值拷贝:使用的最多
ls = [1, 'abc', [10]]
ls1 = ls # ls1直接将ls中存放的地址拿过来
# ls内部的值发生任何变化,ls1都会随之变化,相当于是两个赋值在一个变量上。

ls2 = ls.copy() # 新开辟列表空间,但列表中的地址都是直接从ls列表中拿来
# ls内部的可变类型值发生改变,ls2会随之变化。ls2和ls1的值相等id不等
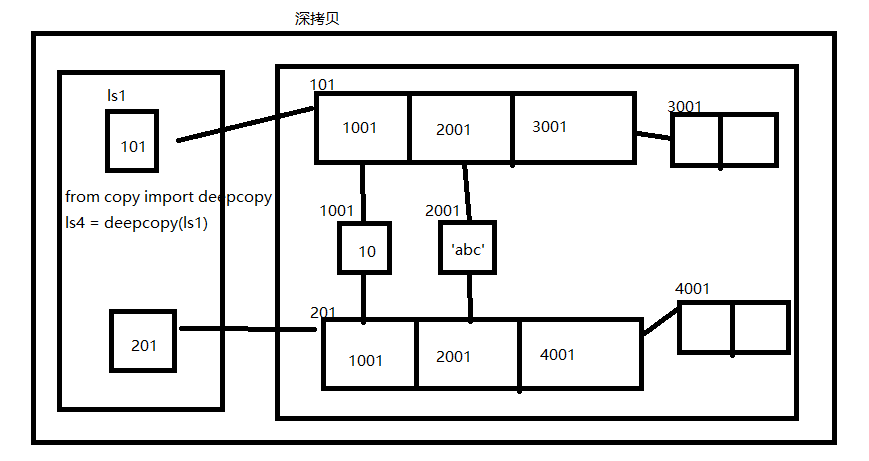
ls3 = deepcopy(ls) # 新开辟列表空间,ls列表中的不可变类型的地址直接拿过来,但是可变类型的地址一定重新开辟空间。
# ls内部的所有类型的值发生改变,ls3都不会随之变化
'''
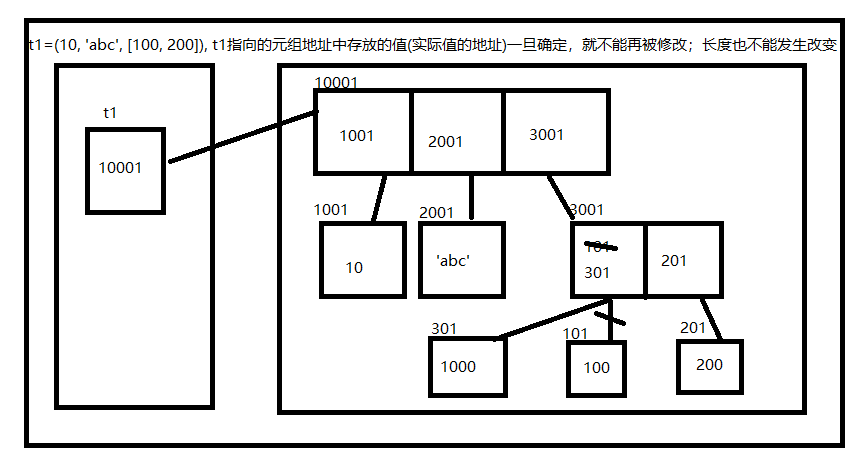
元组:可以理解为不可变的列表
# 1.值可以为任意类型
# 2.可以存放多个值 - 可以进行成员运算
# 3.可以存放重复的值 - 可以计算成员出现的次数
# 4.有序存储 - 可以通过索引取值,可以切片
'''
# 常用操作
# 1.索引取值
print(t1[1], type(t1[1]))
print(t1[-3])
# 2.运算(拼接)
print((1, 2) + (2, 3))
# 3.长度
print(len(t1))
# 4.切片
print((2, 1, 3)[::-1])
# 5.成员运算
print(True in t1)
print(False in t1) # False == 0, t1中如果有0或False,该结果都是True
# 6.for循环
for obj in t1:
print(obj, end=" ")
print()
# 方法
print(t1.count(0)) # 对象0在元组中出现的次数
print(t1.index(123, 4, len(t1))) # 对象0在区间4~末尾第一次出现的索引
# 容器(集合):存放多个值的变量
# 单列容器(系统中的单列容器很多):list | tuple
# 双列容器(map):只有dict,存放数据 成对出现,dict存放数据采用 key-value键值对方式
# 字典中的key可以为什么类型:key必须为不可变类型
# -- key是取value的唯一依据,key一旦被确定,就需要唯一确定(不能被改变)
# 字典中的value可以为什么类型:value可以为任意类型
# -- value是用来存放世间所有存在的数据
# key要确保唯一性,不能重复,值可以重复,并且可以被改变 => 字典为可变类型
dic = {'a': 10, 1: 20, True: 30, (): 40} # 1和True都是1,key具有唯一性,所以只保留最后一次值
print(dic) # {'a': 10, 1: 30, (): 40}
# 空字典
d1 = {}
d2 = dict()
# 用map映射创建字典
d3 = dict({'a': 1, 'b': 1})
print(d3)
# 用关键字赋值方式
d4 = dict(name='Bob', age=18) # 参数=左侧的名字就是合法的变量名,都会被转化为字符串形式的key
print(d4)
# 创建有多个key值采用默认值的方式: 默认值不写默认None,也可以自定义
d5 = {}.fromkeys('abc', 0)
print(d5)
dic = {'a': 1, 'b': 2}
print(dic)
# 增: 字典名[key] = 值 => key已存在就是修改值,不存在就是新增值
dic['c'] = 3
print(dic)
# 改
dic['c'] = 30
