| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2/homework/11169 |
| 作业目标 | <学会从有多层嵌套内容的长文本中获取自己想要的信息> |
| 作业源代码 | https://gitee.com/houdini/personal |
| 学号 | <211806327> |
1、时间记录
- 代码行数:107行
- 分析时间:2h
- 编码时间:2.5h
2、分解需求思路
首先,我的思路是逆过来的
一、获取经验值
在看到了题目后,知道要从一大段长文本中获取经验值,我马上就想到了正则表达式
以及其中所包含的两种情况
第一种,普通的经验值用"^d+ 经验$"

以及第二种,特殊的情况,互评的经验值,"^互评 d+ 经验$"

然后通过上述的正则表达式获得图里的“XX 经验”和“互评 XX 经验”的String文本,再又一次通过正则表达式获得这个字符串的数字,也就是我们需要的经验值
二、分类
从同学们那看到,大家都用在Jsoup来处理html的源码内容,经过观察后,我发现所有的经验值都是在一个类名为"interaction-row"的div块下
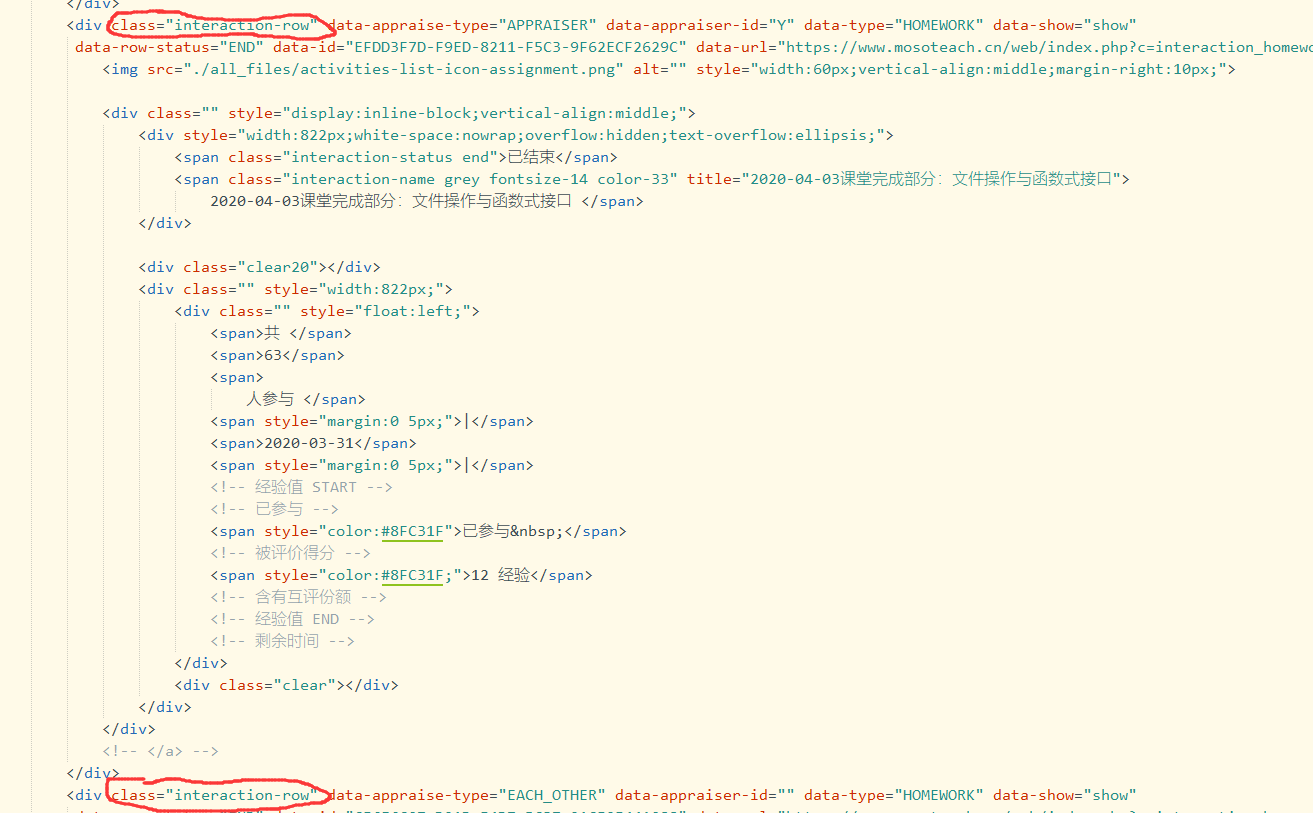
只要通过它的getElementsByClass方法就可以获得一个个div块
但其中又存在问题,会有好几个小div块合在一起,会出现漏算分数的情况
