1、理论铺垫
Dataframe和Series均适用
~集中趋势:均值mean()、中位数median()、与分位数quantile(q=0.25)、众数mode()
~离中趋势:标准差std()、方差var()
数据分布:偏态skew()与峰态kurt()、正态分布与三大分布
 正偏态(mean>median)
正偏态(mean>median)
import scipy.stats as ss
正态分布:ss.norm 、卡方分布:ss.chi2 、t分布:ss.chi2、f分布:ss.chi2
偏态系数:数据平均值偏离状态的衡量
峰态系数:数据分布集中强度的衡量
~ 抽样定理:抽样误差、抽样精度
data.sample(10) #抽10个
data.sample(frac = 0.001) #抽样百分比为0.001
2、数据分类
· 定类(类别):根据事物离散、无差别属性进行的分类,如:名族
· 定序(顺序):可以界定数据的大小,但不能测定差值:如:收入的低、中、高
· 定距(间隔):可以界定数据大小的同时,可测定差值,但无绝对零点,如:温度
· 定比(比率):可以界定数据大小,可测定差值,有绝对零点,如:身高、体重
3、单属性分析
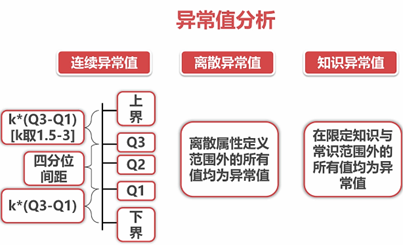
3.1异常值分析
离散异常值,连续异常值,常识异常值
3.2对比分析
绝对数与相对数(比什么),时间、空间、经验与计划(如何比)
绝对数比较:绝对的数字的比较,例如:收入
相对数比较:将几个有联系的指标进联合,构成一个新的数
3.3结构分析
各组成部分的分布与规律

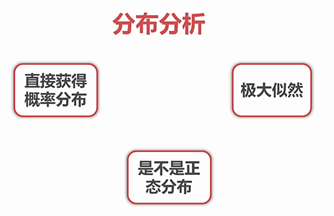
3.4分布分析
数据分布频率的显式分析
其中seaborn是matplotlib的封装
Seaborn官网: http://seaborn.pydata.org/api.html
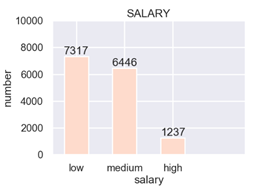
(1)柱状图 --- 以纵轴表示数值大小
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#其中seaborn是matplotlib的封装
data = pd.read_csv('HR.csv',sep=',')
pd.set_option('display.max_columns',None) #控制列的输出
#处理异常之后的数据
data = data[data['last_evaluation']<=1][data['department']!='sale'][data['salary']!='nme']
#设置图画格式
sns.set_style(style="darkgrid")#style="whitegrid" sns.set_context(context="poster",font_scale=0.5) sns.set_palette(sns.color_palette('Reds')) plt.title('SALARY') plt.xlabel('salary') plt.ylabel('number') #设置横轴的显示 plt.xticks(0.5+np.arange(len(data['salary'].value_counts())),data['salary'].value_counts().index) #设置横轴显示的最小值是0,最大是4;纵轴显示的最小值是0,最大值是10000 plt.axis([0,4,0,10000]) plt.bar(0.5+np.arange(len(data['salary'].value_counts())),data['salary'].value_counts(),width=0.5) for x,y in