union/intersection/subtract:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object TransformationsDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("TransformationsDemo").master("local[1]").getOrCreate()
val sc = sparkSession.sparkContext
testUnion(sc)
testIntersection(sc)
testSubtract(sc)
}
private def testSubtract(sc: SparkContext) = {
val rdd1 = sc.parallelize(1 to 3, 1)
val rdd2 = sc.parallelize(3 to 5, 1)
//返回在当前RDD中出现,并且不在另一个RDD中出现的元素,不去重。
rdd1.subtract(rdd2).collect().foreach(println)
println(s"partitions: ${rdd1.subtract(rdd2, 1).partitions.size}")
println(s"partitions: ${rdd1.subtract(rdd2, 2).partitions.size}")
val rdd3 = sc.parallelize(List(List(1, 2, 3), List(4, 5, 6)), 1)
val rdd4 = sc.parallelize(List(List(4, 5, 6), List(7, 8, 9)), 1)
rdd3.subtract(rdd4).collect().foreach(println)
}
private def testIntersection(sc: SparkContext) = {
val rdd1 = sc.parallelize(1 to 2, 1)
val rdd2 = sc.parallelize(3 to 5, 1)
//返回两个RDD的交集,并且去重。
rdd1.intersection(rdd2).collect().foreach(println)
println(s"partitions: ${rdd1.intersection(rdd2, 1).partitions.size}")
println(s"partitions: ${rdd1.intersection(rdd2, 2).partitions.size}")
val rdd3 = sc.parallelize(List(List(1, 2, 3), List(4, 5, 6)), 1)
val rdd4 = sc.parallelize(List(List(4, 5, 6), List(7, 8, 9)), 1)
rdd3.intersection(rdd4).collect().foreach(println)
}
private def testUnion(sc: SparkContext) = {
val rdd1 = sc.parallelize(1 to 3, 1)
val rdd2 = sc.parallelize(3 to 5, 1)
//将两个RDD进行合并,不去重。
rdd1.union(rdd2).collect().foreach(println)
val rdd3 = sc.parallelize(List(List(1, 2, 3), List(4, 5, 6)), 1)
val rdd4 = sc.parallelize(List(List(4, 5, 6), List(7, 8, 9)), 1)
rdd3.union(rdd4).collect().foreach(println)
}
}
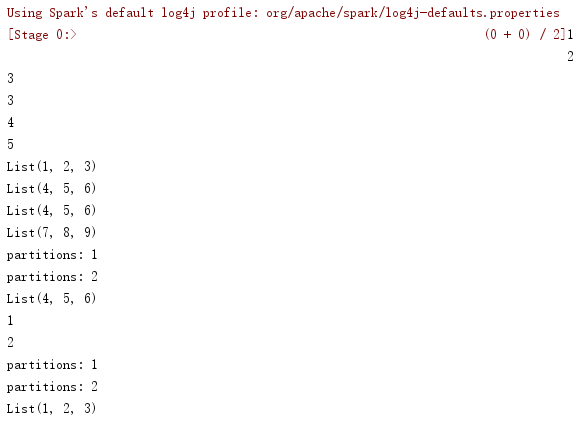
运行结果: