OpenMP有三种常见的加锁操作:
critical是OpenMP的指令,它规定其后的代码为临界块,任何时候只允许一个线程访问;
omp_set_lock是OpenMP的库函数,要跟omp_unset_lock一起使用;
atomic也是指令,其后的内存位置将会原子更新
例子:
int main()
{
int i, nVar = 0, n = 5000000;
omp_set_num_threads(4);
clock_t t1, t2;
//critical
t1 = clock();
#pragma omp parallel for shared(nVar)
for (i = 0; i < n; i++)
{
#pragma omp critical
{
nVar += 1;
}
}
t2 = clock();
printf("critical nVar:%d
", nVar);
printf("critical time: %ld ms
", t2 - t1);
printf("---------------
");
//Lock() & Unlock()
nVar = 0;
t1 = clock();
omp_lock_t mylock;
omp_init_lock(&mylock);
#pragma omp parallel for shared(nVar)
for (i = 0; i < n; i++)
{
omp_set_lock(&mylock);
nVar += 1;
omp_unset_lock(&mylock);
}
omp_destroy_lock(&mylock);
t2 = clock();
printf("Lock nVar:%d
", nVar);
printf("Lock time: %ld ms
", t2 - t1);
printf("---------------
");
//atomic
nVar = 0;
t1 = clock();
#pragma omp parallel for shared(nVar)
for (i = 0; i < n; i++)
{
#pragma omp atomic
nVar += 1;
}
t2 = clock();
printf("atomic nVar:%d
", nVar);
printf("atomic time: %ld ms
", t2 - t1);
printf("---------------
");
//normal
nVar = 0;
t1 = clock();
for (i = 0; i < n; i++)
{
nVar += 1;
}
t2 = clock();
printf("normal nVar:%d
", nVar);
printf("normal time: %ld ms
", t2 - t1);
system("pause");
return 0;
}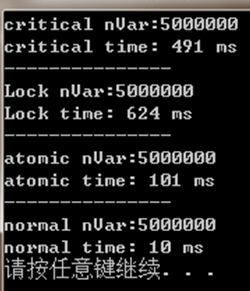
在这个任务里是不并行比并行性能好啊。如果要并行的话,加锁的时候还是atomic的性能好一些。