导读:
本文为论文《Deep Mixture of Diverse Experts for Large-Scale Visual Recognition》的阅读总结。目的是做大规模图像分类(>1000类),方法是混合多个小深度网络实现更多类的分类。本文从以下五个方面来对论文做个简要整理:
背景:简要介绍与本文方法提出的背景和独特性。
方法:介绍论文使用的大体方法。
细节:介绍论文中方法涉及到的问题及解决方案。
实验:实验结果和简要分析。
总结:论文主要特色和个人体会。
一、背景
1.目标:大规模图像分类(>1000),以往做图像分类最多为1000类的分类,更多的类的区分难度比较大,也鲜有方法,以往对此问题的解决方案包括下面三种:
1)设计更复杂的网络
此类方法专门针对大规模图像分类设计深度网络,但是该方法可操作性不强,原因是网络结构设计的未知性、大量资源消耗、数据量不够大导致过拟合等。
2)网络转换
此类方法是指将在其他数据集上训练好的网络模型移植到新的数据上使用,但该方法一般是从在多类数据集上训练好的模型迁移到少类上,而以往训练的模型(<1000)类别数比较少,移植到类别大的数据集上往往效果不够好。
3)多个小CNN结合
此类方法是指,学习多个少类的神经网络,然后将多个少类神经网络结合起来,实现对多类分类的效果,该方法可以达到以更少资源取得更多分类的效果。
本文采用的分类方法为第三种多个小CNN结合的方法。
2.特色
1)与分层树区别
分层树是自顶而下的分类,且高层分类时需同时使用所有类别。
本文方法是自下而上的分类,每次训练时只需使用大类的一个子集即可。
2)与单任务多网络区别
以往也有将多个网络结合起来做混合预测的方法,但此种单任务多网络方法的每个任务空间是相同的,只是起到特征间相互弥补的作用。而本文方法的每个子网络都有自己的任务空间,有任务重叠但不重合。
因此,本文方法是独特的,即鲜有人使用的。
二、方法
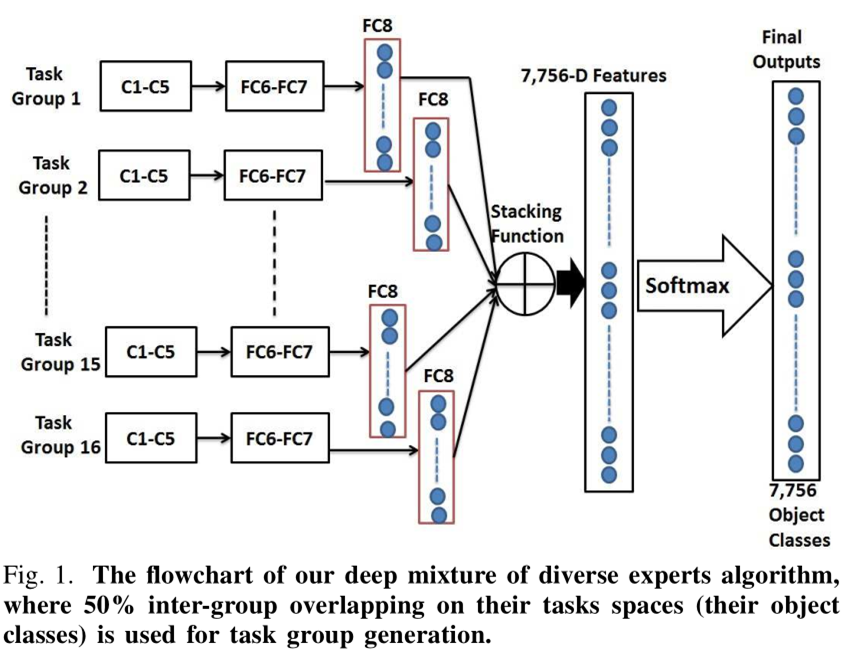
1.概述:本文采用的方法大体流程如下图
1)按语义相似度构建两层架构,同时允许组内有重叠。
2)组内用单个CNN学习分类网络以及类间相关性(称为多任务)。
3)多个组的CNN输出相结合形成混合网络并得到最终输出。
2.挑战
1)组的产生:随机分组将导致相似(学习复杂度相同)的类不在一组将难以区分。