Document file = Jsoup.parse(new File("small.html"),"UTF-8");
Document file1 = Jsoup.parse(new File("all.html"),"UTF-8");
Elements exps = file.getElementsByClass("interaction-rows");
exps.addAll(file1.getElementsByClass("interaction-row"));
Properties all = new Properties();
all.load(new FileInputStream("total.properties"));
//遍历出通过利用类名来筛选、分割后的一个个小div块
for(Element p:exps) {
System.out.println(p);
System.out.println("------");
}
正如上述代码运行后,下图所示,本该会出现分割线的地方不会有分割线
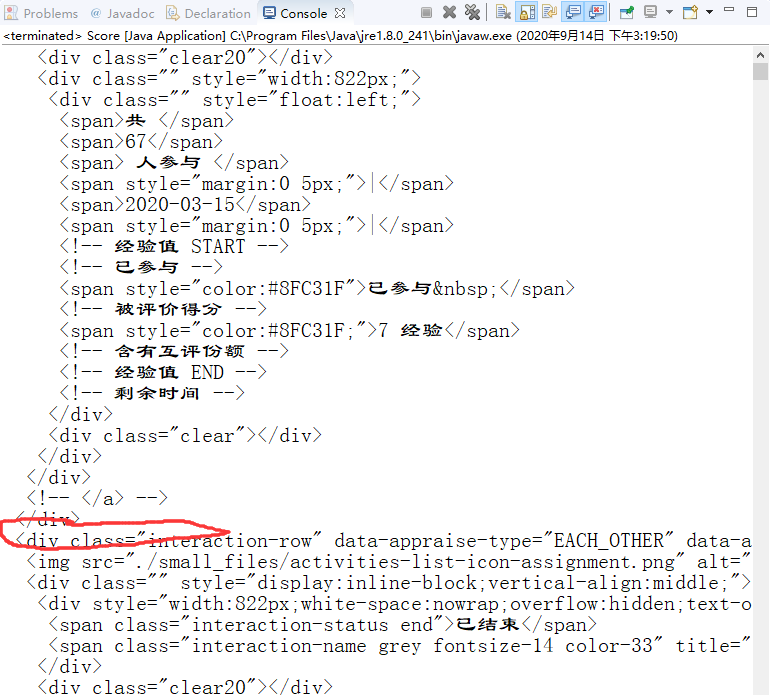
所以我想进行进一步的分类
而机缘巧合中,我把题目看错了,看成了只有①“编程题、附加题”②“课堂完成部分、课堂小测”③“课前自测”这三种经验值的计算方式
所以我找到了这三种它们的特点
①“编程题、附加题”
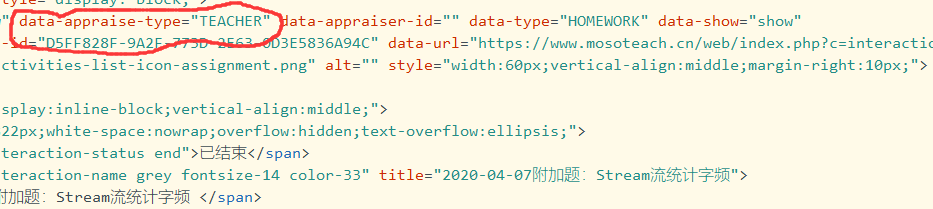

