一,数据存储介绍
1.操作系统获得存储空间的方式一般分为:
① 外接活动硬盘 (DAS)
② 网络存储服务器 (NAS)
③ 存储区域网路服务 (SAN)
(1) DAS:(Direct Attached Storage— 直接连接存储)
本地存储设备: 通过某种协议(SAS,SCSI,SAN,iSCSI 等)挂接裸硬盘,然后分区、 格式化、创建文件系统;或者直接使用裸硬盘存储数据(数据库)。这种裸硬盘 的方式叫做 Block Storage(块存储),每个裸硬盘通常也称作 Volume(卷)
(2) NAS:(Network attched storage 网附加存储)
这种叫做文件系统存储。NAS 和 NFS 服务器,以及各种分布式文件系统提供的 都是这种存储。 NAS 实际上就是一部 File Server, 一般以NFS,SAMBA,FTP,HTTP 作为服务器,来完 成存储或读取的主要方式。 当前主要的 NAS 软件可以用 FreeNAS 来进行配置和完成。通过 WEB 界面直接进 行控制,方便、简单、快捷不用专业 IT 人员进行完成。客户端通过 NFS、CIFS 等 协议,mount 远程的文件系统。
(3) SAN:(Storage Area Networ, 存储区域网络 )
如果拥有大量的硬盘或使用空间,但主机插槽不够,可以使用 SAN 。一般可以 将 SAN 视为一个外接式的存储设备 .SAN可以通过某些特殊的方式或介质来提供 网络内的主机进行资料的存储。 简单来说 SAN 即通过光纤通道连接到一群计算机上。在该网络中提供了多主机 连接,但并非通过标准的网络拓扑。SAN 的结构允许任何服务器连接到任何存 储阵列,这样不管数据置放在那里,服务器都可直接存取所需的数据。因为采 用了光纤接口, SAN 还具有更高的带宽。
2.DAS,SAN,NAS 三种服务器存储方式应用
1.应用:
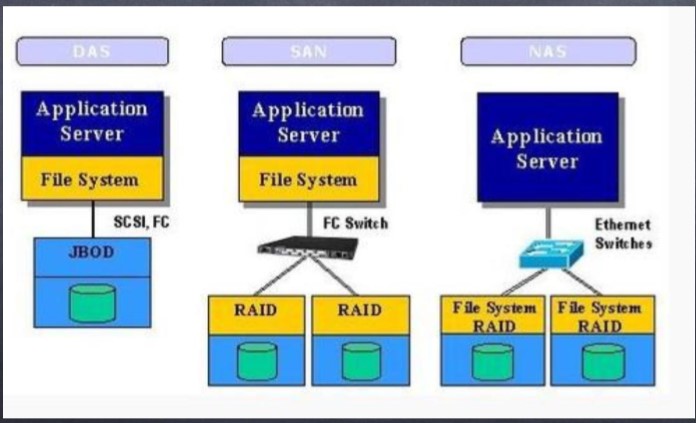
DAS存储一般应用在中小企业,与计算机采用直连方式,NAS存储则通过以太网 添加到计算机上,SAN存储则使用FC接口,提供性能更加的存储。NAS与NAS的 主要区别体现在操作系统在什么位置,如图所示
3. DAS, NAS,SAN 的区别
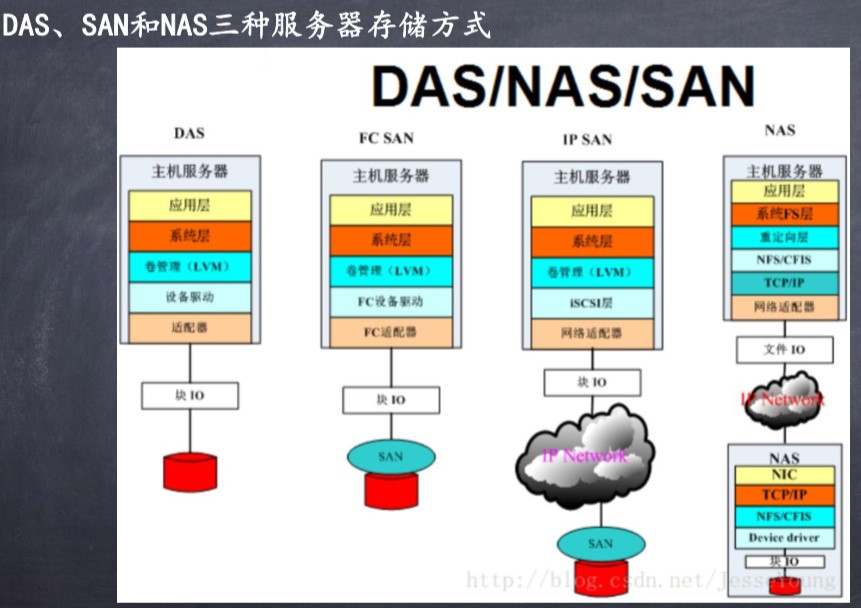
目前服务器所使用的专业存储方案有DAS、NAS、SAN、iSCSI几种。存储根据服务器类型可以分为:封闭系统的存储和开放系统的存储:
(1)封闭系统主要指大型机.
(2)开放系统指基于包括Windows、UNIX、Linux等操作系统的服务器; 开放系统的存储分为:内置存储和外挂存储;
(3)开放系统的外挂存储根据连接的方式分为:
直连式存储(DAS:Direct-Attached Storage)和网络化存储(Fabric-Attached Storage:FAS)
(4)开放系统的网络化存储根据传输协议又分为:
NAS:Network-Attached Storage和SAN:Storage Area Network。由于目前绝大部分用户采用的是开放系统,其外挂存储占有目前磁盘存储市场的70%以上.