print(dic)
# 查:字典名[key]
print(dic['c']) # 只能查找已有的key,没有崩溃
# 有默认值的查询:有key取出对应value,没有返还默认值,默认值可以自定义
print(dic.get('d', 'http://www.baidu.com'))
# 删
print(dic)
# 清空
# dic.clear()
# pop(k)删除指定key的value并返还删除的value
# res = dic.pop('a')
# 从dic末尾删除,返还(key, value)形成的元组
res = dic.popitem()
print(dic, res)
# 其他方法
# 更新: a有值覆盖,c没被新操作,带下来,b为新增,增加并赋值
dic = {'a': 1, 'c': 2}
d = {'a': 10, 'b': 20}
dic.update(d)
print(dic) # {'a': 10, 'c': 2, 'b': 20}
# 带默认值的新增: 新增key,key已有,啥事不干,没有添加key,值就是第二个参数
dic.setdefault('z', 100)
print(dic)
# 字典的循环
# 1.直接循环,就是循环得到key
# for k in dic:
# print(k)
# 2.循环keys
# print(dic.keys())
# for k in dic.keys():
# print(k)
# 3.循环values
# print(dic.values())
# for v in dic.values():
# print(v)
# 同时循环key和value (key, value)
print(dic.items())
# a, b = (1, 2)
# print(a, b)
# for res in dic.items():
# print(res)
# 重点
for k, v in dic.items():
print(k, v)
# 解压赋值
# a, _, _, b = (1, 2, 3, 4)
# 空集合:不能用{},因为用来标示空字典
s = set()
print(s, type(s))
# 概念:
# 1.set为可变类型 - 可增可删
# 2.set为去重存储 - set中不能存放重复数据
# 3.set为无序存储 - 不能索引取值
# 4.set为单列容器 - 没有取值的key
# 总结:set不能取值
# 增
s.add('1')
s.add('2')
s.add('1')
print(s)
s.update({'2', '3'})
print(s)
# 删
# res = s.pop()
# print(res)
# s.remove('1')
# print(s)
s.clear()
print(s)
# set运算
# 交集:两个都有 &
py = {'a', 'b', 'c', 'egon'}
lx = {'x', 'y', 'z', 'egon'}
print(py & lx)
print(py.intersection(lx))
# 合集:两个的合体 |
print(py | lx)
print(py.union(lx))
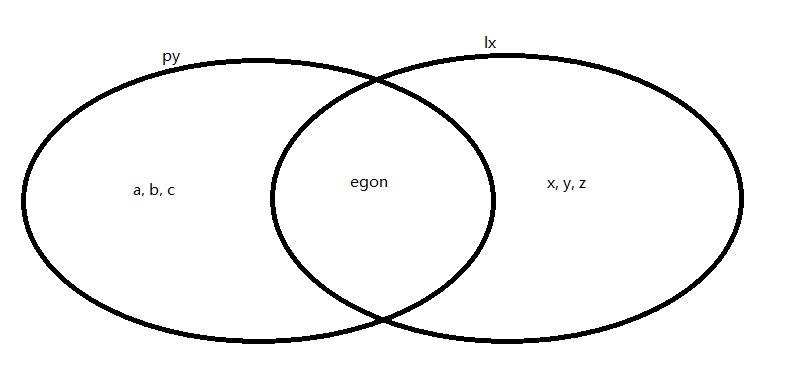
# 对称交集:抛出共有的办法的合体 ^
print(py ^ lx)
print(py.symmetric_difference(lx))
# 差集:独有的
print(py - lx)
print(py.difference(lx))
# 比较:前提一定是包含关系
s1 = {'1', '2'}
s2 = {'2'}
print(s1 < s2)