写在最前面:
基于以下的测试,在搜索时应该这么做:
百度搜索框:关键词 url:zhihu.com
谷歌搜索框:关键词 url:zhihu.com
以上两种要结合使用,单独使用可能效果不佳。
同样适用于bilibili.com,blog.sina.com.cn,bbs.hupu.com,tianya.cn, tieba.baidu.com以及52pojie.cn等等。
一、以搜索“姬无命”为例——站内搜索与通用搜索之争
PC端目前有三类四种知乎搜索的方法:
(注:手机端微信内支持知乎搜索。)
第一类自然是知乎网页内部直接搜索(zhihu.com)
第一类是:搜狗知乎搜索(https://zhihu.sogou.com/)
第二类是:主流搜索引擎的站点内搜索。
一是百度:如搜索框:姬无命 site:zhihu.com
百度可以不用输“site:XX.com”搜索框下边就是搜索工具。谷歌没有单列出搜索工具,需要添上。
二是谷歌:如搜索框:姬无命 site:zhihu.com
以下对4种方式进行对比,关键词是“姬无命”
百度搜索:
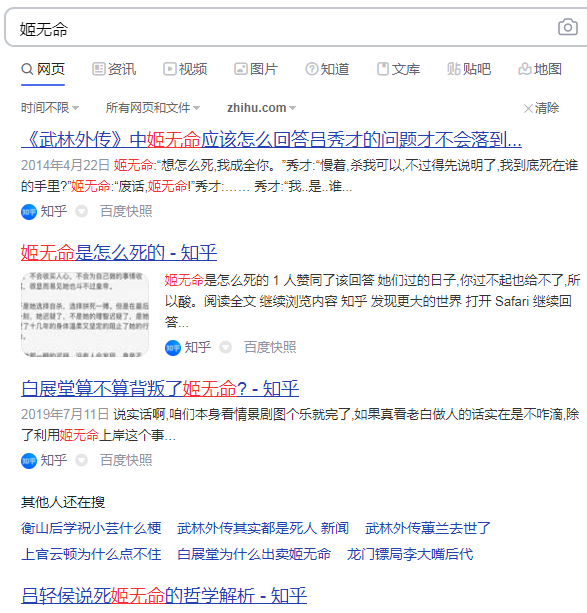

搜索结果多达76页,按每页10个条目计那就是760个搜索结果。基本是涉及到完整的“姬无命”的回答都出现了一次。
谷歌搜索结果:
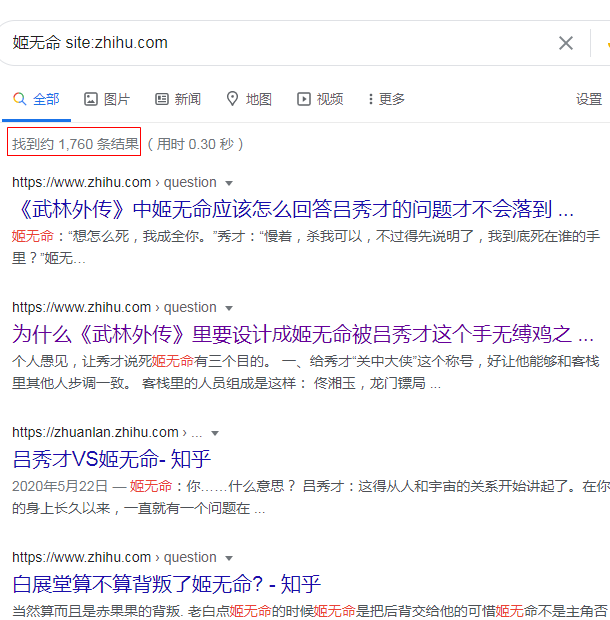
共28页的1760条结果
知乎内部搜索结果:
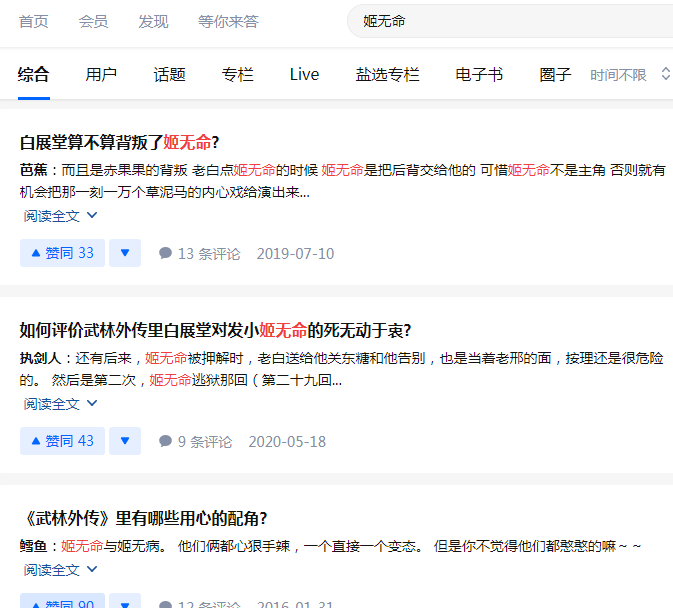
不显示条目数,目测应当是最多的。
可以看得出知乎本身搜索与搜狗知乎搜索结果并不重合。
评价搜索的好坏包括两个问题:搜索结果和结果排序。这两问题都属于搜索算法。
最终结论:谷歌站内搜索≈百度站内搜索>搜狗知乎搜索>知乎内部搜索。
二、关于搜索、知乎搜索
一次搜索流程主要包括 Query 解析、召回、排序几个阶段。
用户输入 Query 之后,首先要进行 Query 解析,生成查询 Query Tree 和语义表示向量。之后进入多队列的召回模块,召回阶段从召回方式上说可以分为倒排召回和向量召回,在这一环节会筛选出前400的文档进入到排序阶段。排序阶段又分为精排和重排序两个环节,精排阶段通过模型对多召回源的文档进行统一打分,之后将 Top16的文档送入重排序模型进行位置的微调,最终呈现给用户。
以上每一个阶段都是很重要的,算法的好坏决定了最终你阅读到搜索内容的相关程度和满意度。
搜索是技术方向辐射相当广的一个复杂系统,其技术门槛之高,在众多的互联网产品中能与搜索比肩的是少之又少。要想玩转这套系统,拥有一批最优秀且懂搜索的工程师和研究员是必不可少的。想解决的话,知乎可能需要5个熟练工干大半年。在我看来,这种团队配置作为站内搜索差不多能解决大部分基础问题,即达到不被“到处”抱怨。但如果要求再高一点点,能稍”智能”地处理用户查询,那么这种团队配置恐怕还是望成莫及。
当然搜索也绝不仅仅是一个人力问题,支撑搜索的人工智能技术正在”经验主义”(以统计学为代表)的道路上享受着大数据(特别是用户行为数据)的红利。
