1.Show and Tell: A Neural Image Caption Generator
Google团队的成果
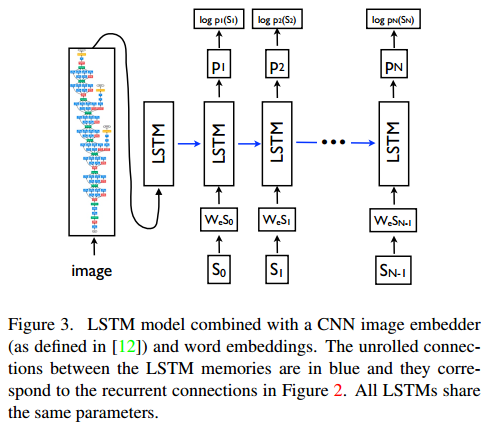
整体处理流程:
1)通过CNN提取到图片的特征,简称feature。
2)而后将feature输入到LSTM中,生成第一个词S0
3)而后每个词Si的生成只需要上一个生成的词Si-1的对应的embedding,直到生成最后一个特殊符号
框架:
生成词的方法
Sampling:softmax取最大值
BeamSearch:每次生成一个单词,保存到目前为止生成的概率最大的K个句子。
实验
作者做了实验在每个时刻生成单词时均喂入image,但是效果较差,是因为网络会利用图片中的噪声,而且很容易过拟合
2.Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Bengio团队的成果
整体处理流程:
1)通过CNN提取的特征,得到a={a1,a2.....an},a1表示不同位置的特征,a1一个D维的特征,D可以理解为channel的个数
2)而后把a和h(t-1)合并,做一个权重化处理,得到z,
3)把z作为lstm的输入,这样在每个词生成的时候,可以关注图像的不同地方。
解码器框架:
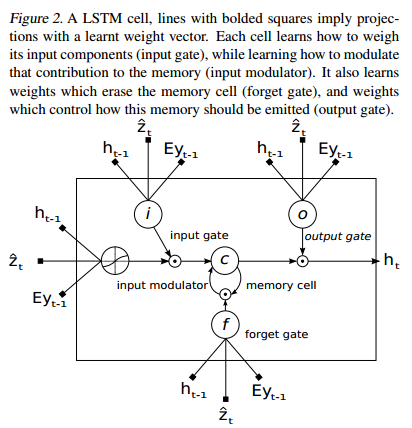
编码器框架和show and tell的框架一样。
两种attention方法
1.Deterministic “Soft” Attention
对CNN生成的整个feature做权重化处理,就是对每个位置ai,softmax(exp(ai)),因此是可以直接求导的,故而这种方法利用的较多。
2.Stochastic “Hard” Attention
随机选择CNN生成的feature的一部分处理,反向传播时需要采用蒙特卡洛方法计算。