tensorflow的数据集可以说是非常重要的部分,我认为人工智能就是数据加算法,数据没处理好哪来的算法?
对此tensorflow有一个专门管理数据集的方式tfrecord·在训练数据时提取图片与标签就更加方便,但是tensorflow
的使用可以说,有时还是会踩着坑的,对此我做了一个代码专门用于去制作tfrecord和读取tfrecord。
1.首先我们要整理数据集格式如下
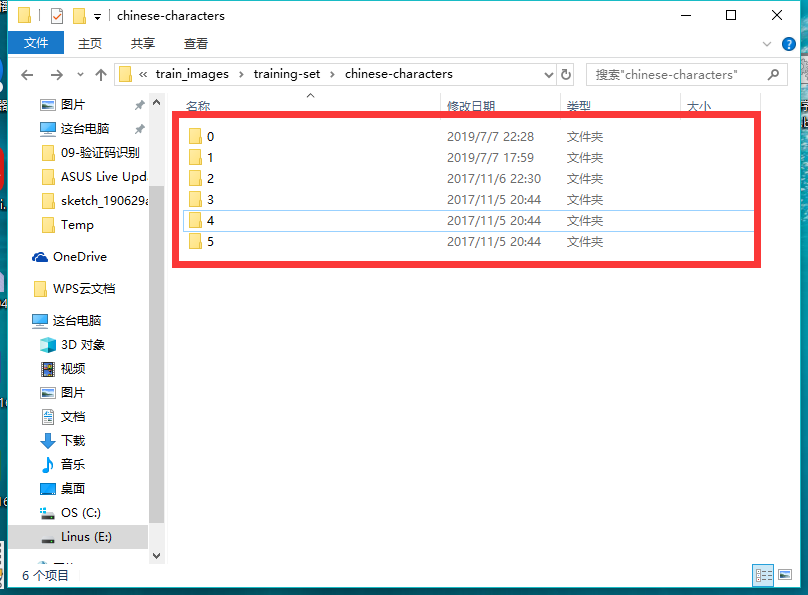
是的就是这样每个类别的图片数据分别在一个文件夹图片的名字可以随意取,当然要都是相同的编码格式jpg,png之类。
我们在为这些图片按照这样的格式分好类了之拷贝整个路径就可以了
import os import tensorflow as tf import cv2 as cv os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' FLAGS = tf.app.flags.FLAGS tf.flags.DEFINE_list('image_CNN_shape', [None, 40, 32, 1], 'image shape [high, width, pip]') tf.flags.DEFINE_list('image_shape', [40, 32, 1], 'image shape [high, width, pip]') tf.flags.DEFINE_list('label_CNN_shape', [None, 6], 'label shape is one-hot list [batch, sort]') tf.flags.DEFINE_list('label_shape', [1], 'label shape ') tf.flags.DEFINE_integer('batch_size', 20, 'one batch size ') def Reader(train_path): ''' 输入训练集的整个文件夹生成一个tf的训练文件 train_path dir_name: 0开始是排序 file_name :1开始排序 :param train_path: 训练集路径 :return: ''' # 1.生成图片文件队列 # 1.1生成分类的dir 列表 one_list = os.listdir(train_path) # 1.2路径添加完整 # list_dir = add_path(one_list, train_path) # print(list_dir) for i in range(len(one_list)): one_list[i] = train_path + r'/' + str(i) all_image_list = [] all_label_list = [] # print(one_list) for j in range(len(one_list)): two_list = os.listdir(one_list[j]) for i in range(len(two_list)): all_label_list.append(j) all_image_list.append(one_list[j] + '/' + two_list[i]) print(len(all_label_list)) image_queue = tf.train.string_input_producer(all_image_list, shuffle=True) # 2.构造阅读器 reader = tf.WholeFileReader() # 3.读取图片 key, value = reader.read(image_queue) # print(value) # 4.解码数据 image = tf.image.decode_bmp(value) image.set_shape([40, 32, 1]) # [高,宽,通道] # print(image) # 5.批处理数据 Op_batch = tf.train.batch([image, key], batch_size=1254, num_threads=1) with tf.Session() as sess: coor = tf.train.Coordinator() thread = tf.train.start_queue_runners(sess=sess) # 开启队列的线程 image_data, label_data = sess.run(Op_batch) label_list = [] lenth = len(label_data) for i in range(lenth): datalist = str(label_data[i]).split('/') label_list.append(int(datalist[1])) write_to_tfrecord(label_list, image_data, lenth) print('tfrecord write down') coor.request_stop() # 发出所有线程终止信号 coor.join() # 等待所有的子线程加入主线程 def add_path(listdir, train_path): for i in range(len(listdir)): listdir[i] = train_path + r'/' + listdir[i] return listdir def write_to_tfrecord(label_batch, image_batch, lenth): ''' 要点:避免在循环里面eval或者run :param label_batch: numpy类型 :param image_batch: numpy类型 :param lenth: int类型batch的长度 :return: None 会生成一个文件 ''' writer = tf.python_io.TFRecordWriter(path=r"./text.tfrecords") label_batch = tf.constant(label_batch) label_batch = tf.cast(label_batch, tf.uint8) for i in range(lenth): image = image_batch[i].tostring() label = label_batch[i].eval().tostring() # 构造协议块 # tf_example可以写入的数据形式有三种,分别是BytesList, FloatList以及Int64List的类型。 Example = tf.train.Example(features=tf.train.Features(feature={ 'label': tf.train.Feature(bytes_list=tf.train.BytesList(value=[label])), 'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])) })) writer.write(Example.SerializeToString()) print('write: ', i) writer.close() def read_tfrecord(path_list): # 生成阅读器 reader = tf.TFRecordReader() # 定义输入部分 file_queue = tf.train.string_input_producer(path_list, shuffle=False) key, value = reader.read(file_queue) # 解析value features = tf.parse_single_example(serialized=value, features={ 