- 网络协议 1 - 概述
- 网络协议 2 - IP 是怎么来,又是怎么没的?
- 网络协议 3 - 从物理层到 MAC 层
- 网络协议 4 - 交换机与 VLAN:办公室太复杂,我要回学校
- 网络协议 5 - ICMP 与 ping:投石问路的侦察兵
- 网络协议 6 - 路由协议:敢问路在何方?
- 网络协议 7 - UDP 协议:性善碰到城会玩
- 网络协议 8 - TCP 协议(上):性恶就要套路深
上次了解了 TCP 建立连接与断开连接的过程,我们发现,TCP 会通过各种“套路”来保证传输数据的安全。除此之外,我们还大概了解了 TCP 包头格式所对应解决的五个问题:顺序问题、丢包问题、连接维护、流量控制、拥塞控制。今天,我们就来看下 TCP 又是用怎样的套路去解决这五个问题的。
在解决问题之前,咱们先来看看 TCP 是怎么成为一个“靠谱”的协议的。
“靠谱”协议 TCP
TCP 为了保证顺序性,每个包都有一个 ID。这建立连接的时候,会商定起始 ID 的值,然后按照 ID一个个发送。
为了保证不丢包,对于发送的包都要进行应答。但是这个应答不是一个一个来的,而是会应答某个之前的 ID,表示都收到了,这种模式称为累计确认和累计应答。
为了记录所有发送的包和接收的包,TCP 也需要发送端和接收端分别用缓存来保存这些记录。发送端的缓存里是按照包的 ID 一个个排列,根据处理的情况分成四个部分:
- 第一部分:发送且已经确认的;
- 第二部分:发送尚未确认的;
- 第三部分:没有发送,但是已经等待发送的;
- 第四部分:没有发送,并且暂时还不会发送的。
于是,发送端需要保持这样的数据结构:
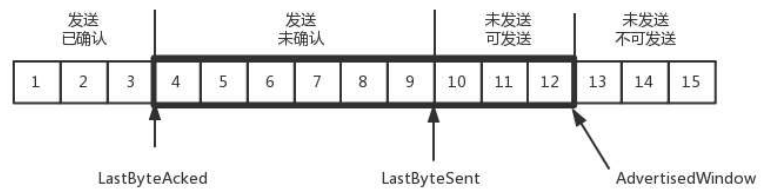
- LastByteAcked:第一部分和第二部分的分界线
- LastByteSent:第二部分和第三部分的分界线
- LastByteAcked:第三部分和第四部分的分界线
对于接收端来讲,它缓存记录的内容要简单一些,分为以下三个部分:
- 第一部分:接收且确认过的;
- 第二部分:还没接收,但是马上就能接收的;
- 第三部分:还没接收,也没空间接收的。
对应的数据结构就像这样:
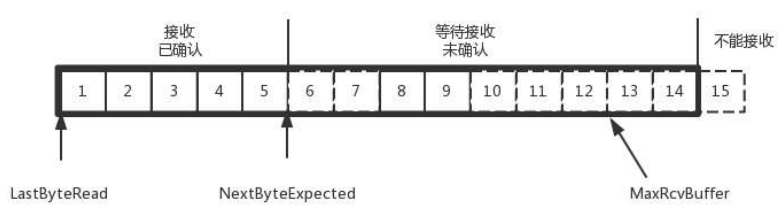
- MaxRcvBuffer:最大缓存量;
- LastByteRead:这个值之后是已经接收,但是还没被应用层读取的;
- NextByteExpected:第一部分和第二部分的分界线,下一个期待的包 ID。
第二部分的窗口有多大呢?