SAN 结构中,文件管理系统(FS)还是分别在每一个应用服务器上;而 NAS则是每个应用服务器通过网络共享协议(如:NFS ,CIFS)使用同一个文件管理系统。 也就是说,NAS和SAN 存储系统的区别是NAS有自己的文件管理系统。
4.缺点
DAS的不足之处:
(1)服务器本身容易成为系统瓶颈;
直连式存储与服务器主机之间的连接通道通常采用SCSI连接,带宽为10MB/s、20MB/s、40MB/s、80MB/s等,随着服务器CPU的处理能力越来越强,存储硬盘空间越来越大,阵列的硬盘数量越来越多,SCSI通道将会成为IO瓶颈;服务器主机SCSI ID资源有限,能够建立的SCSI通道连接有限。
(2)服务器发生故障,数据不可访问;
(3)对于存在多个服务器的系统来说,设备分散,不便管理。同时多台服务器使用DAS时,存储空间不能在服务器之间动态分配,可能造成相当的资源浪费;
(4)数据备份操作复杂。
NAS存在的主要问题是:
(1)由于存储数据通过普通数据网络传输,因此易受网络上其它流量的影响。当网络上有其它大数据流量时会严重影响系统性能;
(2)由于存储数据通过普通数据网络传输,因此容易产生数据泄漏等安全问题;
(3)存储只能以文件方式访问,而不能像普通文件系统一样直接访问物理数据块,因此会在某些情况下严重影响系统效率,比如大型数据库就不能使用NAS。
SAN作为一种新兴的存储方式,是未来存储技术的发展方向,但是,它也存在一些缺点:
(1)价格昂贵。不论是SAN阵列柜还是SAN必须的光纤通道交换机价格都是十分昂贵的,就连服务器上使用的光通道卡的价格也是不容易被小型商业企业所接受的;
(2)需要单独建立光纤网络,异地扩展比较困难;
二 ,存储方案-----ISCSI
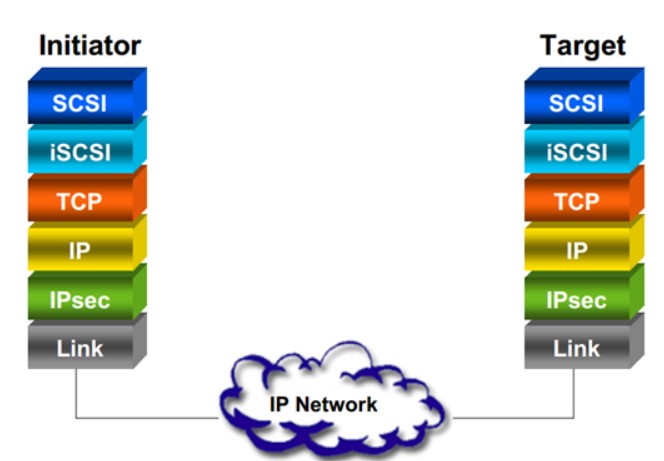
iSCSI是由Cisco和IBM发起的,它将SCSI命令封装在TCP/IP包里,并使用一个iSCSI帧头。它基于IP协议栈,假设以不可靠的网络为基础,依靠TCP恢复丢失的数据包
背景:
相比直连存储,网络存储解决方案能够更加有效地共享,整合和管理资源。从服务器为中心的存储转向网络存储,一直依赖于数据传输技术的发展,速度要求与直连存储相当,甚至更高,同事需要克服并行SCSI固有的局限性。
所有数据在没有文件系统格式化的情况下,都以块的形式存储于磁盘上。并行SCSI将数据以块的形式传送至存储,但是,对于网络它的用处相当有限,因为线缆不能超过25m,而且最多连接16个设备;
2.ISCSI 架构
1) 存储设备 (iSCSI target): 存放硬盘和 RAID 设备
2) 主机部分 (iSCSI initiator): 使用存储设备的客户端(即连接到 iscsi 的服务器 )

iSCSI是一种使用TCP/IP协议,在现有IP网络上传输SCSI块命令的工业标准,它是一种在现有的IP网络上无需安装单独的光纤网络即可同时传输消息和块数据的突破性技术。iSCSI基于应用非常广泛的TCP/IP协议,将SCSI命令/数据块封装为iSCSI包,再封装至TCP 报文,然后封装到IP 报文中。iSCSI通过TCP面向连接的协议来保护数据块的可靠交付。由于iSCSI基于IP协议栈,因此可以在标准以太网设备上通过路由或交换机来传输
3.iSCSI SAN概念解析:
包括以下部件:
iSCSI Client/Host:
系统中的iSCSI客户端或主机(也称为iSCSI initiator),诸如服务器,连接在IP网络并对iSCSI target发起请求以及接收响应。每一个iSCSI主机通过唯一的IQN来识别,类似于光纤通道的WWN。
要在IP网络上传递SCSI块命令,必须在iSCSI主机上安装iSCSI驱动。推荐通过GE适配器(每秒1000 megabits)连接至iSCSI target。如同标准10/100适配器,大多数Gigabit适配器使用Category 5 或Category 6E线缆。适配器上的各端口通过唯一的IP地址来识别。
iSCSI Target:
iSCSI target是接收iSCSI命令的设备。此设备可以是终端节点,如存储设备,或是中间设备,如IP和光纤设备之间的连接桥。每一个iSCSI target通过唯一的IQN来标识,存储阵列控制器上(或桥接器上)的各端口通过一个或多个IP地址来标识。
本机与异构IP SAN:
iSCSI initiator与iSCSI target之间的关系如图1所示。
本例中,iSCSI initiator(或client)是主机服务器,而iSCSI target是存储阵列。此拓扑称为本机iSCSI SAN,它包含在TCP/IP上传输SCSI协议的整个组件。
4.iscsi 协议
iSCSI协议是让SCSI在TCP协议之上工作的传输协议,是一种SCSI远程过程调用模型到TCP协议的映射。SCSI命令加载在iSCSI请求之上,同时SCSI状态和响应也由iSCSI来承载。iSCSI同样使用请求响应机制。
在iSCSI 配置中,iSCSI 主机或服务器将请求发送到节点。 主机包含一个或多个连接到IP 网络的启动器,以发出请求,并接收来自iSCSI 目标的响应。
每个启动器和目标都指定了一个唯一的iSCSI 名称,如 iSCSI 限定名 (IQN) 或扩展的唯一标识(EUI)。 IQN 是 223 字节的 ASCII 名称。EUI 是 64 位标识。iSCSI 名称代表全球唯一命名方案,该方案用于标识各启动器或目标,其方式与使用全球节点名(WWNN) 来标识光纤通道光纤网中设备的方式相同
