2018年1月 《通信学报》 魏亮,黄韬,张娇,王泽南,刘江,刘韵洁
摘要
提出基于人工智能技术的多智能体服务链资源调度架构,设计一种基于强化学习的服务链映射算法。通过Q-learning 的机制,根据系统状态、执行部署动作后的奖惩反馈来决定服务链中各虚拟网元的部署位置。实验结果表明,与经典算法相比,该算法有效降低了业务的平均传输延时,提升了系统的负载均衡情况。
引言
服务链定义了特定顺序的网络功能集合,其放置将影响业务编排、服务提供以及物理资源的使用效率。服务链需要面临资源分配优化、动态流量调控、动态服务映射、服务策略实施、服务可靠性及可用性、安全等方面的挑战。它常常以最小化网络延时、最小化能耗、最小化代价、最大化资源利用率等为目标进行建模优化服务链映射问题。
提出的问题
优化服务链映射问题。优化目标为服务链的平均链路延时和服务器的负载。
解决方案
提出一种基于多智能体强化学习技术的服务链资源调度架构,如下图。
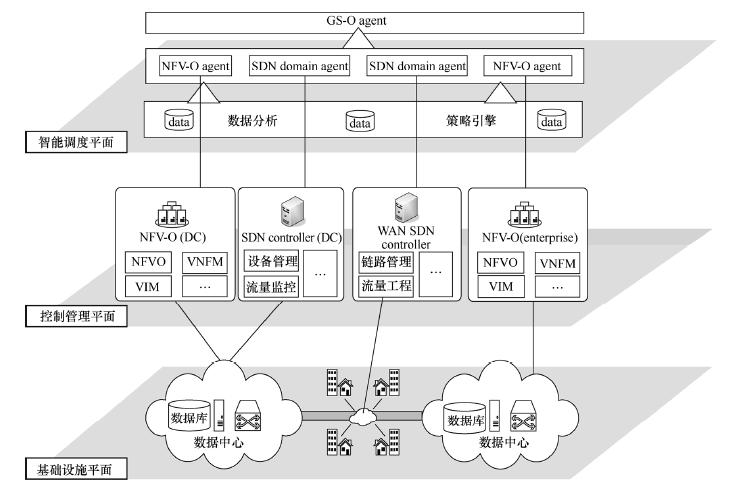
该架构将构建一个层次化的多agent强化学习管理体系,该体系中的每一个agent都代表一定的角色。
其系统控制及流程如下:
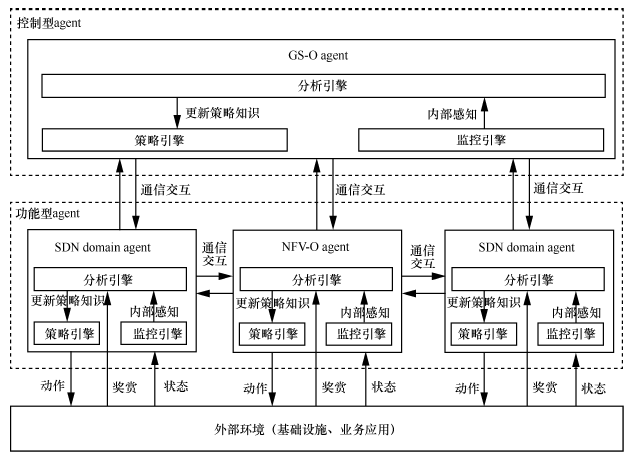
各自治agent 主要采用强化学习的方式进行学习,通过不断与基础设施和业务服务环境的接触获取控制经验并改善控制行为。
每一个agent 强化学习框架结构包含监控引擎、分析引擎、策略引擎,分别对应状态感知器、学习器、动作选择器等能力。
系统可以承载虚拟化核心网、虚拟化内容分发网络、云安全防护等多种业务,动态智能调度底层计算、存储、网络资源并依据业务特性进行编排。
当需要进行服务链映射时,其处理流程如下图所示。
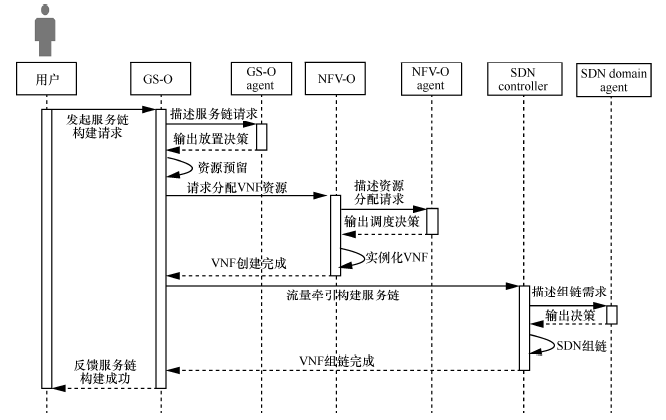
1) 用户向GS-O 发起服务链构建请求,GS-O agent 根据请求描述输出放置决策。
2) GS-O 进行响应检查可用资源并进行资源预留,通知NFV-O和SDN controller 执行具体资源分配。
3) NFV-O 向NFV-O agent 请求资源分配策略,实例化VNF。
4) SDN controller 向SDN domain agent 请求SDN组链策略,下发流表进行流量调度构建服务链。
5) GS-O 给用户反馈服务链构建成功信息。