NextByteExpected 和 LastByteRead 的差起始是还没被应用层读取的部分占用掉的 MaxRcvBuffer 的量,我们定义为 A,即:A = NextByteExpected - LastByteRead - 1。
那么,窗口大小,AdvertisedWindow = MaxRcvBuffer - A。
也就是:AdvertisedWindow = MaxRcvBuffer - (NextByteExpected - LastByteRead - 1)
而第二部分和三部分的分界线 = NextByteExpected + AdvertisedWindow - 1 = MaxRcvBuffer + LastByteRead。
顺序与丢包问题
接下来,我们结合上述图例,用一个例子来看下 TCP 如何处理顺序与丢包问题的。
还是刚才的图,在发送端看来:
- 1、2、3 是已经发送并确认的;
- 4、5、6、7、8、9 都是发送未确认的;
- 10、11、12 是还没发出的;
- 13、14、15 是接收方没有空间,不准备发送的。
而在接收端看来:
- 1、2、3、4、5 是已经完成 ACK,但还没读取的;
- 6、7 是等待接收的;
- 8、9 是已经接收,但是没有 ACK 的。
发送端和接收端当前的状态如下:
- 1、2、3 没有问题,双方达成了一致;
- 4、5 接收方发送 ACK 了,但是发送方还没收到,有可能丢了,有可能还在路上;
- 6、7、8、9 肯定都发了,但是 8、9 已经到了,6、7还没打,出现了乱序,于是在缓存中存储,但是没有返回 ACK。
根据这个例子,我们可以知道,顺序问题和丢包问题都有了能发送,所以我们先来看确认与重发的机制。
假设 4 的确认到了,不幸的是,5 的 ACK 丢了,并且 6、7 的数据包也丢了,这时候会怎么处理呢?
一种方法是超时重试,也就是对每一个发送了,但是没有 ACK 的包,都有设一个定时器,一旦超过了一定的时间,就重新尝试。这个超时时间不宜过短,时间必须大于往返时间 RTT,否则就会引起不必要的重传也不宜过长,这样超时时间变长,访问就变慢了。
估计往返时间,需要 TCP 通过采样 RTT 的时间,然后进行加权平均,算出一个值,而且这个值还是要不断变化的,因为网络状况不断的变化。
除了采样 RTT,还要采样 RTT 的波动范围,计算出一个估计的超时时间。由于重传时间是不断变化的,我们称为自适应重传算法(Adaptive Retransmission Algorithm)。
如果过一段时间,5、6、7 都超时了,就会重新发送。接收方发现 5 原来接收过,于是就丢弃5。收到了6,发送 ACK,要求下一个是 7,7 不幸又丢了。
当 7 再次超时的时候,如果有需要重传,TCP 的策略就是超时间隔加倍。每当遇到一次超时重传的实时,都会将下一次超时时间间隔设置为先前值的两倍。两次超时,就说明网络环境差,不宜频繁发送。
可以看出,超时重发存在的问题是,超时周期可能较长。那是不是可以有更快的方式呢?
有一个可以快速重传的机制。当接收方收到一个序号大于下一个所期望的报文段时,就检测到了数据流中的一个间格,于是发送三个冗余的ACK,客户端收到后,就在定时器过期之前,重传丢失的报文段。
例如,接收方发现 6、8、9 都已经接收了,但是 7 没来。于是发送三个 6 的 ACK,要求下一个是 7。客户端收到三个,就会发现 7 的确丢了,不等超时,就马上重发。
除此之外,还有一种方式称为 Selective Acknowledgment(SACK)。这种方式需要在 TCP 头里加一个 SACK 的东西,可以将缓存的地图发格发送方。例如发送 ACK6、SACK8、SACK9,有了地图,发送方一下子就能看出来是 7 丢了,然后快速重发。