iSCSI有两大主要网络组件。
第一个是网络团体,网络团体表现为可通过IP网络访问的一个驱动或者网关。一个网络团体必须有一个或者多个网络入口,每一个都可以使用,通过IP网络访问到一些iSCSI节点包含在网络团体中。
第二个是网络入口,网络入口是一个网络团队的组件,有一个TCP/IP的网络地址可以使用给一个iSCSI节点,在一个ISCSI会话中提供连接。一个网络入口在启动设备中间被识别为一个IP地址。一个网络入口在目标设备被识别为一个IP地址+监听端口。
iSCSI支持同一会话中的多个连接。在一些实现中也可以做到同一会话中跨网络端口组合连接。端口组定义了一个iSCSI节点内的一系列网络端口,提供跨越端口的会话连接支持。
三.储存方案——GFS
1.概括
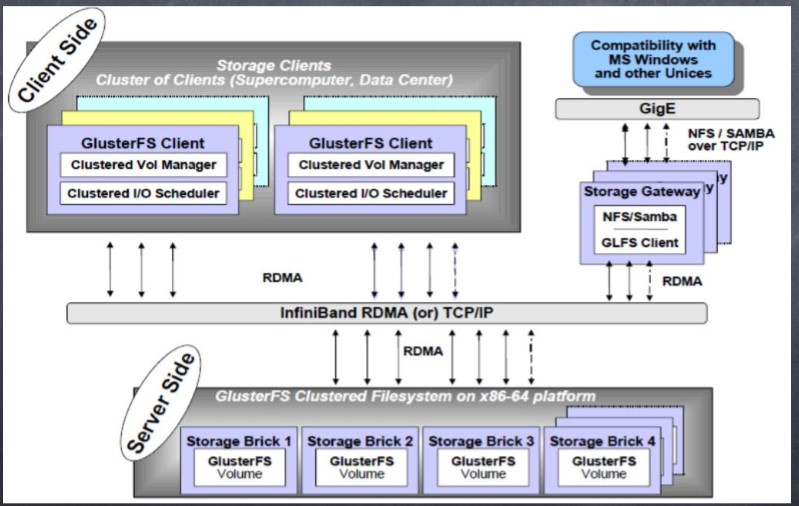
GFS: Goole FS—google 文件系统 , 又称为 GlusterFS 。属于可扩展的分布式文件系统。 主要用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普 通硬件上,并提供容错功能。它可以给大量的用户提供总体性能较高的服务
GFS: 属于 Scale-Out( 横向扩展 ) 存储解决方案Gluster 的核心,它是一个开源的分 布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数 PB 存储容量和 处理数千客户端。 GlusterFS 借助 TCP/IP 或 InfiniBand RDMA 网络将物理分布 的存储资源聚集在一起,使用单一全局命名空间来管理数据。 GlusterFS 基于可 堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
①Scale Out( 横向扩展 ) :
从字面意思来看, Scale Out 是使用靠增加处理器来提升运算能力和增加独立服 务器来增加运算能力。就是指企业可以根据需求增加不同的服务器和存储应用, 依靠多部服务器、存储协同运算,借负载平衡及容错等功能来提高运算能力及 可靠度。
②Scale Up( 纵向扩展 )
指企业后端大型服务器以增加处理器等运算资源进行升级以获得对应用性能的 要求,但是更大更强的服务器同时也是更昂贵的,往往成本会大于部署大量相 对便宜的服务器来实现性能的提升,这当中的代表当属 IBM zSeries 大型机。而 且服务器性能所能提高的程度也有一定的上限。
GFS 架构为组成不同的数据负载提供优异的性能。
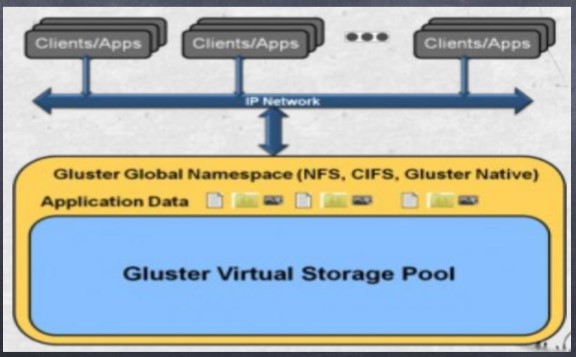
GFS支持运行在任何标准 IP 网络上标准应用程序的标准客户端,用户可以在全 局统一的命名空间中使用 NFS/CIFS 等标准协议来访问应用数据。 GlusterFS 使得 用户可摆脱原有的独立、高成本的封闭存储系统,能够利用普通廉价的存储设 备来部署可集中管理、横向扩展、虚拟化的存储池,存储容量可扩展至 TB/PB 级
2.特点
1. 扩展性和高性能
GlusterFS 利用双重特性来提供几 TB 至数 PB的高扩展存储解决方案。 ScaleOut 架构允许通过简单地增加资源来提高存储容量和性能,磁盘、计算和 I/O 资 源都可以独立增加,支持 10GbE 和InfiniBand 等高速网络互联。 Gluster 弹性哈 希( Elastic Hash )解除了 GlusterFS 对元数据服务器的需求,消除了单点故障和 性能瓶颈,真正实现了并行化数据访问
2. 高可用性
GlusterFS 可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是 可以访问,甚至是在硬件故障的情况下也能正常访问。自我修复功能能够把数 据恢复到正确的状态,而且修复是以增量的方式在后台执行,几乎不会产生性 能负载。 GlusterFS 没有设计自己的私有数据文件格式,而是采用操作系统中主流标准 的磁盘文件系统(如EXT3 、 ZFS )来存储文件,因此数据可以使用各种标准工 具进行复制和访问。
3. 全局统一命名空间
全局统一命名空间将磁盘和内存资源聚集成一个单一的虚拟存储池,对上层 用户和应用屏蔽了底层的物理硬件。存储资源可以根据需要在虚拟存储池 中进行弹性扩展,比如扩容或收缩。当存储虚拟机映像时,存储的虚拟映像文 件没有数量限制,成千虚拟机均通过单一挂载点进行数据共享。虚拟机I/O 可在 命名空间内的所有服务器上自动进行负载均衡,消除了 SAN 环境中经常发生的 访问热点和性能瓶颈问题
4. 弹性哈希算法
GlusterFS 采用弹性哈希算法在存储池中定位数据,而不是采用集中式或分布式 元数据服务器索引。在其他的 Scale-Out 存储系统中,元数据服务器通常会导致 I/O 性能瓶颈和单点故障问题。GlusterFS 中,所有在 Scale-Out 存储配置中的存 储系统都可以智能地定位任意数据分片,不需要查看索引或者向其他服务器查 询。这种设计机制完全并行化了数据访问,实现了真正的线性性能扩展
5. 弹性卷管理
