aggregateByKey:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object TransformationsDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("TransformationsDemo").master("local[1]").getOrCreate()
val sc = sparkSession.sparkContext
testAggregateByKey(sc)
}
private def testAggregateByKey(sc: SparkContext) = {
var data = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),1)
def seq(a:Int, b:Int) : Int ={
println("seq: " + a + " " + b)
math.max(a,b)
}
def comb(a:Int, b:Int) : Int ={
println("comb: " + a + " " + b)
a + b
}
data.aggregateByKey(0)(seq, comb).collect.foreach(println)
}
}
运行结果:
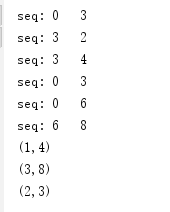
运行结果分析:
根据Key值的不同,可以分为3个组:
(1) (1,3),(1,2),(1,4);
(2) (2,3);
(3) (3,6),(3,8)。
这3个组分别进行seqOp,也就是(K,V)里面的V和0进行math.max()运算,运算结果和下一个V继续运算,以第一个组为例,运算过程是这样的:
0, 3 => 3
3, 2 => 3
3, 4 => 4
所以最终结果是(1,4)。
第二组结果是(2,3)。
第三组结果是(3,8)。
combOp是对把各分区的V加起来,由于这里并没有分区,所以实际上是不起作用的。
修改下代码,添加分区:
private def testAggregateByKey(sc: SparkContext) = {
var data = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
def seq(a:Int, b:Int) : Int ={
println("seq: " + a + " " + b)
math.max(a,b)
}
def comb(a:Int, b:Int) : Int ={
println("comb: " + a + " " + b)
a + b
}
data.aggregateByKey(0)(seq, comb).collect.foreach(println)
}
运行结果:

运行结果分析:
根据Key值的不同,可以分为3个区:
(1) (1,3),(1,2);
(2) (1,4),(2,3);
(3) (3,6),(3,8)。
区内先做求最大值
第一组结果是(1,3)。
第二组结果是(1,4),(2,3)。
第三组结果是(3,8)。
combOp是对把各分区的V加起来,由于此次有分区,所以(1,3)和(1,4),做合并操作,结果:(1, 7)。