流量控制问题
接下来,我们再来看看流量控制机制。在对于包的确认中,会同时携带一个窗口大小的字段。
我们先假设窗口不变的情况,发送端窗口始终为 9。4 的确认来的时候,LastByteAcked 会右移一个,这个时候,第 13 个包就可以发送了。
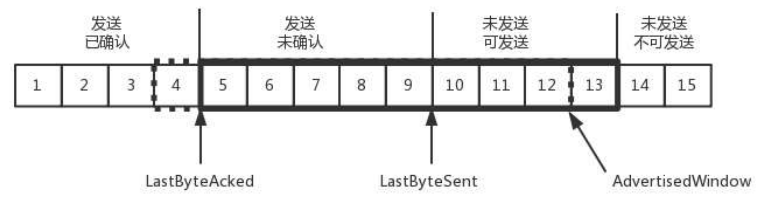
这个时候,假设发送端发送过猛,将第三部分中的 10、11、12、13 全部发送,之后就停止发送,则此时未发送可发送部分为 0。
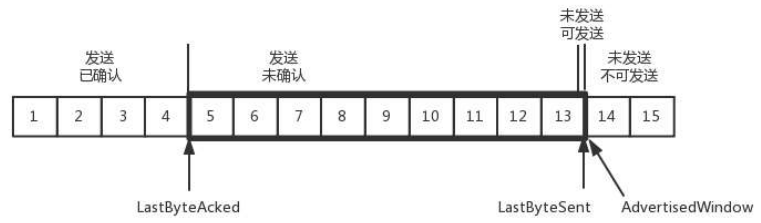
当对于包 5 的确认到达的时候,在客户端相当于窗口再滑动了一格,这个时候,才可以有更多的包可以发送了,例如第 14 个包才可以发送。
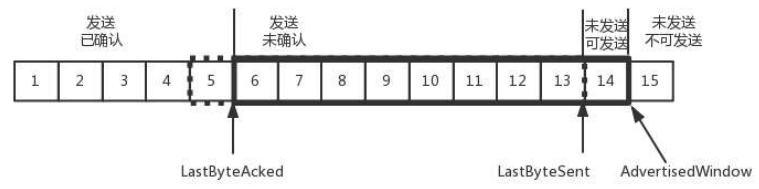
如果接收方处理的太慢,导致缓存中没有空间了,可以通过确认信息修改窗口的大小,甚至可以设置为 0,则发送方将暂时停止发送。
我们可以假设一个极端情况,接收端的应用一直不读取缓存中的数据,当数据包 6 确认后,窗口大小就不会再是 9,而是减少一个变为了 8。

为什么会变为 8?你看,下图中,当 6 的确认消息到达发送端的时候,左边的 LastByteAcked 右移一位,而右边的未发送可发送区域因为已经变为 0,因此左边的 LastByteSend 没有移动,因此,窗口大小就从 9 变成了 8。
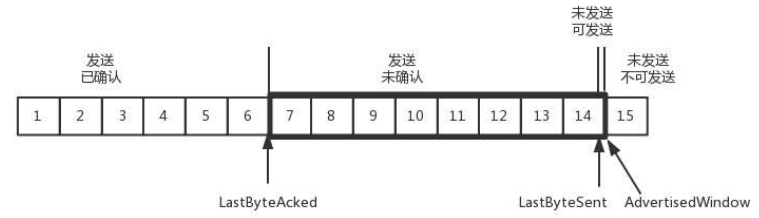
而如果接收端一直不处理数据,则随着确认的包越来越多,窗口越来越小,直到为 0。

当这个窗口大小通过包 14 的确认到达发送端的时候,发送端的窗口也调整为 0,于是,发送端停止发送。
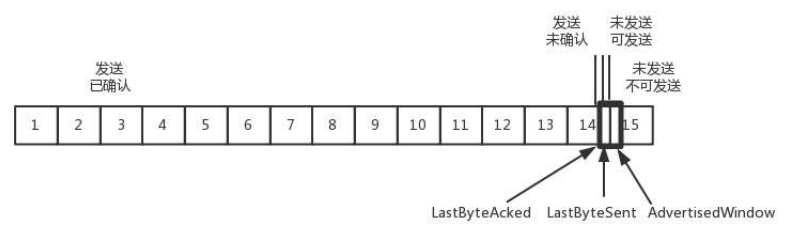
当发生这样的情况时,发送方会定时发送窗口探测数据包,看是否有机会调整窗口的大小。对于接收方来说,当接收比较慢的时候,要防止低能窗口综合征,别空出一个字节就赶紧告诉发送方,结果又被填满了。可以在窗口太小的时候,不更新窗口大小,直到达到一定大小,或者缓冲区一半为空,才更新窗口大小。
这就是我们常说的流量控制。
拥塞控制问题
最后,我们来看一下拥塞控制的问题。
这个问题,也是靠窗口来解决的。前面的滑动窗口 rwnd 是怕发送方把接收方缓存塞满,而拥塞窗口 cwnd,是怕把网络塞满。
这里有一个公式:
LastByteSent - LastByteAcked <= min{cwnd, rwnd}
可以看出,是拥塞窗口和滑动窗口共同控制发送的速度。
那发送方怎么判断网络是不是满呢?这其实是个挺难的事情。因为对于 TCP 协议来讲,它压根不知道整个网络路径都会经历什么。TCP 发送包常被比喻为往一个水管里灌水,而 TCP 的拥塞控制就是在不堵塞、不丢包的情况下,尽量发挥带宽。
水管有粗细,网络有带宽,也就是每秒钟能够发送多少数据;
水管有长度,端到端有时延。在理想情况下:
水管里的水量 = 水管粗细 x 水管长度
而对于网络来讲:
通道的容量 = 带宽 x 往返延迟
如果我们设置发送窗口,使得发送但未确认的包的数量为通道的容量,就能够撑满整个管道。

如上图所示:
假设往返时间为 8s,去 4s,回 4s,每秒发送一个包,每个包 1024 byte。
那么在 8s 后,就发出去了 8 个包。其中前 4 个包已经到达接收端,但是 ACK 还没有返回,不能算发送成功。而 5-8 后四个包还在路上,没被接收。
这个时候,整个管道正好撑满。在发送端,已发送未确认的为 8 个包,也就是:
带宽 = 1024byte/s x 8s(来回时间)
如果我们在这个基础上再调大窗口,使得单位时间内更多的包可以发送,会出现什么现象呢?
