bert作为开创性的模型,可以用于大部分的场景,但也存在一些问题,不能用于生成,训练数据和测试数据的不一致(Discrepancy)。XLnet是比bert更强大的预训练模型,基于permutation实现了真正的双向学习,使用双流自注意力机制,结合transformers-XL的相对位置编码,效果显著。
1、ELmo与双向lstm
2、bert 模型的特点
3、permutation 与XLnet模型介绍
unsupervised learning
1、easily get lots of unlabeled data
目前神经网络模型训练时是基于反向传播,对网络参数进行初始化,利用优化算法优化模型参数。标注很少的数据集上,这种方法往往精度有限,‘预训练’则能够很好的解决这个问题。
预训练是利用无标注语言文本进行训练,得到模型参数,利用这套参数对模型初始化,根据具体任务在语言模型上进行精调,热门的预训练方法有ELmo,OpenAI GPT,BERT和XLnet等。
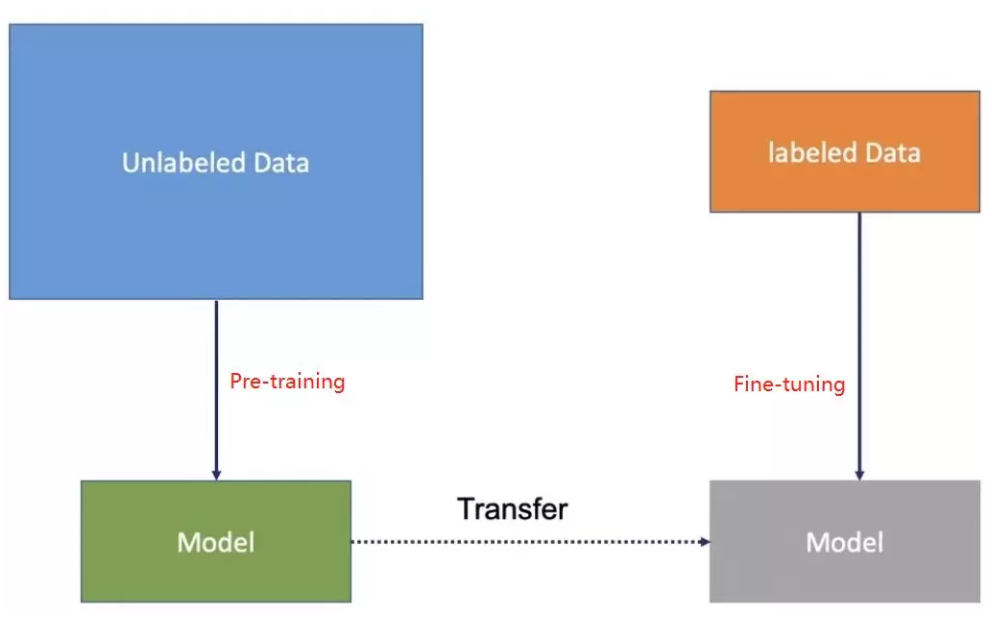
2、labeling
Non-contexuailized techniques eg.skipgram cbow glove
Contexualized techniques eg.elmo bert xlnet
早起的无监督预训练模型主要是word2vec,基本都使用了不考虑上下文嵌入的方式训练向量
2018年初,AllenNLP和华盛顿大学的研究人员在《Deep contextualized word representations》中提出ELmo。相比较传统的词嵌入(word embedding)词语表示,每个词得到固定的词向量,Elmo利用预训练好的双向语言模型,根据具体输入可以得到文本中该词语的表示。有监督的NLP任务中,Elmo可以当做输入特征拼接到具体任务模型的词向量输入或者模型的最高层表示上。
Elmo于2018年提出,是2013年提出的embedding之后的另一转折点。elmo是基于语境的深度词表示模型(word representation model),他可以铺获单词的复杂特征(词性句法),也可以解决同一个词在不同语境下的不同表示(歧义)
在ELMo的基础之上,OpenAI的研究人员在《Improving Language Understanding by Generative Pre-Training》提出了OpenAI GPT。与ELMo为每一个词语提供一个显式的词向量不同,OpenAI GPT能够学习一个通用的表示,使其能够在大量任务上进行应用。在处理具体任务时,OpenAI GPT 不需要再重新对任务构建新的模型结构,而是直接在 Transformer 这个语言模型上的最后一层接上 softmax 作为任务输出层,再对这整个模型进行微调。GPT 采用无监督学习的 Pre-training 充分利用大量未标注的文本数据,利用监督学习的 Fine-tuning 来适配具体的 NLP 任务(如机器翻译等)。
ELMo和OpenAI GPT这两种预训练语言表示方法都是使用单向的语言模型来学习语言表示,而Google提出的BERT则实现了双向学习,并得到了更好的训练效果。具体而言,BERT使用Transformer的编码器作为语言模型,并在语言模型训练时提出了两个新的目标:一个是 token-level 级别的MLM(Masked Language Model)和一个是 sentence-level 级别的NSP(Next Sentence Prediction)。MLM是指在输入的词序列中,随机的遮挡上 15% 的词,并对遮挡部分的词语进行双向预测。为了让模型能够学习到句子间关系,研究人员提出了让模型对即将出现的句子进行预测:对连续句子的正误进行二元分类,再对其取和求似然。
自从ELMo、GPT和BERT出现之后,pretrain+finetune的两段式训练方法,成为NLP任务的主流做法。在公开的语料库上对大模型进行自监督或者无监督的预训练,然后在特定任务的语料库上对模型做微调。本文介绍另外一篇类似的算法XLNet。
【1】Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.
【2】Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. URL https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf, 2018.
【3】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
Denoising auto encoder 去噪自动编码器,深度学习模型——学出图片或数据更有效的表示,
DAE在训练中加入噪声,提高模型健壮性
2、auto_regressive vs auto_encoding
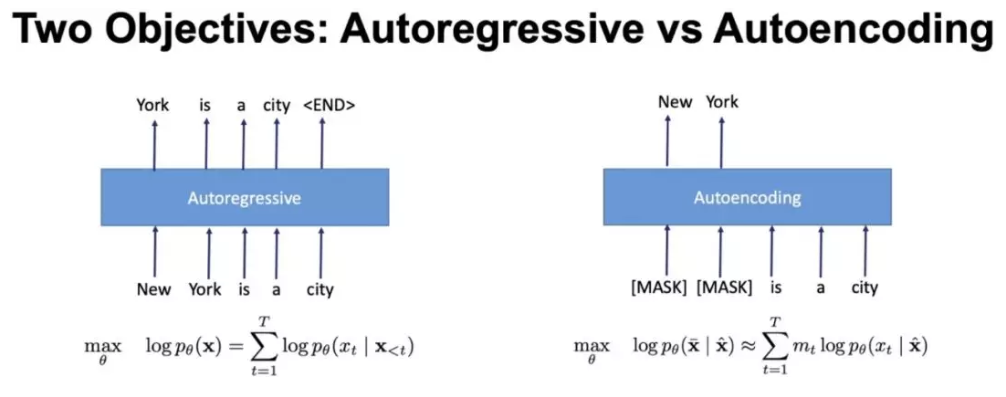
自回归:指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表有 ELMO, GPT等代表elmo
优点:保持一致性,考虑词的依赖关系;缺点:单向的,不同同时考虑双边
自动编码: 通过上下文信息来预测被mask的token,代表有 BERT , Word2Vec(CBOW)
bert , mask一些单词导致预训练和微调阶段不一致,基本独立假设 bert存在的问题:independent assumption,没有对mask的token之间关系进行学习
优点:考虑了双向的关系;缺点:非独立假设;
所以,AR方式所带来的自回归性学习了预测 token 之间的依赖,这是 BERT 所没有的;而 BERT 的AE方式带来的对深层次双向信息的学习,却又是像ELMo还有GPT单向语言模型所没有的,不管是有没有替换 [MASK]。
3、permutation language model 排列语言模型
基于elmo考虑双向问题进行改造。answer:consider all possibel factorization
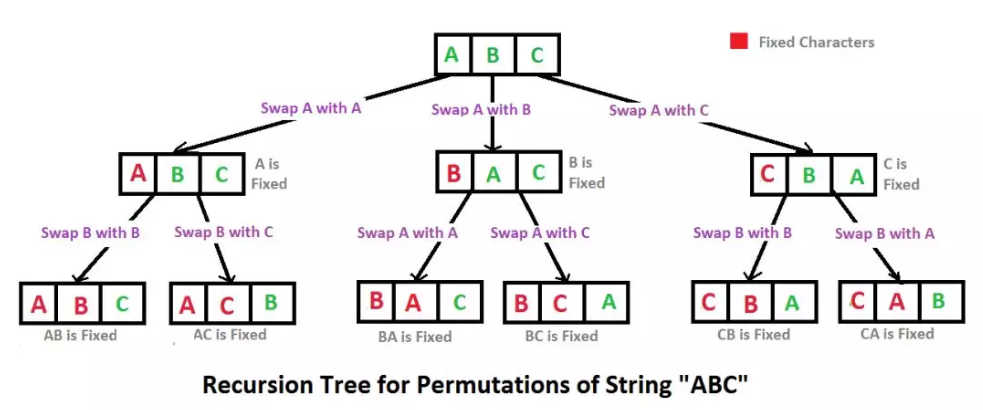
具体实现方式是,通过随机取一句话的一种排列,然后将末尾一定量的词给遮掩(和 BERT 里的直接替换 [MASK] 有些不同)掉,最后用 AR 的方式来按照这种排列依次预测被遮掩掉的词。
随机采样一定序列,attention mask,把词的顺序混排进模型(类似于数据增强,不改造模型,从数据输入上改造);
二、已知向量的信息,知道向量的位置,结合两个信息
