第一部分:SQL SERVER是通过哪个组件以及如何来和客户端进行“接受要求”及“提供结果”的交互的
SQL SERVER 服务器于客户端的交互主要依靠Open Data Services(简称ODS)组件,中文名 “开放数据服务”。在《SQL SERVER 2000技术内幕》中,译者将Open Data Services 翻译为“开放式数据服务”,但是这里的OPEN应该意味着“把数据开放”,“开放式”有一点不准确,联系上下文来看的话,无伤大雅。
ODS组件主要负责监听新的连接,清理失败的连接,以及将关系引擎返回的数据集、消息和状态值等信息返回给客户端。ODS组件可以响应一下三种事件:连接事件、语言事件、以及远程存储过程事件。也就是说,当我们打开查询分析器,填好SQL服务器名称,用户名和密码点击确定后,SQL服务器的ODS将触发连接事件进行安全性检查。如果安全性检查能够通过,ODS组件将准许建立连接,其具体的操作就是将在服务器端为客户端分配两个输入缓冲区(读缓冲区)和一个输出缓冲区(写缓冲区)。其中,写缓冲区用于存储关系引擎返回的数据集,当写缓冲被填满(达到4096个字节)或者数据集SQL语句已经执行完毕以后,写缓冲中的数据将被封装成一个TDS包(TDS将在后面详述)通过NET-LIB返回给客户端。ODS维护着与客户端的连接,当客户端断开连接或者意外断网的时候,ODS将负责回收资源,释放为客户端而保持的锁等资源。
这里有一个性能相关的问题大家要注意一下。当关系引擎源源不断地将得到的数据集写入输出缓冲区时,当输出缓冲区被填满而数据集仍然没有返回完毕时,输入缓冲区内的数据将被源源不断地发送到SQL客户端,在这期间,为该SQL客户端而分配的排它锁等资源将一直保持,直到关系引擎返回数据集完毕。这也意味着,当客户端与服务器端之间的网速慢得传输数据出现较大延迟,客户端来不及读取返回数据时,锁将会保留,甚至扫描也将被悬挂,那样SQL服务器将或多或少受到影响。
TDS的全称叫Tabular Data Stream,中文名叫表格数据流。它是SQL 客户端与服务器端用来通信的专用协议。它包含了描述列名称、数据类型、命令(比如中途取消)、各种客户端与服务器“协商”的令牌(就好像IP数据包中包含拥塞控制信息一样)等信息,其包的具体封装结构对我来说是一直还在搜寻的迷,搜了好久都没有看到这方面详细介绍,如果有那位园友有这方面的信息,麻烦告诉我一下。
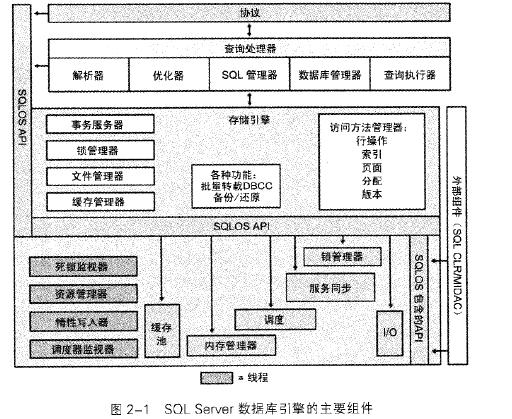
在《SQL SERRVER 2005技术内幕》这一系列的书中,ODS组件没有被提及,体系架构示意图中(后面附图),也不见有ODS组件,不知道是被作者简化掉了,还是作者把ODS组件在SQL 2005中已经并入SQL 管理器,本来想通过作者对ODS组件工作原理的讲解,来窥探DAC的实现原理。结果DAC的实现原理作者也只是说“是一个专门留下来的TDS端点”而一带而过了,实在比较遗憾。
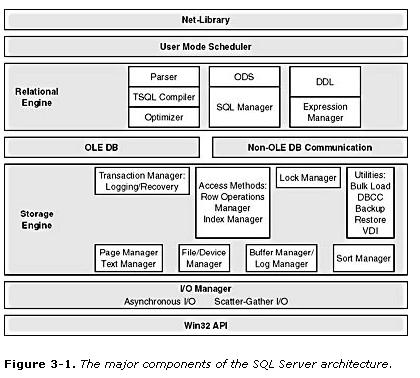
《SQL SERRVER 2000 技术内幕》注:该图片来自于《Microsoft SQL SERVER 2000技术内幕》
《SQL SERVER 2005 技术内幕》 注:该图片来自于《Microsoft SQL SERVER 2005技术内幕-存储引擎》
以上就是SQL客户端与服务器端交互过程的简要介绍,下面我们就来看看查询处理器(关系引擎)对于客户端所提出的要求是如何快速、正确的得到结果的。
第二部分:关系引擎(查询处理器)的工作步骤和原理探讨
概述:
查询处理器又叫关系引擎。关于查询处理器的工作步骤,我画了一个简图,我们结合图形来说。
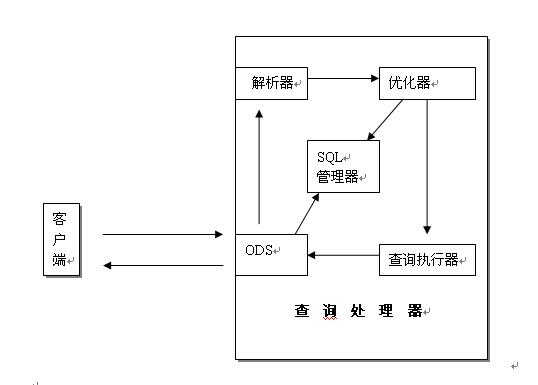
第一步:.当SQL收到一个SQL语句的时候,将首先由SQL管理器进行检查是否缓存有已经编译好的计划
第二步:如果没有,ODS将把SQL语句发给解析器进行解析,生成分析树。
第三步:优化器首先会对解析器生成分析树进行规范化树,规范化树完成后,如果有SQLDML语句,序列树将被转换为查询图形(查询处理器树)。然后优化器将对查询图行树进行优化,并生成最终的执行计划。至此,编译和优化完成。
第四步:查询执行器执行编译好的执行计划,返回行集,并最终由ODS返回给客户端。
下面来详细解析上面的几个步骤
第一步: 客户端发给SQL服务器的SQL语句,确且的说,客户端将SQL语句发给SQL服务器关系引擎的ODS组件,将首先由SQL管理器进行检测该SQL语句是否已经存在于计划缓存中,如果已经存在,SQL管理器将调取缓存的执行计划,交由查询执行器执行;如果没有,SQL语句将由ODS发给解析器进行解析。这里讲一下SQL管理器的职责:SQL管理负责管理存储过程及其计划的所有事情,存储过程是要缓存还是要从缓存中清理掉,是否需要重新编译这些事情。而对于一般的即席查询语句,要进行是否需要参数化,从而可以把这个即席查询当成一个存储过程来对待。