从一个特定站点出发,即使是一个格调高、深受用户喜爱的站点,其能够接触到的数据无论是用户群体行为数据还是全网的信息资源都是十分有限的。
用户对于全网通用搜索和站内搜索的期望的差别仅在于搜索范围从全网变为这个特定站点,但搜索用户天生的”懒惰”、表达含糊以及对搜索结果智能的期待从未改变过。而且由于用户对他所喜爱的站点的了解、熟悉程度远远超出其对全网的了解,所以用户对搜索服务所存在的各种问题更为敏感,从而也有更高的要求。
正是这种数据局限所带来的技术水平局限与用户需求之间的矛盾,使得原生站内搜索注定就是一件不太可能成功的路。
为什么知乎站内搜索没有通用搜索(例如百度、搜狗)的site查询好用?
知乎搜索体验不理想,存在多种问题,但这些问题绝不是知乎仅有的问题,也不仅仅是人力投入的问题。
搜索一个异常复杂的系统,好的搜索体验需要技术的沉淀与积累,需要海量数据特别是海量用户行为数据的支撑。
站内搜索就于其在搜索方向的积累、其能接触到的数据,像知乎这样面对高标准严要求的用户,注定不易做到用户满意。
知乎官方搜索负责人也解释过为什么没有接入 SITE(通用引擎的站内搜索)
尽管线上问题很多,解决起来也不容易,但考虑从知乎搜索能到达的理想状态,我们仍然不甘心简单接入一个 SITE 语法搭建的站内搜索了事。
一个重要原因是,知乎搜索是贯穿整个知乎平台的重要基础功能。搜索对于整个产品的效率都有很大影响。
另外一个重要的原因是:知乎的内容不仅仅是一个个网页。知乎上用户与内容之间丰富的互动信息可以帮助搜索引擎识别哪些内容更为重要,数据富集度和准确度远远高于[PageRank],同时,知乎的内容天然有人的属性,而这应该被用来满足知乎特有的搜索需求。比如:
个性化-与你相关的内容可以有更好的排序,你曾看过的、点过赞同反对的、关注过的话题里的内容等,搜起来应该更容易。
社会化-你关注的圈子中用户的赞同、反对、感谢和评论可以更好的帮助你定位你找的内容。
通用引擎的站内搜索确实能简单快速解决目前很多的搜索痛点问题。但对知乎来说它是没有生命力,或者说提高空间非常有限的。我们希望知乎上的内容能被更好的搜索,知乎独有的用户需求能被更好的满足,所以我们并没有选择这个明显更为容易,也是一部分网友建议的方案。
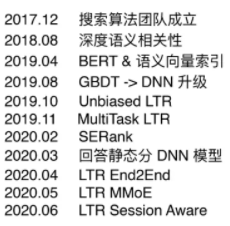
关于 知乎内部 搜索的发展历程,如下:
参考:
为什么知乎的搜索功能如此之烂? - 张前川的回答 - 知乎
https://www.zhihu.com/question/26617244/answer/70731152
为什么知乎的搜索功能如此之烂? - 许静芳的回答 - 知乎
https://www.zhihu.com/question/26617244/answer/70802668
知乎搜索排序模型的演进
https://mp.weixin.qq.com/s/DZZ_BCiNw0EZg7V0KvhXVw
知乎搜索文本相关性与知识蒸馏
https://mp.weixin.qq.com/s/xgCtgEMRZ1VgzRZWjYIjTQ