zip(0.5+np.arange(len(data['salary'].value_counts())),data['salary'].value_counts()): plt.text(x,y,y,ha="center",va="bottom")#对每一类进行标注,标注的值为y,水平位置是center,垂直位置是bottom plt.show() # sns.countplot(x="salary",data=data) sns.countplot(x="salary",hue= "department",data=data)#多层绘制,例如以部门为分割 plt.show()
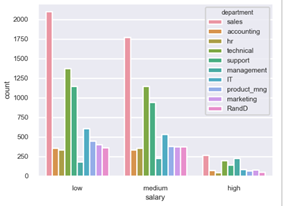
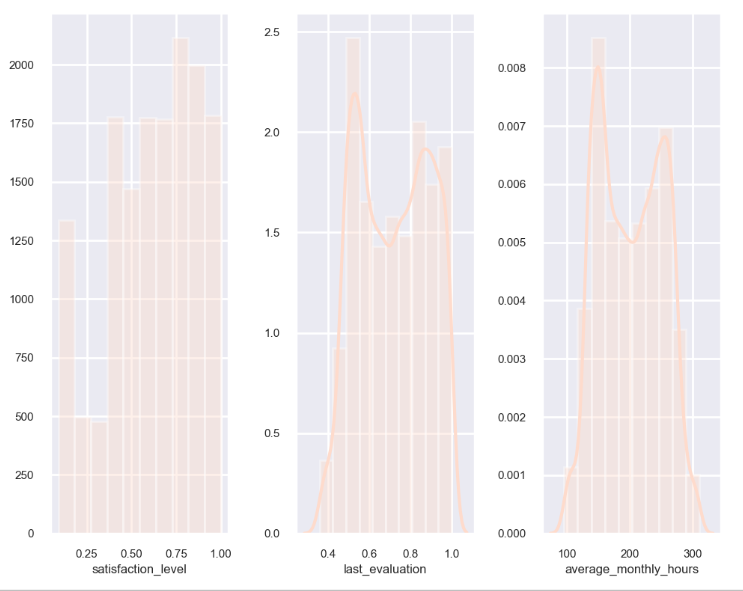
(2)直方图---以面积表示数值大小
横轴表示数据类型,纵轴表示分布情况
plt.figure(figsize=(10,8)) plt.subplot(1,3,1) #其中kde表示可密度估计,hist表示直方图 sns.distplot(data['satisfaction_level'],bins=10,kde=False,hist=True) plt.subplot(1,3,2) sns.distplot(data['last_evaluation'],bins=10,kde=True,hist=True) plt.subplot(1,3,3) sns.distplot(data['average_monthly_hours'],bins=10,kde=True,hist=True) plt.show()
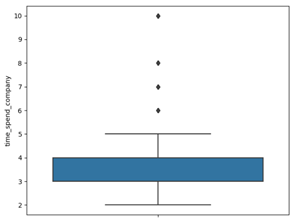
(3)箱线图
用于显示一组数据分散情况的统计图
#saturation=0.75表示上四分位数,whis=3表示k=3,默认值是1.5,其中y表示呈现方式
sns.boxplot(y = data['time_spend_company'],saturation=0.75,whis=1.5)
plt.show()
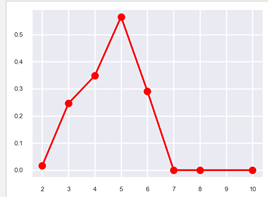
(4)折线图
matplotlib--- plt.plot();seaborn--- sns.poinplot()
值得一提的是:sns中对折线图有两种画法
(见标黄部分,可以直接指定x和y,两种写法一样,结果还可以指定上下界----此处疯狂打call)
sub_data = data.groupby('time_spend_company').mean()
# print(sub_data)
sns.pointplot(sub_data.index,sub_data['left'])
# sns.pointplot(data['time_spend_company'],data['left'])
# plt.plot(sub_data.index,sub_data['left'],'ro-')
plt.show()

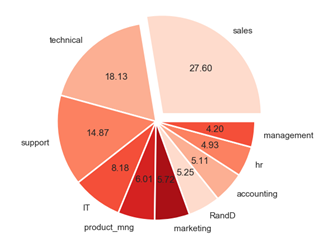
(5)饼图
seabon库中没有饼图的画法,只有matplotlib中有
libs = data['department'].value_counts().index
explodes = [0.1 if i == 'sales' else 0 for i in libs]
plt.pie(data['department'].value_counts(normalize=True),labels=libs,autopct="%.2f",colors=sns.color_palette('Reds'),explode = explodes)
plt.show()