本文的解决方法是,将相似度高的分为一组,且相似度按高低排列,从左到右依此产生组,并允许组间有重叠。
2)类间可区分性:同一组的类别相似度往往比较高,更难区分。
本文的解决方法是,多任务学习,即在学习分类网络的同时,学习类间的相似度,以增强可分性。
3)预测输出可比性:如果多个子网络间没有信息交流,那么产生的输出就没有可比性,也就不能得到最终的分类结果,而且有重叠的情况下多个组的预测结果可能产生冲突。
本文的解决方法是,在每个子网络的输出中,增加not-in-group项,即不在该子网络里的类别对应的gt为not-in-group,同时组间有重叠,从而使组间的信息可以交流。
三、细节
1.两层架构:本文方法的第一步为构建两层架构,该步骤的方法是:
1)按下面公式计算相似度矩阵并用谱聚类方法得到大类(category)

其中,ψi,j表示小类(class)i和j的相似度,D(ci,cj)表示在WordNet上从类i到j所需要经过的节点数,H表示WordNet上从根草最深类节点经过的节点数,
2)按相似度排列大类(category)形成圈。即大类间越相似,排列后的位置越靠近。
3)以一定顺序依此每次取M个小类(class)形成组(group)。
得到的组即为我们要得到的东西,即两层架构,步骤中的大类(category)仅在形成组时有用到,后续不再使用。形成组的过程如图:

2.单个CNN的学习:本文方法的第二步为单个CNN的学习,即组分类器的学习,其中涉及到的几个关键因素如下:
1)base CNN:本文采用的基础神经网络为预训练好的Alexnet。
2)优化目标:
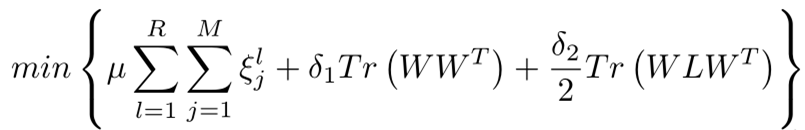
上式中,R和M分别为每类训练集的图像数和组内的类别数,ξlj表示训练错误率,符号定义为
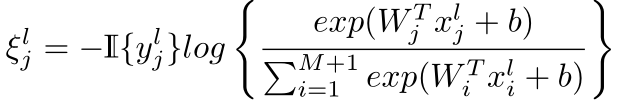
W表示网络参数,x表示深度特征,L表示类间相似度矩阵S的拉普拉斯矩阵,相似度矩阵S定义为
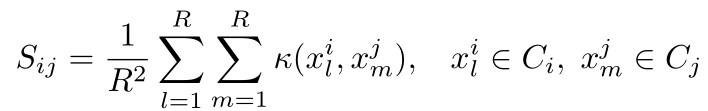
3)Loss:将上述定义带入(2)中的优化目标可导到损失函数
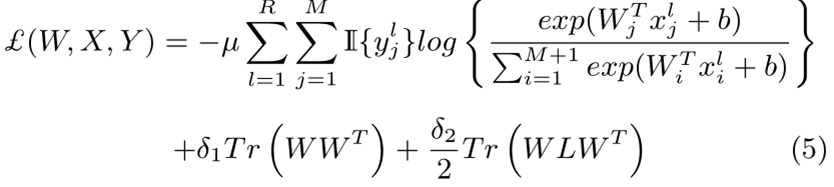
3.融合预测:本文方法的第三步为多个组预测结果的融合,其中包括以下两步