查询了Jsoup的在线API后,我用了select("[data-appraise-type=TEACHER]")来进行再次分类
②“课堂完成部分、课堂小测”
身为上学期的助教,这部分我马上想到了,上学期老师都是让我们助教帮忙改,或者,让我们同学直接互改,所以仔细找后
我发现了以下两种特点来进一步分类
data-appraise-type="APPRAISER"、data-appraise-type="EACH_OTHER"
③“课前自测”
而自测就很简单了,是通过问答的形式来进行的
data-type="QUIZ"
但问答形式进行的还有一个“课堂提问”,所以用contains方法获得“自测”的
而到这,我再看一次题目的计算公式时,我才发现之前的错误,打算一错就错,先写下去,后面再优化
就将小div块,转换成String字符串,再通过contains方法,通过其中是否包含"编程"、"完成"、"附加"、"小测"、"自测"来完成最后的分类
最后再通过我一开始就想出来的正则表达式方法来获得经验值
疑惑
这时,我就来着手优化了,我的打算是,通过类名分类后,直接通过cotains方法来再分类,比原本少了一步
结果这结果让我大吃一惊,竟然比优化前的运行结算足足少了40分,两次运行结果如下
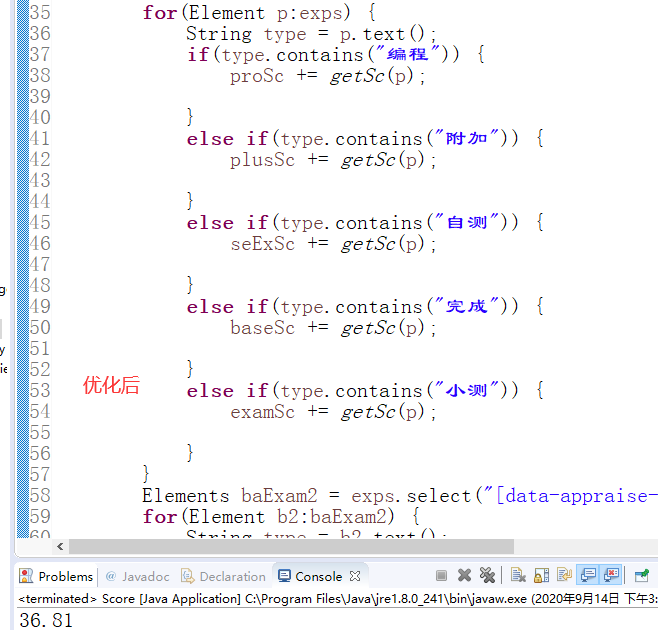

于是我将通过contains步骤中都加入一个计数变量
惊讶地发现
for(Element p:exps) {
String type = p.text();
if(type.contains("编程")) {
proSc += getSc(p);
a++;
}
else if(type.contains("附加")) {
plusSc += getSc(p);
b++;
}
else if(type.contains("自测")) {
seExSc += getSc(p);
c++;
}
else if(type.contains("完成")) {
baseSc += getSc(p);
d++;
}
else if(type.contains("小测")) {
examSc += getSc(p);
e++;
}
}
System.out.println(a+" "+b+" "+c+" "+d+" "+e);

竟然漏了好多个活动的经验值!!!
然后我再一一遍历出计数变量有值的那几个,发现其中好多小div块连在了一起!!!!
就是写优化前,上文中我提到的,通过类名分割后,我发现还是好多小div块连到一起的状况
而更奇怪的是,我把优化前的代码进行遍历输出后,发现每一个小div块都是分开的,并没有连在一起
这个问题我到现在还没有头绪,所以只能保留优化前的代码,希望助教或者老师能帮我解答下,谢谢。
3、参考资料
Jsoup的在线API:https://jsoup.org/apidocs/
Jar包的导入: https://blog.csdn.net/liangayang/article/details/80683384
jdk api 1.8版