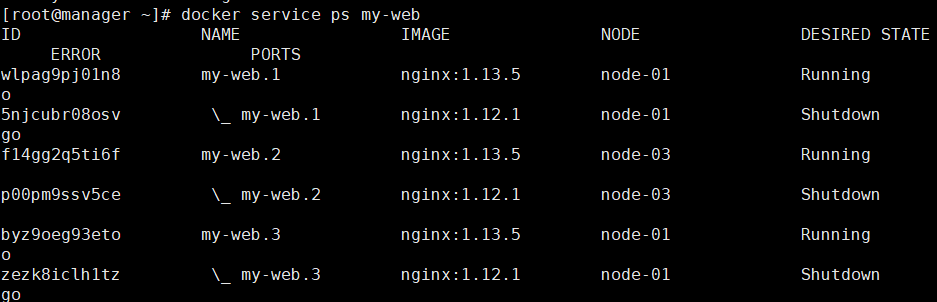
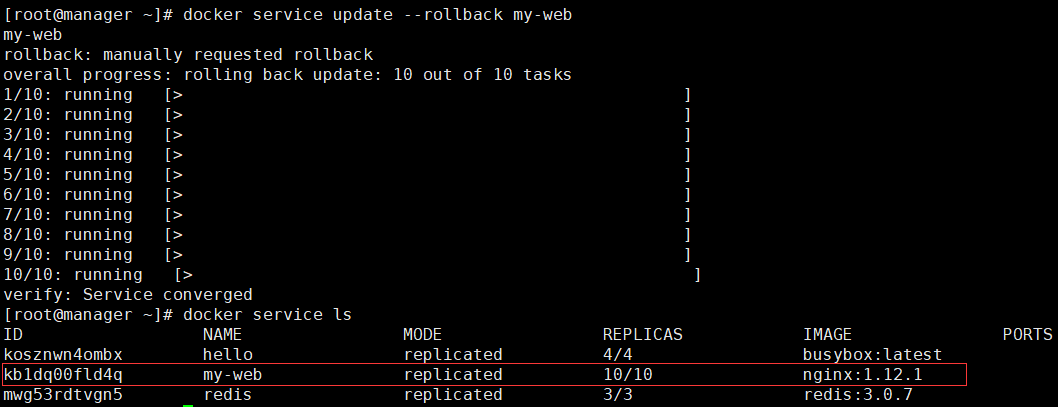
3)手动回滚(策略是失败会回滚,现在没有失败)
刚才nginx版本已经是1.13.5了,现在将其还原到1.12.1
|
1
|
[root@manager ~]# docker service update --rollback my-web |