第二步:当ODS把SQL语句发送给解析器后。解析程序将负责分析SQL语句,进行语法验证,并将SQL语句转换成为编译器准备的数据结构。在这个步骤中,解析程序将不负责对查询中涉及到的表或者表的列进行有效性检查;
第三步:这个步骤是最复杂的一步——编译和优化。在拜读了《SQL SERVER 2005技术内幕 T-SQL 》之后,对编译和优化一头雾水,搞不清楚编译是由SQL的哪个组件完成的。很多SQL书籍和资料在讲解编译和优化时只是笼统的说道“SQL生成查询处理器树以后,交由SQL优化器进行查询优化”。其实,SQL语句的编译和优化都是由SQL优化器完成的。为了讲解的方便,我将生成查询处理器树(有的书籍叫查询图形或者查询图形树,总之就是一种适合SQL优化器工作的数据结构)以前的步骤分割为编译,将以后的步骤分割为优化
1. 编译:
对于解析器生成的分析树,SQL优化器将首先对其进行规范化树的操作,在《SQL 2005 技术内幕》中被称为“绑定”。这个步骤具体由一个名叫Algebrizer(SQL 2000叫Normalizer)的组件完成的。这个组件应该是SQL优化器的一个子组件。
Algebrizer首先将对SQL语句进行运算符平展,处理像AND,OR,UNION等这样的二元运算符。
然后进行名称解析,即确定所引用的对象到底时一个表,还是表的一个列、函数、存储过程什么的,如果是视图,会将其替换成视图的定义;还要进行语义的检查。当然,在进行这些引用和绑定之前,SQL是会对这个对象的访问权限进行检测的,如果不具有相关权限,绑定是会失败的,这一点我们可以通过操作来检测:随便新建一个表,然后把某个用户的SELECT权限去掉,写个一查询语句,然后我们“显示估计的执行计划”,很显然,SSMS会返回错误。那么,查询计划具体在执行的时候要不要检测权限呢?很显然也是要检测权限的。试想:如果一个编译好的过程被SQL管理器缓存,如果我们去掉了某个用户对这个过程所涉及的某个表的SELECT权限,那么,这个用户在调用这个过程的时候,这个过程肯定不会被重新编译,如果具体在执行的时候不检测权限,那么这个过程就会被顺利执行,而实际上会因为权限问题而不被执行。而且我在《SQL 2000技术内幕》中找到这样一句话(Part II.Chapter 3.Title:The SQL Server Engine):After normalization and optimization are completed, the normalized tree produced by those processes is compiled into the execution plan, which is actually a data structure. Each command included in it specifies exactly which table will be affected, which indexes will be used (if any), which security checks must be made, and which criteria (such as equality to a specified value) must evaluate to TRUE for selection. 译文:在规范化树和优化结束之后,其生成的规范化树将被引用并编译到执行计划中,执行计划实际上就是一种数据结构。它准确指出了其所包含的每一个命令将影响哪个表,如果需要的话将使用哪个索引,哪些安全性特性将必须被检查以及哪一个用于筛选的条件(例如等于一个特定的值)将必须为真。
Algebrizer的名称解析步骤完成以后,还要进行类型派生,聚合绑定,分组绑定等几个步骤。对于这几个步骤,没有做太多深入的思考,也就暂时没有疑问,我就不详细深入(也做不了详细深入的)的讲解了。
(注:个人认为Algebrizer的工作原理是一个非常需要深入了解的部分,但是可能由于专利等原因,《SQL SERVER 2005技术内幕》对它的讲解还不够深入,而且我也花了很多时间GO0GLE,也没什么大的收获)
编译的最终结果将生成查询图形(查询处理器树),然后优化器会对其进行优化。
2.优化
优化也是一个复杂的过程。剩下的内容下回再写。我将在下一篇文章中详细的阐述优化器的优化步骤及其相关信息。这里先写一下下一篇文章的提纲:
a. 优化器的工作步骤。
b. 对优化的三个主要阶段(查询分析、索引选择、连接选择)分别做一个较为深入的阐述。
出处:http://www.cnblogs.com/zhouqiang52154/archive/2008/12/28/1363826.html