强化学习在这里起的作用
各自治agent采用强化学习的方式进行学习,通过不断与基础设施和业务服务环境的接触获取经验并改善控制行为。通过外部环境提供的强化信号(奖励或惩罚)对控制动作的好坏做出客观评价。通过这种方式,各agent 在行动—评价的体系中获得知识,改进行动方案以适应外部环境需求。
状态集:基于物理服务器节点已经使用的vCPU 数量定义单个节点的状态,为每个节点的vCPU 使用量设置一个门限值,假设超过该门限值,则该节点状态为1,否则,节点状态为0。考虑全局节点的状态,假设有N个节点,每个节点有0 和1 这2 种状态,则全局有2^N 种状态。
动作集:根据每个时刻的状态信息,需要为当前需要部署的VNF 选择一个物理服务器节点进行部署,假设有N 个节点,则动作集中的每个动作对应一个节点,则有N 种动作。
反馈函数:针对不同的情况,设置不同的反馈值。
服务链映射算法中用到了Q-learning算法来选择合适的VNF放置节点。
对比实验
与SPG算法、LLG算法、RD算法对比。
专业概念认识
- 强化学习:
强化学习是人工智能领域机器学习技术中的重要方法之一,它区别于监督学习、无监督学习的地方在于其与环境交互的特点。强化学习是一种交互式的学习方法,强调在与环境的交互中学习获得评价性的反馈信号,在不需要给定各种状态下输入信号的期望输出情况下,通过最大化未来回报为学习目标。因此,强化学习具有自学习和在线学习的优点,在求解先验信息较少的复杂优化决策问题中具有广泛的应用场景。
强化学习运用智能体对环境做出主动试探,不断地试错交互来进行学习。智能体首先感知环境状态,并根据环境当前状态和内部控制策略选择一个动作并执行。环境迁移到新状态后,给出一个新的强化信号对智能体选择动作的好坏做出评价。智能体根据环境反馈的奖赏值计算回报并更新内部控制策略。然后根据新的强化信号和当前环境状态选择下一个动作。智能体选择动作的原则是使从环境中获得正强化信号的概率增大,受到惩罚的概率变小。智能体应选择能最大化长期奖赏之和的动作。因此,在利用强化学习解决现实问题过程中,最重要的是将一个实际的问题转化成为强化学习的模型并利用相关的算法来得到优化的策略结果。即根据所要解决的实际问题,定义环境中的状态集、动作集和反馈函数。
- Q-Learning算法:
Q-learning 算法是一种模型无关的值迭代方法,不需要提前知道状态转移矩阵,以求解具有延时回报的序贯优化决策问题。