原来发送一个包,从一端到另一端,假设一共经过四个设备,每个设备处理一个包耗时 1s,所以到达另一端需要耗费 4s。如果发送的更加快速,则单位时间内,会有更多的包到达这些中间设备,这些设备还是只能每秒处理一个包的话,多出来的包就会被丢弃,这不是我们希望看到的。
这个时候,我们可以想其他的办法。例如,这四个设备本来每秒处理一个包,但是我们在这些设备上加缓存,处理不过来的就在队列里面排着,这样包就不会丢失,但是缺点也是显而易见的,增加了时延。这个缓存的包,4s 肯定到达不了接收端,如果时延达到一定程度,就会超时,这也不是我们希望看到的。
针对上述两种现象:包丢失和超时重传。一旦出现了这些现象就说明,发送速度太快了,要慢一点。但是一开始,发送端怎么知道速度多快呢?怎么知道把窗口调整到合适大小呢?
如果我们通过漏斗往瓶子里灌水,我们就知道,不能一桶水一下子全倒进去,肯定会溢出来。一开始要慢慢的倒,然后发现都能够倒进去,就加快速度。这叫做慢启动。
一个 TCP 连接开始
- cwnd 设置为一个报文段,一次只能发送 1 个;
- 当收到这一个确认的时候,cwnd 加 1,于是一次能够发送 2 个;
- 当这两个包的确认到来的时候,每个确认的 cwnd 加 1,两个确认 cwnd 加 2,于是一次能够发送 4 个;
- 当这四个的确认到来的时候,每个确认 cwnd 加 1,四个确认 cwnd 加 4,于是一次能够发送 8 个。
从上面这个过程可以看出,这是指数性的增长。
但是涨到什么时候是个头呢?一个值 ssthresh 为 65535 个字节,当超过这个值的时候,就会将将增长速度降下来。
此时,每收到一个确认后,cwnd 增加 1/cwnd。一次发送 8 个,当 8 个确认到来的时候,每个确认增加 1/8,8个确认一共增加 1,于是一次就能够发送 9 个,变成了线性增长。
即使增长变成了线性增长,还是会出现“溢出”的情况,出现拥塞。这时候一般就会直接降低倒水的速度,等待溢出的水慢慢渗透下去。
拥塞的一种变现形式是丢包,需要超时重传。这个时候,将 ssthresh 设为 cwnd/2,将 cwnd 设为 1,重新开始慢启动。也就是,一旦超时重传,马上“从零开始”。