数据储存在逻辑卷中,逻辑卷可以从虚拟化的物理存储池进行独立逻辑划分而 得到。存储服务器可以在线进行增加和移除,不会导致应用中断。逻辑卷可以 在所有配置服务器中增长和缩减,可以在不同服务器迁移进行容量均衡,或者 增加和移除系统,这些操作都可在线进行。文件系统配置更改也可以实时在线 进行并应用,从而可以适应工作负载条件变化或在线性能调优
四.GFS技术特点
1. 完全软件实现
2. 完整的存储操作系堆栈
GlusterFS 不仅提供了一个分布式文件系统,而且还提供了许多其他重要的分 布式功能,比如分布式内存管理、 I/O 调度、软 RAID 和自我修复等。GlusterFS 汲取了微内核架构的经验教训,借鉴了GNU/Hurd 操作系统的设计思想,在用户 空间实现了完整的存储操作系统栈。
3. 用户空间实现
(User Space) GlusterFS 在用户空间实现,这使得其安装和升级特别简便。另外,这也极大 降低了普通用户基于源码修改 GlusterFS 的门槛,仅仅需要通用的 C程序设计技 能,而不需要特别的内核编程经验
4. 模块化堆栈式架构
GlusterFS 采用模块化、堆栈式的架构,可通过灵活的配置支持高度定制化的应 用环境,比如大文件存储、海量小文件存储、云存储、多传输协议应用等。每 个功能以模块形式实现,然后以积木方式进行简单的组合,即可实现复杂的功 能。比如 : Replicate 模块可实现 RAID1 , Stripe 模块可实现 RAID0 ,通过两者的组合可实 现 RAID10 和RAID01 ,同时获得高性能和高可靠性。
GFS 模块化堆栈式设计:
5. 原始数据格式存储
GlusterFS 以原始数据格式(如EXT3 、 EXT4 、 XFS 、 ZFS )储存数据,并实现多 种数据自动修复机制。因此,系统极具弹性,即使离线情形下文件也可以通过其 他标准工具进行访问。如果用户需要从 GlusterFS 中迁移数据,不需要作任何修改 仍然可以完全使用这些数据。
6. 无元数据服务设计
对 Scale-Out 存储系统而言,最大的挑战之一就是记录数据逻辑与物理位置的映 像关系,即数据元数据,可能还包括诸如属性和访问权限等信息。
传统分布式存储系统使用集中式或分布式元数据服务来维护元数据,集中式元数 据服务会导致单点故障和性能瓶颈问题,而分布式元数据服务存在性能负载和元 数据同步一致性问题。特别是对于海量小文件的应用,元数据问题是个非常大的 挑战。GlusterFS 独特地采用无元数据服务的设计,取而代之使用算法来定位文件, 元数据和数据没有分离而是一起存储。集群中的所有存储系统服务器都可以智能 地对文件数据分片进行定位,仅仅根据文件名和路径并运用算法即可,而不需要 查询索引或者其他服务器。这使得数据访问完全并行化,从而实现真正的线性性 能扩展。无元数据服务器极大提高了 GlusterFS 的性能、可靠性和稳定性。
7. Translators
Translators 是 GlusterFS 提供的一种强大文件系统功能扩展机制,这一设计思想 借鉴于GNU/Hurd 微内核操作系统。 GlusterFS 中所有的功能都通过 Translator 机制 实现,运行时以动态库方式进行加载,服务端和客户端相互兼容。
Translator :
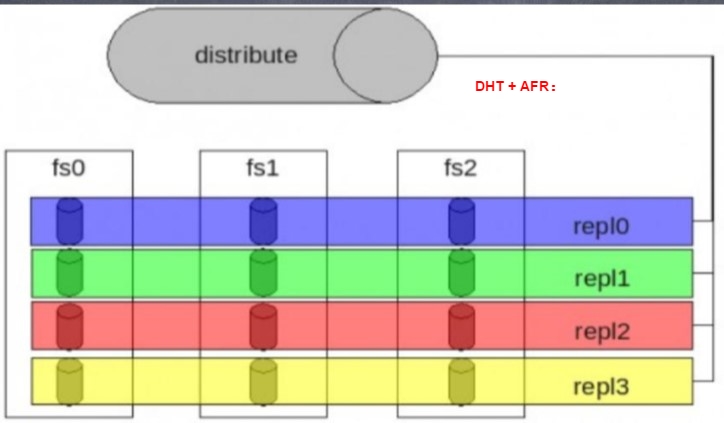
1. Clustet: 存储集群分布,目前有 AFR, DHT,Stripe 三种方式
2. Debug: 跟踪 GlusterFS 内部函数和系统调用
3. Encryption: 简单的数据加密实现
4. Features: 访问控制、锁、 Mac 兼容、静默、配额、只读、回收站等
5. Mgmt: 弹性卷管理
6. Mount:FUSE 接口实现
7. Nfs: 内部 NFS 服务器
8. Performance : io-cache, io-threads,quick-read, read-ahead, stat-prefetch,sysmlink-cache, writebehind 等性能优化
9. Protocol: 服务器和客户端协议实现
10.Storage: 底层文件系统 POSIX 接口实现
2.GFS Cluster Translators:
属于 GFS 集群存储核心 , 其包括 :
DHT(Distributed Hash Table)
AFR(Automatic File Replication)
Stripe
(1)DHT
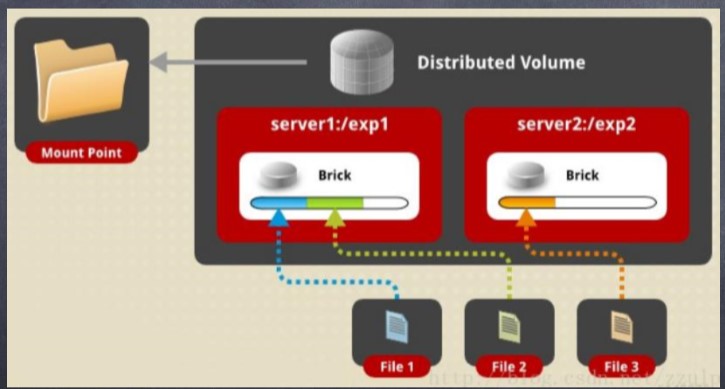
即上面所介绍的弹性哈希算法,它采用hash 方式进行数据分布,名字空 间分布在所有节点上。查找文件时,通过弹性哈希算法进行,不依赖名字空间。 但遍历文件目录时,则实现较为复杂和低效,需要搜索所有的存储节点。单一文 件只会调度到唯一的存储节点,一旦文件被定位后,读写模式相对简单。 DHT 不 具备容错能力,需要借助AFR 实现高可用性。
分布卷可以将某个文件随机的存储在卷内的一个brick(GFS 存储单元 ) 内,通常用 于扩展存储能力,不支持数据的冗余。除非底层的 brick 使用RAID 等外部的冗余措 施。
(2)AFR