从XLNet论文的结果来看,其在问答、文本分类、自然语言理解等任务上大幅超越BERT。除了相比BERT增加了训练集之外,XLNet也在模型设计上有较大的改进,比如引入了新的优化目标Permutation Language Modeling(PLM),使用了双流自注意力机制(Two-Stream Self Attention, TSSA)和与之匹配的Mask技巧。此外,XLNet还使用了Transformer-XL作为Backbone,也使用了Transformer-XL的相对位置编码。所以,相比BERT,XLNet对长文本的支持更加有效。这些改进为BERT类预训练模型难以进行生成任务的问题提供了一个解决思路。可以期待,在不久的将来,NLP预训练模型能够突破一系列生成任务,实现NLP模型结构化的统一。
VAE详细解读:variable autoencoder
推荐课程:NLP高阶免费课程,NLP与知识图谱高阶免费课程
NLP优质博客:http://jalammar.github.io
视频回顾:CQU弟中弟
参考文章:Xlnet详解,跟着写笔记
【1】Larochelle H, Murray I. The neural autoregressive distribution estimator[C]//Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. 2011: 29-37.
【2】Uria B, Côté M A, Gregor K, et al. Neural autoregressive distribution estimation[J]. The Journal of Machine Learning Research, 2016, 17(1): 7184-7220.
【3】The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning),Jay Alammar'blog,地址:https://jalammar.github.io/illustrated-bert/
【4】【AI模型】最通俗易懂的XLNet详解,地址:https://www.bilibili.com/video/av73657563?p=1
【5】Dissecting Transformer-XL,地址:https://mc.ai/dissecting-transformer-xl/
【6】你应该知道的transformer - Don.hub的文章 - 知乎 https://zhuanlan.zhihu.com/p/102591791
【7】飞跃芝麻街:XLNet 详解 - Andy Yang的文章 - 知乎 https://zhuanlan.zhihu.com/p/71916499
【8】就最近看的paper谈谈预训练语言模型发展 - 老宋的茶书会的文章 - 知乎 https://zhuanlan.zhihu.com/p/79371603
【9】XLNet:运行机制及和Bert的异同比较 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/70257427
【10】请收好这份NLP热门词汇解读:预训练、Transformer、无监督机器翻译 - 七月在线 七仔的文章 - 知乎 https://zhuanlan.zhihu.com/p/59158735
【11】论文笔记 —— Transformer-XL - 谢玉强的文章 - 知乎 https://zhuanlan.zhihu.com/p/70745925
【12】香侬读 | XLnet:比Bert更强大的预训练模型 - 香侬科技的文章 - 知乎 https://zhuanlan.zhihu.com/p/71759544