'image': tf.FixedLenFeature([], tf.string), 'label': tf.FixedLenFeature([], tf.string) }) image = tf.decode_raw(features['image'], tf.uint8) label = tf.decode_raw(features['label'], tf.uint8) image = tf.reshape(image, FLAGS.image_shape) label = tf.reshape(label, FLAGS.label_shape) image_batch, label_batch = tf.train.batch([image, label], batch_size=FLAGS.batch_size, num_threads=1, capacity=FLAGS.batch_size) print(image_batch, label_batch) return image_batch, label_batch if __name__ == '__main__': train_path = r'E:百度云下载 f_car_license_dataset rain_images raining-setchinese-characters' dir_list = [] read_path_list = [r"./other.tfrecords", ] Reader(train_path)
Reader就是制作tfrecord
read_tfrecord就是按照路径去读取数据读出来的数据的shape 是FLAGS.image_CNN_shape形状的数据,方便做卷积
注:在做数据集整理的时候我做了许多的尝试,由于这样对图片分类,制作数据的时候打标签才更容易,最容易的莫过于,制作的时候所有一类的都放在一起,
也就是前200个读取出来的都是0号,下一个读取出来的都是1号。。。结果这样的数据集卷积神经网络怎么都不收敛,很尬,我程序跑了一天了,准确率上不去,
我都以为是我模型构建错误的原因,结果还是找不出问题所在。后来我改变了数据集的制作方式,改成乱序制作,训练就非常高效的成功了。最后要补充的是,
当数据的准确率一直在震荡,那么你可以尝试着把学习率改的更小比如0.0001就好了。这个过程还是要多多实际操作。
2.制作tfrecord慢的原因,一定要记住在tensorflow里面的tensor和op的区别,run 和 eval tensor 会获得里面的数据,但是run 和 eval op则会执行这个op,
虽然都会出现函数的返回值一样的结果是因为op运行的结果出来了,如果在制作tfrecord的for循环里面存在eval或者run op会导致制作的过程异常的慢,几千个数据集可能要做一晚上。
举个反面例子
def Reader(train_path): ''' 输入训练集的整个文件夹生成一个tf的训练文件 train_path dir_name: 0开始是排序 file_name :1开始排序 :param train_path: 训练集路径 :return: ''' # 1.生成图片文件队列 # 1.1生成分类的dir 列表 one_list = os.listdir(train_path) # 1.2路径添加完整 # list_dir = add_path(one_list, train_path) # print(list_dir) for i in range(len(one_list)): one_list[i] = train_path + r'/' + str(i) all_image_list = [] all_label_list = [] print(one_list) for j in range(len(one_list)): two_list = os.listdir(one_list[j]) for i in range(len(two_list)): all_label_list.append(j) all_image_list.append(one_list[j] + '/' + two_list[i]) print('%s:'%j,len(two_list)) # 校验 print(all_label_list) lenth = len(all_label_list) lenth_image = len(all_image_list) print('label len:', lenth) print('image len: ', lenth_image) image_queue = tf.train.string_input_producer(all_image_list, shuffle=False) # 2.构造阅读器 reader = tf.WholeFileReader() # 3.读取图片 key, value = reader.read(image_queue) # print(value) # 4.解码数据 image = tf.image.decode_bmp(value) image.set_shape([40, 32, 1]) # [高,宽,通道] # print(image) # 5.批处理数据 image_batch_op = tf.train.batch([image], batch_size=lenth, num_threads=1) with tf.Session() as sess: coor = tf.train.Coordinator() thread = tf.train.start_queue_runners(sess=sess) # 开启队列的线程 write_op = write_to_tfrecord(all_label_list, image_batch_op, lenth) print('tfrecord write down') coor.request_stop() # 发出所有线程终止信号 coor.join() # 等待所有的子线程加入主线程 def write_to_tfrecord(label_batch, image_batch, lenth): writer = tf.python_io.TFRecordWriter(path=r"./mnist_data/other1.tfrecords") label_batch = tf.constant(label_batch) label_batch = tf.cast(label_batch, tf.uint8) for i in range(lenth): image = image_batch[i].eval().tostring() # 在这里eval()的话就会很慢 类似于每一次都run了一下image_batch的这个op--也算是个反面教材吧 label = label_batch[i].eval().tostring() # 构造协议块 # tf_example可以写入的数据形式有三种,分别是BytesList, FloatList以及Int64List的类型。 Example = tf.train.Example(features=tf.train.Features(feature={ 'label': tf.train.Feature(bytes_list=tf.train.BytesList(value=[label])), 'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])) })) writer.write(Example.SerializeToString()) print('write: ', i) writer.close()
这里传入写入函数的image_batch的是一个op 所以在函数里面需要每一个都eval,导致程序很慢。因为每一次eval和run一个op需要牵扯到很多的数据计算。最好在循环外面就完成这个操作。