相当于 RAID1 ,同一文件在多个存储节点上保留多份,主要用于实现高 可用性以及数据自动修复。 AFR 所有子卷上具有相同的名字空间,查找文件时从 第一个节点开始,直到搜索成功或最后节点搜索完毕。读数据时, AFR 会把所有 请求调度到所有存储节点,进行负载均衡以提高系统性能。写数据时,首先需要 在所有锁服务器上对文件加锁,默认第一个节点为锁服务器,可以指定多个。然 后, AFR 以日志事件方式对所有服务器进行写数据操作,成功后删除日志并解锁。 AFR 会自动检测并修复同一文件的数据不一致性,它使用更改日志来确定好的数 据副本。自动修复在文件目录首次访问时触发,如果是目录将在所有子卷上复制 正确数据,如果文件不存则创建,文件信息不匹配则修复,日志指示更新则进行 更新。
复本卷在创建时可指定复本的数量,复本在存储时会在卷的不同 brick 上,因此有 几个复本就必须提供至少多个 brick
此类型卷是基本复本卷的扩展,可以指定若干brick 组成一个复本卷,另外若干 brick 组成另个复本卷。单个文件在复本卷内数据保持复制,不同文件在不同复本 卷之间进行分布。复本卷的组成依赖于指定 brick 的顺序brick 必须为复本数 K 的 N 倍 ,brick 列表将以 K个为一组,形成 N 个复本卷。
注意:在创建复本卷时, brick 数量与复本个数必须相等;否则将会报错。 另外如果同一个节点提供了多个 brick ,也可以在同一个结点上创建复本卷,但这 并不安全,因为一台设备挂掉,其上面的所有 brick 将无法访问。
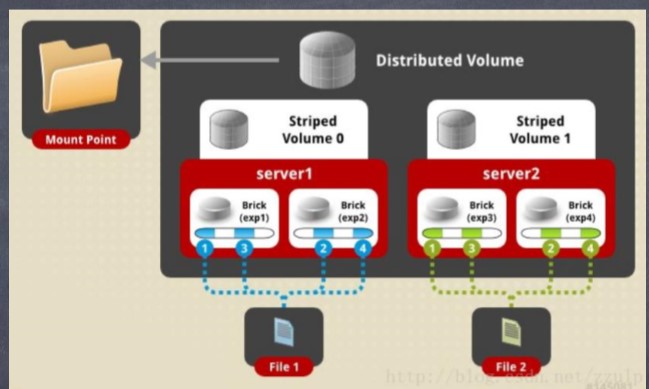
(3)Stripe
相当于 RAID0 ,即分片存储,文件被划分成固定长度的数据分片以 Round-Robin 轮转方式存储在所有存储节点。 Stripe 所有存储节点组成完整的名字 空间,查找文件时需要询问所有节点,这点非常低效。读写数据时, Stripe 涉及 全部分片存储节点,操作可以在多个节点之间并发执行,性能非常高。 Stripe 通 常与 AFR 组合使用,构成 RAID10/RAID01 ,同时获得高性能和高可用性,当然存 储利用率会低于 50%
分片卷将单个文件分成小块 ( 块大小支持配置 ,默认为 128K) ,然后将小块存储在 不同的 brick上,以提升文件的访问性能。 注意: brick 的个数必须等于分布位置的个数
(1)Distribute+Striped
类似于分布式复本卷,若创 建的卷的节点提供的bricks 个数为 stripe 个数 N 倍时, 将创建此类型的卷
注意:切片卷的组成依赖于指定 brick 的顺序brick 必须为复本数 K 的 N 倍 ,brick 列 表将以 K个为一组,形成 N 个切片卷
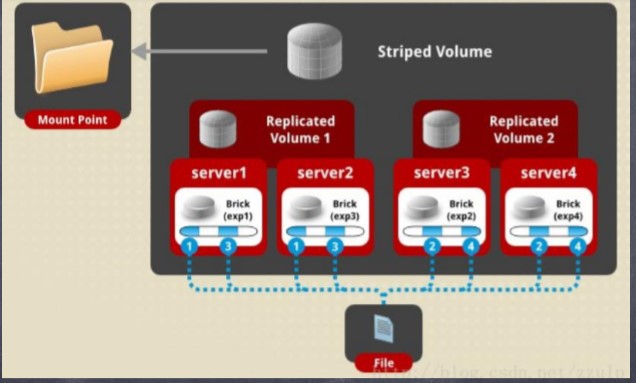
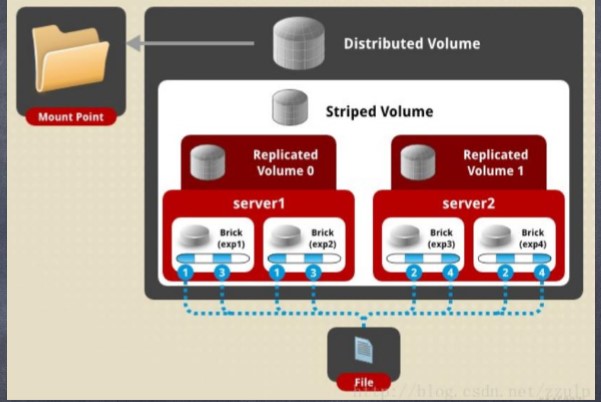
(2)Striped+Replicated
数据将进行切片,切片在复 本卷内进行复制,在不同卷 间进行分布。 exp1 和 exp2 组成复本卷,exp3 和 exp4 组 成复本卷,两个复本卷组成 分片卷。
注意: brick 数量必须和 stripe 个数 N 和 repl参数 M 的积 N*M 相等。即对于 brick 列表,将以M 为一组,形成 N 个切片卷。数据切片分布在 N个切片卷上,在每个 切片卷内部,切片数据副本M份
(3)Distribute+Striped+Replicated:
注意: bricks 数量为 stripe 个数 N , 和 repl个数 M 的积 N*M 的整数倍。 exp1 exp2 exp3 exp4 组成一个分布 卷, exp1 和 exp2 组成一个 stripe 卷, exp3 和exp4 组成另一个 stripe 卷, 1 和 2 , 3 和 4 互为复本卷。
3.GFS 术语
1.Brick:GFS 中的存储单元,通过是一个受信存储池中的服务器的一个导出目录。 可以通过主机名和目录名来标识,如 'SERVER:EXPORT'
2.Client: 挂载了 GFS 卷的设备
3.Extended Attributes:xattr 是一个文件系统的特性,其支持用户或程序关联文件 / 目录和元数据。
4.FUSE:Filesystem Userspace 是一个可加载的内核模块,其支持非特权用户创建 自己的文件系统而不需要修改内核代码。通过在用户空间运行文件系统的代码 通过 FUSE 代码与内核进行桥接
5.GFID:GFS 卷中的每个文件或目录都有一个唯一的 128 位的数据相关联,其用于 模拟 inode
6.Namespace: 每个 Gluster 卷都导出单个 ns作为 POSIX 的挂载点
7. Node: 一个拥有若干 brick 的设备
8. RDMA: 远程直接内存访问,支持不通过双方的OS 进行直接内存访问
9.RRDNS:round robin DNS 是一种通过 DNS 轮转返回不同的设备以进行负载均衡的 方法
10. Self-heal: 用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致。
11.Translator:
①Volfile: glusterfs 进程的配置文件,通常位于 /var/lib/glusterd/vols/volname
② Volume: 一组 bricks 的逻辑集合
五.储存方案——ceph
1.CEph 简介
