背景介绍
分布式,实时性
在前面一章,我简单地介绍了我们的智能家居大数据基础平台架构,我们知道对于一些实时性要求比较高的数据,比如一些控制命令(传感器的开关状态、智能小车的速度)等信息需要实时地传送到数据中心,并且数据中心需要将这些数据实时推送给其他子系统,包括计算服务平台,智能设备监控平台。在这种情况下,相当于不是用户在请求数据,而是服务器在主动推送数据。
但细细想来,发现以上两种场景稍有差异:
- 控制命令等一系列的数据实时推送到数据中心
- 数据中心推送给各个子系统,这些子系统各司其职,都有自己的本职工作
场景1下,数据中心就好比一个大的垃圾桶,只是这个大的垃圾桶主动收任何垃圾。
场景2下,各个子系统有些任性,只干好自己的本职工作,跟自己工作内容无关的,它统统都不收。因此场景2的子系统需要提前告诉数据中心,它自己的职能,数据中心才能根据子系统的职能,有选择地给它们推送需要的数据。
那这两种具体该如何解决呢?
两个场景的概念
数据接入、事件分发
数据接入

在数据采集系统中的各种智能设备上报通过API接口上报数据,消息队列负责数据流的并行处理与持久化。最终以平稳的速度推送到数据中心负责数据的处理。
事件分发

各个子系统充当事件处理器的角色,首先需要订阅数据库中的事件,消息中心统一管理子系统订阅的事件,各个智能设备只要更新了相关事件的状态,立即发布事件给消息中心,消息中心分发事件给相应的事件处理器。
谈谈其中的设计模式
观察者模式,生产者消费者模式,发布订阅模式
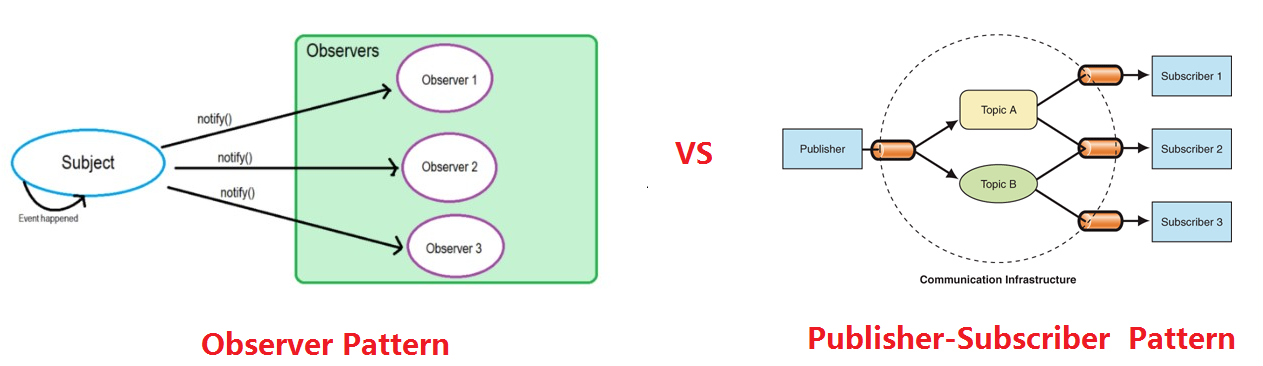
Publishers + Subscribers = Observer Pattern ? 显然不!发布订阅者模式是一种分布式场景下的模式。
它们的主要区别如下图:
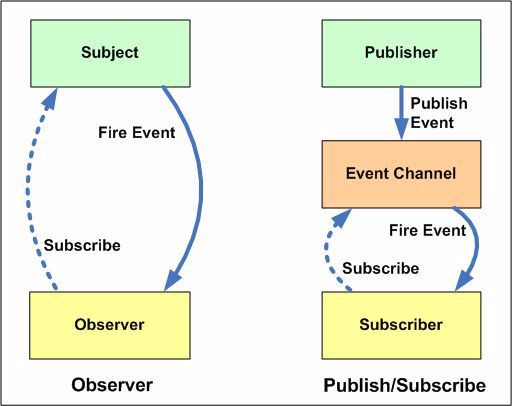
我们可以看到在发布-订阅者中间有个事件转发器,作为发布者和订阅者的消息代理来处理两者之间的通信。这种通信模式保证了:
- 屏蔽了发布者和订阅者的处理细节:
在Observer模式中,Observers知道Subject,同时Subject还保留了Observers的记录。然而,在发布者/订阅者中,发布者和订阅者不需要彼此了解。他们只是在消息队列或代理的帮助下进行通信。
2、Publisher / Subscriber组件是松散耦。
3、发布者/订阅者在大多情况下是异步方式处理消息,观察者模式主要以同步方式实现。
4、观察者模式需要在单个应用中实现。另一方面,发布者/订阅者模式可实现平台构建。
参考资料
观察者和发布订阅模式的区别.https://www.cnblogs.com/viaiu/p/9939301.html
RabbitMQ下的生产消费者模式与订阅发布模式.https://blog.csdn.net/zwgdft/article/details/53561277
Kafka下的生产消费者模式与订阅发布模式.https://blog.csdn.net/zwgdft/article/details/54633105https://blog.csdn.net