1. Abstarct
目前大多数的image caption的模型都严重地依赖成对的图片—语句数据集,但获得他们代价较高,因此在本篇论文中,作者第一次尝试了无监督模型。该模型需要一个图像集、一个语料库和一个视觉检测器。同时,因为现有的语料库大多用于语言研究,与图片相关性不大,因此作者爬取了一个范围大的图片描述语料库,其中包括了200万自然语言句子。
2. Introduction
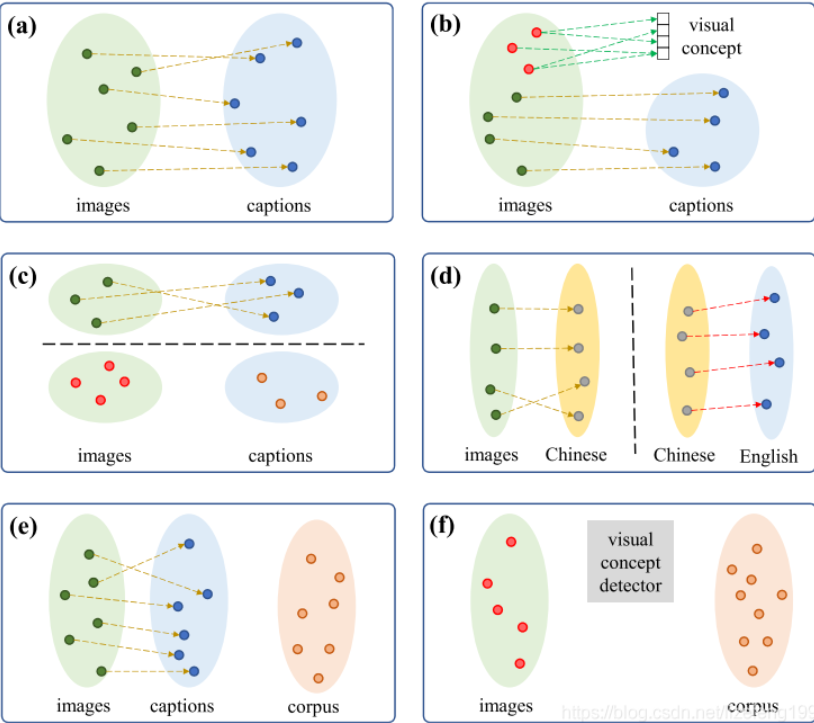
这幅原文中出现的图片描述了现存的image caption模型在概念上的区别:
图a指的是有监督学习,他需要图像—句子对进行训练。
图b指的是为那些不存在在图像—句子对中但是存在于图像识别数据集中的目标进行产生caption,这样新目标就能被引入进句子中。
图c指的是将从现有的图像—句子对学习到的内容转移泛化到没有配对的数据上。这样,对于新的模型就不用成对的图像—句子数据去进行训练。
图d指的是将图像转化成枢轴语言(中文)的句子,再将枢轴语言翻译成目标语言(英文)。
图e指的是使用一个半监督学习的框架,在其中使用外部的文本语料库进行预训练。
图f即为本文作者提出的无监督学习模型。
在本文模型中有三个关键步骤:
我们使用对抗文本生成方法在句子语料库上训练语言模型,该方法以给定图像特征生成句子。 因为在无监督的情况下,作者没有训练图像的正确描述。 因此,我们采用对抗训练来生成句子。
为了确保生成的字幕包含图像中的内容,作者将视觉检测器提供的知识提取到模型中,即当与图像中检测到的视觉概念相对应的单词出现在生成的句子中,就会得到奖励。
对于给定的图像特征,我们可以解码一个caption,他可以进一步用于重建图像特征。同样,我们也可以从语料库中对句子进行特征编码,然后对句子进行重构。通过双向重构,生成的句子就会表示图像的语义含义,从而改进模型。
总的来说,本文的贡献有四条:
对无监督的image caption做了尝试
提出了训练image caption模型的三个目标
提出使用无标签数据进行初始化管道
爬取了200万个句子,并带来了很好的效果
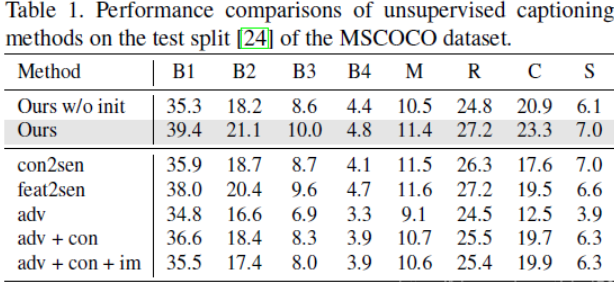
3、试验细节(模型的初始化)
直接使用不配对的数据来训练效果很差。因此提出了一种方式预训练生成器和鉴别器。
先为每个训练图像生成伪标题,然后使用伪图像标题对来初始化图像标题模型。
(1)首先构建一个由OpenImages数据集中的对象类组成的概念字典。
(2)仅使用句子语料库训练概念到句子(con2sen)模型。给定一个句子,我们使用单层LSTM将句子中的概念词编码为特征表示,并使用另一个单层LSTM将表示解码为整个句子。
(3)使用现有的视觉概念检测器检测每个图像中的视觉概念。利用检测到的概念和概念到句子模型,我们能够为每个图像生成伪标题。
(4)使用标准监督学习方法训练具有伪图像 - 标题对的生成器。
4、 模型附图

5、实验结果附图