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系 统。ceph 的统一体现在可以提供文件系统、块存储和对象存储,分布式体现在可 以动态扩展。在国内一些公司的云环境中,通常会采用 ceph 作为openstack 的唯 一后端存储来提高数据转发效率。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表), 并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商 的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后 端存储。
官网:https://ceph.com/
官方文档:http://docs.ceph.com/docs/master/#
2. Ceph 特点
1.高性能
① 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡, 并行度高。
②考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架 感知等
③能够支持上千个存储节点的规模,支持TB到PB级的数据
2.高可用性
①副本数可以灵活控制
②支持故障域分隔,数据强一致性。
③多种故障场景自动进行修复自愈。
④没有单点故障,自动管理
3.高可扩展性
①去中心化。
②扩展灵活。
③ 随着节点增加而线性增长。
4.特性丰富
①支持三种存储接口:块存储、文件存储、对象存储。
②支持自定义接口,支持多种语言驱动。
3.Ceph 应用场景:
Ceph可以提供对象存储、块设备存储和文件系统服务,其对象存储可以对接网盘 (owncloud)应用业务等;其块设备存储可以对接(IaaS),当前主流的IaaS运平 台软件,如:OpenStack、CloudStack、Zstack、Eucalyptus等以及kvm等。
Ceph是一个高性能、可扩容的分布式存储系统,它提供三大功能:
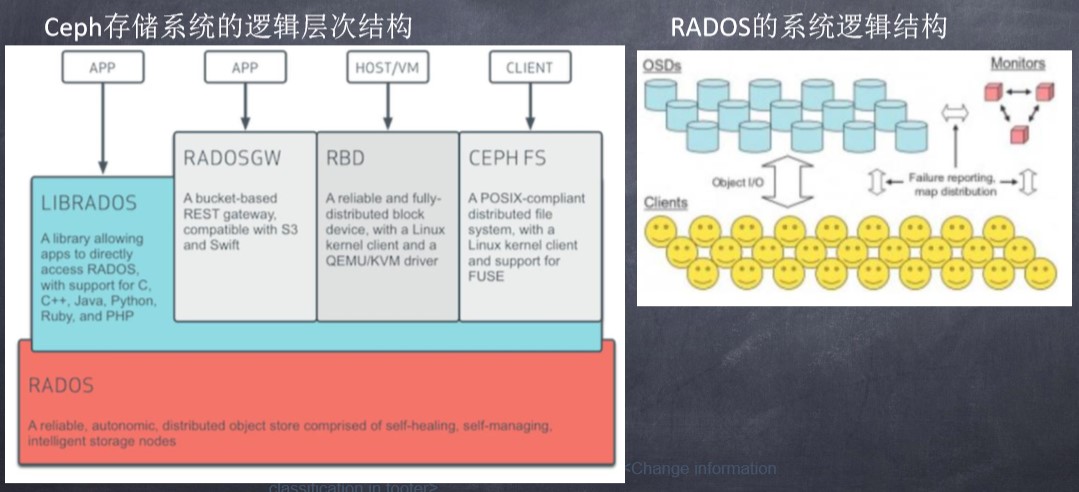
① 对象存储(RADOSGW): 提供RESTful接口,也是提供多种编程语言绑定。兼容S3,Swift
② 块存储(RDB):由RBD提供,可以直接作为磁盘挂载,内置了容灾机制;
③文件系统(CephFS):提供POSIX兼容的网络文件系统CephFS,专注于高性能、 大容量存储;
4.什么是块存储/对象存储/文件系统存储?
1.对象存储:
也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL 和其他扩展,代表主要有 Swift 、S3 以及 Gluster 等;
2.块存储:
这种接口通常以 QEMU Driver 或者 Kernel Module 的方式存在,这种接口需要实现 Linux 的 Block Device 的接口或者 QEMU 提供的 Block Driver 接口,如 Sheepdog,AWS 的 EBS,青云的云 硬盘和阿里云的盘古系统,还有 Ceph 的 RBD(RBD是Ceph面向块存储的接口)。在常见的存储 中 DAS、SAN 提供的也是块存储;
3.文件系统存储:
通常意义是支持 POSIX 接口,它跟传统的文件系统如 Ext4 是一个类型的,但区别在于分布式 存储提供了并行化的能力,如 Ceph 的 CephFS (CephFS是Ceph面向文件存储的接口),但是有时 候又会把 GlusterFS ,HDFS 这种非POSIX接口的类文件存储接口归入此类。当然 NFS、NAS也是 属于文件系统存储;
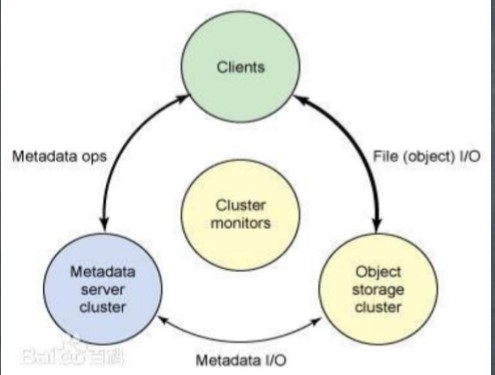
5.Ceph 核心组件:
(1)Monitors:监视器,维护集群状态的多种 映射,同时提供认证和日志记录服务,包括有关 monitor 节点端到端的信息,其中包括 Ceph 集群 ID,监控主机名和IP以及端口。并且存储当前版 本信息以及最新更改信息,通过 "ceph mon dump" 查看 monitor map
(2)MDS(Metadata Server):Ceph 元数据,主 要保存的是Ceph文件系统的元数据。注意:ceph 的块存储和ceph对象存储都不需要MDS
(3)OSD:即对象存储守护程序,但是它并非针对对象存储。是物理磁盘驱动器, 将数据以对象的形式存储到集群中的每个节点的物理磁盘上。OSD负责存储数据、 处理数据复制、恢复、回填(Backfilling)、再平衡。完成存储数据的工作绝大多 数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs 文件系统来格式化分区。此外OSD还对其它OSD进行心跳检测,检测结果汇报给 Monitor
(4)RADOS:Reliable Autonomic Distributed Object Store。RADOS是ceph存储集群 的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型, RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。
(5)librados:librados库,为应用程度提供访问接口。同时也为块存储、对象存储、 文件系统提供原生的接口。
(6)RADOSGW:网关接口,提供对象存储服务。它使用librgw和librados来实现允 许应用程序与Ceph对象存储建立连接。并且提供S3 和 Swift 兼容的RESTful API接口