很明显,这种方式太激进了,将一个高速的传输速度一下子停了下来,会造成网络卡顿。
前面有提过快速重传算法。当接收端发现丢了一个中间包的时候,发送三次前一个包的 ACK,告诉发送端要赶紧给我发下一个包,别等超时再重传。TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,cwnd 变为 cwnd/2,然后 sshthresh = cwnd。当三个包返回的时候,cwnd = sshthresh + 3。
可以看出这种情况下降速没有那么激进,cwnd 还是在一个比较高的值,呈线性增长。下图是两者的对比。
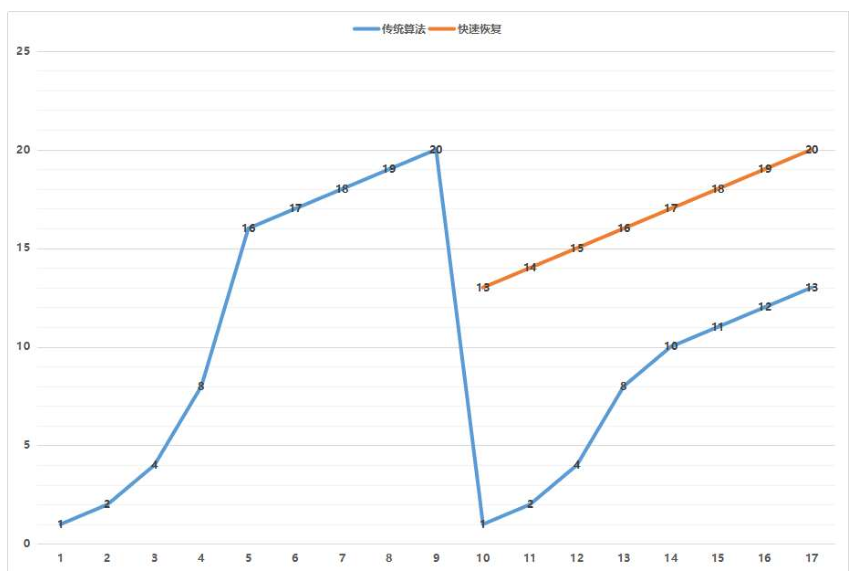
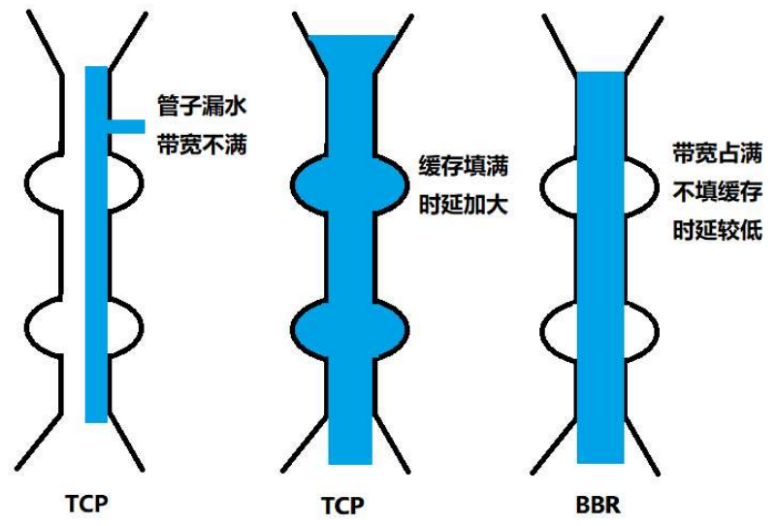
就像前面说的一样,正是这种知进退,使得时延在很重要的情况下,反而降低了速度。但是,我们仔细想一想,TCP 的拥塞控制主要用来避免的两个现象都是有问题的。
第一个问题是丢包。丢包并不一定表示通道满了,也可能是管子本来就”漏水”。就像公网上带宽不满也会丢包,这个时候就认为拥塞,而降低发送速度其实是不对的。
第二个问题是 TCP 的拥塞控制要等到将中间设备都填满了,才发送丢包,从而降低速度。但其实,这时候降低速度已经晚了,在将管道填满后,不应该接着填,直到发生丢包才降速。
为了优化这两个问题,后来就有了 TCP BBR 拥塞算法。它企图找到一个平衡点,就是通过不断的加快发送速度,将管道填满,但是不要填满中间设备的缓存,因为这样时延会增加,在这个平衡点可以很好的达到高带宽和低时延的平衡。
下图是 BBR 算法与普通 TCP 的对比:
小结
- 顺序问题、丢包问题、流量控制都是通过滑动窗口来解决的。这就相当于领导和员工的备忘录,布置过的工作要有编号,干完了有反馈,活不能派太多,也不能太少;
- 拥塞控制是通过拥塞窗口来解决的,相当于往管道里面倒水,快了容易溢出,慢了浪费带宽,要摸着石头过河,找到最优值。
参考:
- The TCP/IP Guide;
- 百度百科 - TCP词条;
- 刘超 - 趣谈网络协议系列课;