1)获得第j组第i类的输出分数为pj(ci)
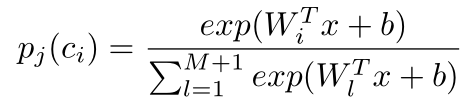
2)组内预测调整

上式中,Υ(ci)表示融合后的向量中,第i类的分数,Λj (ci)是第i个原子类在第j组的指示子,在为1不在为0,φj为第j组中not-in-group的预测分数,用于调整同组其余预测分数。即,预测为not-in-group的分数越大,那么是其他类的分数就应该越小。
在分数融合之后得到M维的向量,经过softmax层得到最终的预测输出,此处总的Loss为
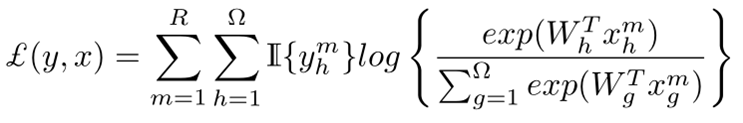
该Loss的梯度不仅用于更新融合前后网络的参数,也用于更新基础网络的参数。
四、实验
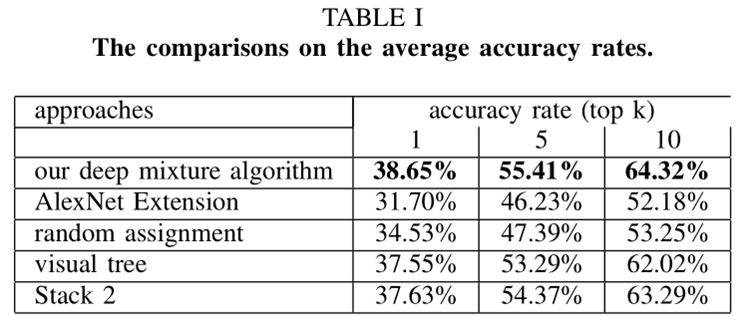
上图的第2项表示直接将Alexnet的输出层节点增加到M个,第3项表示不采用本文构建视觉树的方法直接随机分组,第4项表示采用其他论文视觉树构建方法,第5项表示预测融合时修改not-in-group对同组其他类分数的影响得到的结果。
从上图可以看出本文方法得到的结果最好。
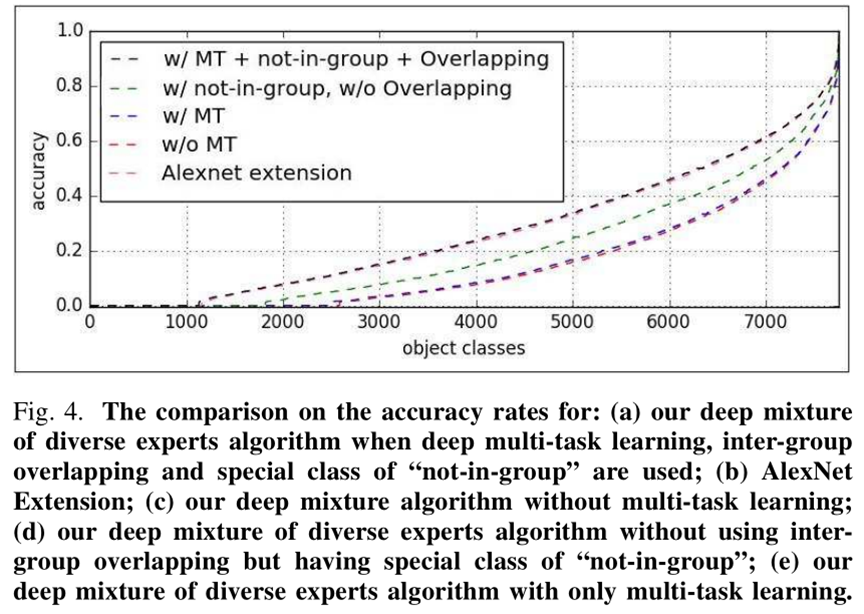
上图表示多任务学习、有没有not-in-group项、有没有overlap对本文方法的影响。
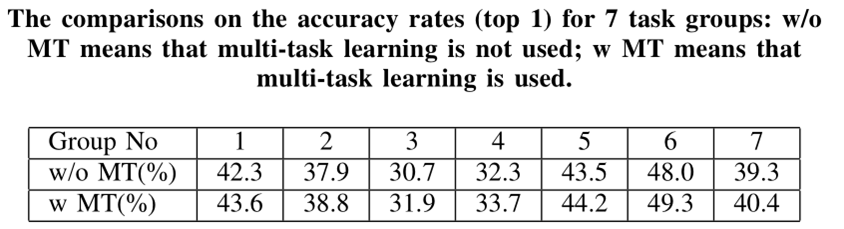
上图表示有没有多任务学习对结果的影响还是比较大的。
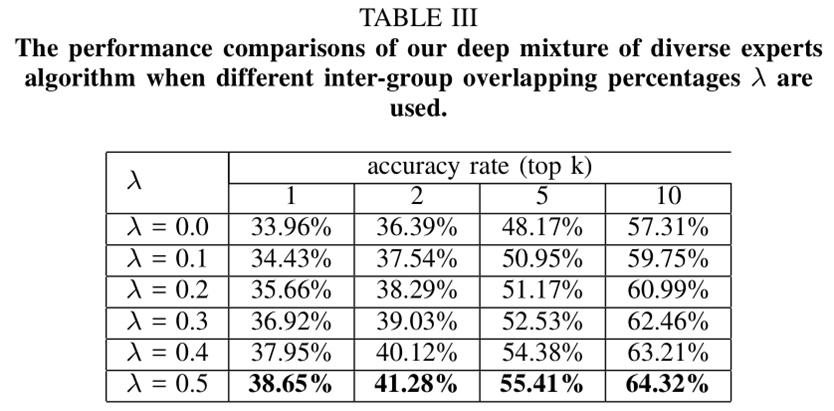
上图表示,组内重叠率越大结果越好。
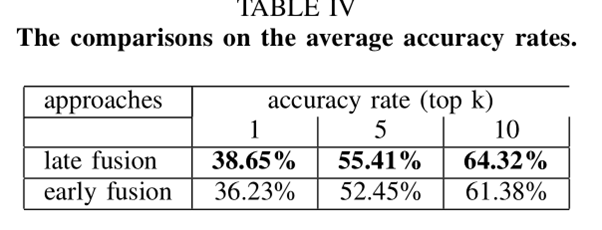
上图第1种方法表示本文采用的将FC8层预测结果融合的方法,第2种表示将FC7层特征融合的方法。

上图表示采用不同基础网络对实验结果的影响。
五、总结
1.本文的任务是创新的:以小网络解决大任。务
2.在组内Loss中加入类间相似度矩阵学习项提高可分性。
3.组内预测输出加入not-in-group项,使得组间信息可比。
4.文章最后提出组内多个基础网络融合更能提高识别结果。
5.本文方法理论简单,可操作性较强。
本文对应论文和ppt下载地址:网盘地址