(7)RBD:块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在 多个OSD上。
(8)CephFS:Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接 口。
Ceph存储系统的逻辑层次结构
Ceph 数据存储过程:
6.Ceph 数据存储过程:
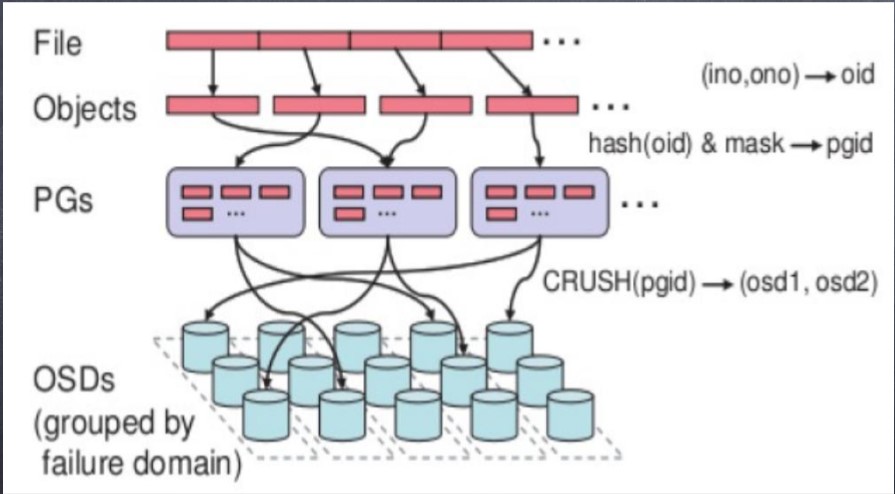
无论使用哪种存储方式(对象、块、文件系统),存储的数据都会被切分成 Objects。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一 个唯一的OID,由ino与ono生成,虽然这些名词看上去很复杂,其实相当简单。
ino:即是文件的File ID,用于在全局唯一标识每一个文件
ono:则是分片的编号
比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1, 那么这两个文件的oid则为A0与A1。
File —— 此处的file就是用户需要存储或者访问的文件。对于一个基于Ceph开发的对 象存储应用而言,这个file也就对应于应用中的“对象”,也就是用户直接操作的 “对象”。
Ojbect —— 此处的object是RADOS所看到的“对象”。Object与上面提到的file的区 别是,object的最大size由RADOS限定(通常为2MB或4MB),以便实现底层存储的 组织管理。因此,当上层应用向RADOS存入size很大的file时,需要将file切分成统一 大小的一系列object(最后一个的大小可以不同)进行存储。为避免混淆,在本文 中将尽量避免使用中文的“对象”这一名词,而直接使用file或object进行说明
PG(Placement Group)—— 顾名思义,PG的用途是对object的存储进行组织和位 置映射。具体而言,一个PG负责组织若干个object(可以为数千个甚至更多),但 一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。 同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和 OSD之间是“多对多”映射关系。在实践当中,n至少为2,如果用于生产环境,则 至少为3。一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分 布的均匀性问题。关于这一点,下文还将有所展开。
OSD —— 即object storage device,前文已经详细介绍,此处不再展开。唯一需要说 明的是,OSD的数量事实上也关系到系统的数据分布均匀性,因此其数量不应太少。 在实践当中,至少也应该是数十上百个的量级才有助于Ceph系统的设计发挥其应有 的优势。
Ceph 数据存储过程: 基于上述定义,便可以对寻址流程进行解释了。具体而言, Ceph中的寻址至少 要经历以下三次映射:
(1)File -> object映射
(2)Object -> PG映射,hash(oid) & mask -> pgid
(3)PG -> OSD映射,CRUSH算法
CRUSH,Controlled Replication Under Scalable Hashing,它表示数据存储的分布式选 择算法, ceph 的高性能/高可用就是采用这种算法实现。CRUSH 算法取代了在元数 据表中为每个客户端请求进行查找,它通过计算系统中数据应该被写入或读出的位 置。CRUSH能够感知基础架构,能够理解基础设施各个部件之间的关系。并CRUSH 保存数据的多个副本,这样即使一个故障域的几个组件都出现故障,数据依然可用
CRUSH 算是是的ceph实现了自我管理和自我修复。
RADOS 分布式存储相较于传统分布式存储的优势在于:
1. 将文件映射到object后,利用Cluster Map 通过CRUSH 计算而不是查找表方式 定位文件数据存储到存储设备的具体位置。优化了传统文件到块的映射和Block MAp的管理。
2. RADOS充分利用OSD的智能特点,将部分任务授权给OSD,最大程度地实现 可扩展
Ceph IO流程及数据分布:
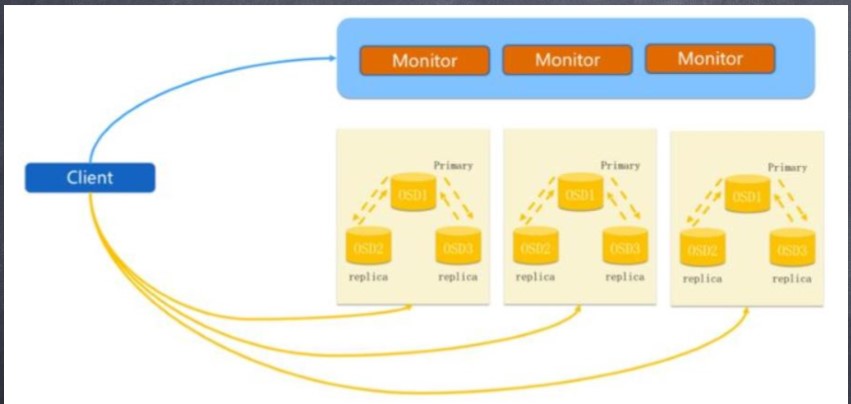
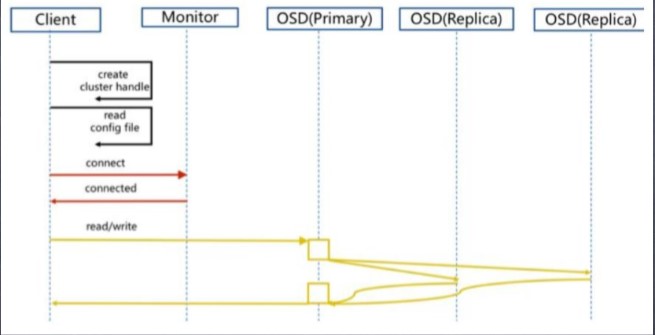
5.Ceph 正常IO 流程图
1. client 创建cluster handler。
2. client 读取配置文件。
3. client 连接上monitor,获取集 群map信息。
4. client 读写io 根据crshmap 算 法请求对应的主osd数据节点。
5. 主osd数据节点同时写入另外两个副本节点数据。
6. 等待主节点以及另外两个副本节点写完数据状态。
7. 主节点及副本节点写入状态都成功后,返回给client,io写入完成
新主IO流程图:
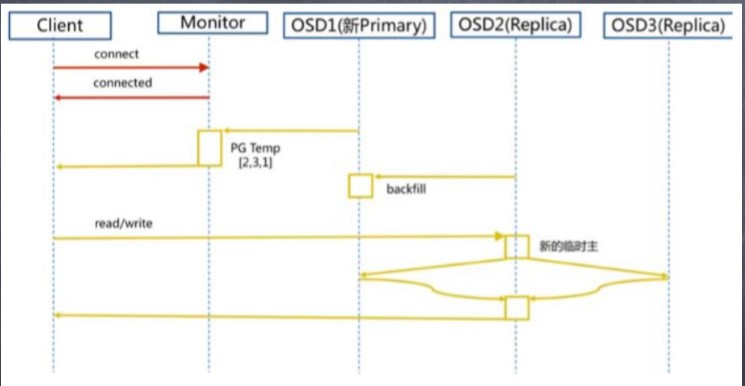
说明:如果新加入的OSD1取代了原有的 OSD4成为 Primary OSD, 由于 OSD1 上未创 建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,怎样工作的呢?
新主IO流程步骤:
1. client连接monitor获取集群map信息。
2. 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
3. 临时主osd2会把数据全量同步给新主osd1。
4. client IO读写直接连接临时主osd2进行读写。
5. osd2收到读写io,同时写入另外两副本节点。
6. 等待osd2以及另外两副本写入成功。
7. osd2三份数据都写入成功返回给client, 此时client io读写完毕。
8. 如果osd1数据同步完毕,临时主osd2会交出主角色。
9. osd1成为主节点,osd2变成副本。
6.Ceph Pool 和PG 分布情况:
1.pool:是ceph存储数据时的 逻辑分区,它起到 namespace的作用。
2.每个pool包含一定数量(可配置) 的PG。
3.PG里的对象被映射到不同的Object上。
4.pool是分布到整个集群的。
5.pool可以做故障隔离域,根据不同的用户场景不一进行隔离
六.GFS-cluster 部署与实践
1.前期准备
1)条件:准备3台linux系统,确认 DNS 能够解析各node或在/etc/hosts配置各node 的FQDN、IP、别名
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.60 con1
192.168.10.61 con2
192.168.10.62 con3
(2)配置yum源:
yum -y install centos-release-gluster40
2. 部署环境:
1)所有server节点建立操作,安装GFS SERVER
yum install glusterfs-server -y
(2)所有server节点开启 GFS 服务
systemctl start glusterd
systemctl enable glusterd
3.GFS实践
①实现GFS之 Distrbuted
(1)建立 GlusterFS 卷所需要的目录
mkdir -pv /gfs/dist
(2)将 node 加入至 gfs 集群组中
gluster peer probe con2
gluster peer probe con3
(3)确认集群组状态
gluster peer status
(4) 创建 Distributed Volume
gluster volume create vol_dist transport tcp
con1:/gfs/dist
con2:/gfs/dist
con3:/gfs/dist force
(5)启动卷
gluster volume start dist
(6)查看卷信息
gluster volume info
(7)客户端配置
安装软件包:
yum install glusterfs glusterfs-fuse -y
创建挂着目录:
mkdir -pv /mnt/gfs/dist
挂载共享存储:
mount -t glusterfs con1:/vol_dist /mnt/gfs/dist/
查看挂载情况,并复制或创建文件进行测试:
df -hT
②实现 GFS 之 Replication
(1)建立 GlusterFS 卷所需要的目录
mkdir -pv /gfs/replica
(2)将 node2 node3 加入至 gfs 集群组中
gluster peer probe con2
gluster peer probe con3
(3)确认集群组状态
gluster peer status
(4)创建 Replication Volume
gluster volume create vol_replica replica 3 transport tcp
con1:/gfs/replica
con2:/gfs/replica
con3:/gfs/replica force
(5)启动并查看卷信息
gluster volume start vol_replica
gluster volume info
(6)客户端配置
安装软件包:
yum install glusterfs glusterfs-fuse -y
创建挂着目录:
mkdir -pv /mnt/gfs/replica
挂载共享存储:
mount -t glusterfs con1:/vol_replica /mnt/gfs/replica
查看挂载情况,并复制或创建文件进行测试
df -hT
③实现 GFS 之 Striping
(1)建立 GlusterFS 卷所需要的目录
mkdir -pv /gfs/spriped
(2)将 node2 node3 加入至 gfs 集群组中
gluster peer probe con2
gluster peer probe con3
(3)确认集群组状态
gluster peer status
(4)创建 Striping Volume
gluster volume create vol_spriped stripe 3 transport tcp
con1:/gfs/spriped
con2:/gfs/spriped
con3:/gfs/spriped force
(5)启动并查看卷信息
gluster volume start vol_spriped
gluster volume info
(6)客户端配置
安装软件包:
yum install glusterfs glusterfs-fuse -y
创建挂着目录:
mkdir -pv /mnt/gfs/striping
挂载共享存储:
mount -t glusterfs con1:/vol_spriped /mnt/gfs/striping
查看挂载情况,并复制或创建文件进行测试
df -hT
④实现 GFS 之 Dist+Replica
(1)建立 GlusterFS 卷所需要的目录
mkdir -pv /gfs/dr
(2)将 node2 node3 node4 加入至 gfs 集群组中
gluster peer probe con2
gluster peer probe con3
gluster peer probe con4
(3)确认集群组状态
gluster peer status
(4)创建 Dist+Replica Volume
gluster volume create vol_dr replica 2 transport tcp
con1:/gfs/dr
con2:/gfs/dr
con3:/gfs/dr
con4:/gfs/dr force
(5)启动并查看卷信息
gluster volume start vol_dr
gluster volume info
(6)客户端配置
安装软件包:
yum install glusterfs glusterfs-fuse -y
创建挂着目录:
mkdir -pv /mnt/gfs/dr
挂载共享存储:
mount -t glusterfs con1:/vol_dr /mnt/gfs/dr
查看挂载情况,并复制或创建文件进行测试:
df -hT
⑤实现 GFS 之 Stripe+Replica
(1)建立 GlusterFS 卷所需要的目录
mkdir -pv /gfs/sr
(2)将 node2 node3 node4 加入至 gfs 集群组中
gluster peer probe con2
gluster peer probe con3
gluster peer probe con4
(3)确认集群组状态
gluster peer status
(4)创建 Stripe+Replica Volume
gluster volume create vol_sr stripe 2 replica 2 transport tcp
con1:/gfs/sr
con2:/gfs/sr
con3:/gfs/sr
con4:/gfs/sr force
(5)启动并查看卷信息
gluster volume start vol_sr
gluster volume info
(6)客户端配置
安装软件包:
yum install glusterfs glusterfs-fuse -y
创建挂着目录:
mkdir -pv /mnt/gfs/sr
挂载共享存储:
mount -t glusterfs con1:/vol_sr /mnt/gfs/sr
查看挂载情况,并复制或创建文件进行测试
df -hT
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">